Welcome to this concise article discussing how to install Linux headers on Kali Linux.
Linux header files are used in interface definition between various components of the kernel. They are also used to define interfaces between the kernel and userspace. A typical case where Linux headers are required is running a Hypervisor because the tools require modules that interact with the kernel.
By default, Kali Linux does not ship with Linux headers installed; you will have to do it manually.
Installing Linux Headers Using APT
One of the methods you can use to install Kernel Headers is to use the Debian package manager with Kali Linux repositories.
You may require to run a full system upgrade before installing the Kernel Headers successfully.
Edit your sources.list file, and add the correct repositories provided in the following resource,
https://www.kali.org/docs/general-use/kali-linux-sources-list-repositories/
Next, refresh the repositories and run a full distribution upgrade
sudo apt-get dist-upgrade
Once completed, reboot your Kali Linux installation, and install the headers.
Enter the command below to install Linux headers for your kernel version. We will use the uname –r command to grab the kernel version directly.
This command should run successfully and install the required headers for your Kernel version. However, if the method above does not work, you can install them manually.
Installing Kernel Headers Manually
Before installing the Kernel headers manually, run a full distribution update and reboot to ensure you have the latest kernel version.
sudo apt-get dist-upgrade
Open your browser and navigate to
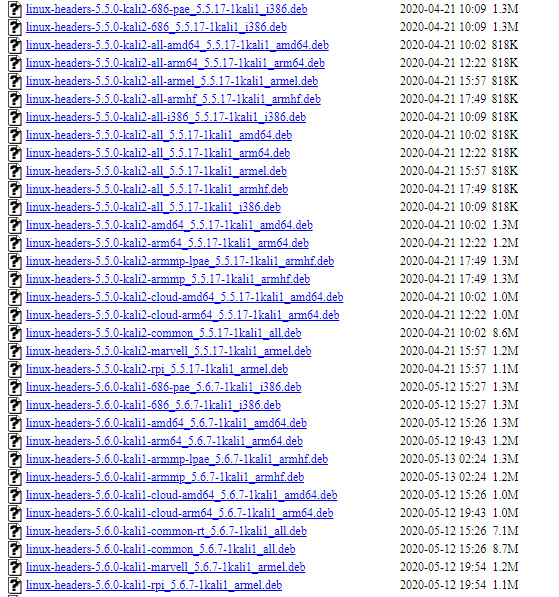
https://http.kali.org/kali/pool/main/l/linux/
Download the appropriate kernel headers you require in the form of a deb package.
Next, use the dpkg command to install the headers:
That should install the required Kernel headers.
Conclusion
This tutorial has shown you the manual way of installing Kernel headers on Kali Linux and using the apt package manager.
NOTE: To ensure you don’t run into issues, update your system before performing header installation.
Thank you for reading.
]]>As developers, we are no strangers to managing and saving various copies of code before joining it to the main code.
Let’s discuss a better and efficient way to manage various code versions and merge them with the main code after testing.
Let’s dive in:
Introduction To Version Control Systems
We have mentioned that Git is a version control system. What exactly is a version control system, and how does it work?
A version control system is a system that allows developers to track file changes. Version control systems work by creating collections of various versions of files and the changes made to each version. They allow you to switch between various versions of the files seamlessly.
A version control system stores a collection of file changes in a location called a repository.
In most use cases, version control systems help track changes in source code files as they contain raw text. However, version control systems are not limited to text files; they can track even changes in binary data.
Types of Version Control Systems
There are various types of version control systems. They include:
- Localized Version control systems: This type of version control system works by storing various versions of the files locally by creating copies of the file changes.
- Centralized version control system: Centralized version control system includes a central server with various file versions. However, the developer still retains a copy of the file on their local computer
- Distributed Version control system: Distributed version control system does not require a server. However, it involves each developer cloning a copy of the main repository, and you have access to changes of all the files. Popular distributed VC systems are Git, Bazaar, and Mercurial.
Let us get started with Git.
Introduction to Git
Git is a distributed version control system developed by Linus Torvalds, the creator of the Linux Kernel. Initially developed to assist in developing the Linux Kernel, Git is powerful and easy to use. It supports linear development, which allows more than one developer to work on the same project concomitantly.
Let discuss how to install Git and use it to manage repositories:
How to Install Git on Linux
Depending on the system you are using, you will have Git installed by default. However, some systems may not have it installed. If that’s your case, use the following commands to install it on your system.
Debian/Ubuntu
Arch Linux
Install Git on Arch:
Fedora/RedHat/CentOS
Install on RHEL family:
sudo dnf install git
How to Configure Git
Once you install Git, you will get access to all its commands that you can use to work with local and remote repositories.
However, you need to configure it for first-time use. We will use the git config to set various variables.
The first config we set is the username and email address. Use the git config command shown to set the username, email address, and the default text editor.
git config --global core.editor vim
You can view the git configurations by using the git config –list command as:
user.name=myusername
user.email=username@email.com
core.editor=vim
How to Set up Repositories
We cannot mention Git and fail to mention the term repo or repository.
A repository, commonly called a repo, collects files and directories with their respective changes tracked by the version control system.
Changes in a repository are managed or tracked by commits, which are simple snapshots of changes applied to a file or directory.
Commits allow you to apply the changes or revert to a specific change within the repository.
Let’s now discuss how to set up a Git repository.
Suppose you have a project directory you would like to use as a git repo and track changes. You can initialize it using the command:
Once you run the git init command, Git initializes the directory as a repository and creates a .git directory used to store all the configuration files.
To start tracking changes using Git, you have to add it using the Git add command. For example, to add the file, reboot.c
To add all the files in that directory and start tracking changes, use the command:
After adding files, the next step is to stage a commit. As mentioned earlier, commits help track the changes to files in a repository.
Using the git commit command, you can add the message indicating the changes to the files.
For example, a message for the initial commit would be similar to:
NOTE: Adding descriptive and meaningful git messages helps other users using the repository identify file changes.
gitignore
Suppose you have some files and directories you do not wish to include in the main repository. For example, you may have configuration files for the development you are using.
To accomplish this, you need to use the .gitignore file. In the .gitignore file, you can add all files and directories that Git should not track.
An example of the .gitignore file typically looks like this:
node_modules/
tmp/
*.log
*.zip
.idea/
yarn.lock package-lock.json
.tmp*
Git Remote Repositories
Git is a powerful system that extends outside the scope of local repositories. Services such as GitHub, Bitbucket, and Gitlab offer remote repositories where developers can host and collaborate on projects using git repos.
Although some remote git services are premium—there’re many free services available—, they offer great tools and functionalities such as pull requests and many others that ensure smooth development.
NOTE: You can also build a self-hosted git service. Check our Gogs tutorial to learn how to accomplish this.
Let us now look at various ways to work with remote repositories.
Cloning a remote repository
A popular way to work with remote repositories is copying all the files in a remote repo to a local repo; a process called cloning.
To do this, use the git clone command followed by the URL of the repository as:
In services such as Github, you can download the zipped repository under the Download option.
To view the status of the files in the repository, use the git status command:
This command will tell you if the files in the repository have changed.
Update local repo from remote
If you have a cloned repository, you can get all the changes from the remote repository and merge them to the local one with Git fetch command:
Creating a new remote repository
To create a remote repository from the command line, use the git remote add command as:
Pushing local repo to remote
To push all changes from a local repository to a remote repository, you can use the git push command followed by the remote repository’s URL or name. First, ensure you have added the files, added a commit message as:
git commit -m “Added new function to shutdown. “ git push origin https://github.com/linuxhint/code.git
Deleting a remote repository
If you want to delete a remote repository from the command line, use the git remote rm command as:
Conclusion
We have covered the basics of setting up a Git version control system and how to use it to work with local and remote repositories.
This beginner-friendly guide is by no means a full-fledged reference material. Consider the documentation as there are a lot of features not covered in this tutorial.
]]>WireGuard is a simple and fast open-source VPN tunneling service built with high-end cryptographic technologies. It is very easy to set up and use, and many consider it better than OpenVPN or IPSec. WireGuard is also cross-platform and supports embedded devices.
WireGuard works by setting up virtual network interfaces such as wlan0 or eth0 that can be managed and controlled like normal network interfaces, helping configure and manage the WireGuard easily using net-tools and other network managing tools.
This guide will show you how to set up a WireGuard client and server on a Kali Linux system.
Let us start by installing WireGuard on the system.
Installing WireGuard
Depending on the version of Kali Linux you are running, you should have WireGuard apt repositories. Update your system using the commands:
sudo apt-get upgrade
Next, enter a simple apt command to install WireGuard:
Once we have WireGuard installed on the system, we can proceed to configure it.
Configuring WireGuard Server
WireGuard security operates on SSH key-value pairs, which are very easy to configure. Start by creating a .wireguard directory.
cd ~/.wireguard
Next, set read, write, and execute permissions.
Now we can generate the key-value pairs using the command:
Next, copy the contents of the private key:
Once you have the contents of the private key copied to your clipboard, create a WireGuard configuration file in /etc/wireguard/wg0.conf
In the file, add the following lines:
Address = SERVER_IP
SaveConfig = true
ListenPort = 51820
PrivateKey = SERVER_PRIVATE_KEY
[Peer]
PublicKey = CLIENT_PUBLIC_KEY
AllowedIPs = CLIENT_IP
In the address, add the IP address of the hosting server. For PrivateKey, enter the contents of the private key you copied previously.
In the peer section, add the public key for the client and the IP address.
Once you have the configuration file set up, set the VPN server to launch at startup.
Finally, start the WireGuard service on the server:
Configuring WireGuard Client
Next, we need to configure the WireGuard client. Ensure you have WireGuard installed on the system.
Generate Key value pairs as well.
umask u=rwx,go= && cat /etc/wireguard/wg0.conf << EOF
[Interface]
Address = CLIENT_IP
PrivateKey = CLIENT PRIVATE KEY
[Peer]
PublicKey = SERVER PUBLIC KEY
Endpoint = SERVER_IP:51820
AllowedIPs = 0.0.0.0/0
PersistentKeepalive = 21
EOF
Finally, save the file and enable the VPN:
You can verify the connection with the command:
Conclusion
Setting up WireGuard is easy and efficient. Once set up, you can use it in a wide variety of cases. With what you’ve learned from this guide, you can test and see if it works better than other VPN services.
]]>OpenVPN is a free and open-source VPN application that allows you to encrypt and send your network data via secure tunnels from one device to another not located on the same network. OpenVPN uses OpenSSL to encrypt network traffic to and from your devices.
Once connected to an OpenVPN server, your network traffic gets routed through the server, keeping your data secure. In turn, this helps protect you from network attacks, especially when connected to public networks.
NOTE: Using a VPN does not always guarantee data privacy. Always store your private information at secure and encrypted locations.
This guide will walk you through installing and setting OpenVPN on Kali Linux to protect your traffic when doing pen-testing.
For this, you will require:
- A working installation of Kali Linux
- Internet connection
Installing OpenVPN
The first step is to install the OpenVPN packages using the apt command as:
sudo apt-get install openvpn network-manager
Once you have the packages installed, restart your device to ensure that the changes take effect.
Connecting to a VPN
The next step is to connect to a VPN server. You will need to have an OpenVPN configuration file. You will often find OpenVPN files from your VPN provider in the .ovpn extension.
Once you have your config file, use the command below to connect to the vpn server. You will need the username and password to connect to the server.
$ echo "PASSWORD" >> /etc/openvpn/credentials
$ sudo openvpn se-us-01.protonvpn.com.udp.ovpn
Tue Feb 9 18:37:41 2021 OpenVPN 2.4.7 x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Feb 20 2019
Tue Feb 9 18:37:41 2021 library versions: OpenSSL 1.1.1d 10 Sep 2019, LZO 2.10
………..
You can also import a VPN configuration file using the GUI interface.
Conclusion
This quick guide has shown you how to install and setup OpenVPN on Kali Linux.
]]>Developed by Sun Microsystems in 1984, NFS or Network File Shares is a file system protocol used for accessing files over a network similar to a local storage device.
NFS Shares are powerful and popular as they allow users to share files and directories over a local network and the internet. However, it is better to limit NFS shares to local and trusted networks as files don’t get encrypted on the machines. However, the problem was addressed and fixed on a recent version of the NFS protocol. You may need to set up complex authentication methods such as Kerberos.
This tutorial will walk you through how to set up NFS shares on a Linux system. Let us get started.
Setting up NFS Server
Let us start by setting up the NFS server. This process is fairly simple, with only a few commands:
sudo apt-get install nfs-kernel-server
Next, create a directory in the local system which will be used as the NFS’ share root directory:
Set the appropriate permissions to the directory:
Next, edit the exports file in /etc/exports and add the following entry
Setting Up An NFS Client
For you to mount NFS Shares on Linux, you will need to install nfs client tools using the command:
Mounting an NFS Filesystem
The process of mounting NFS file shares is very similar to mounting a regular file system in Linux. You can use the command mount. The general syntax is as:
To accomplish this, start by creating a directory to use as the NFS Share’s mount point.
Next, mount the NFS share using the mount command as shown below:
Once completed, you should have access to the remote shares on the server.
Unmounting File shares
Since an NFS share is similar to a file system, you can unmount it with umount command as:
You can use other options with umount command, such as a force to force-unmount the NFS shares.
Conclusion
The above is a simple guide on how to use and mount NFS shares on a Linux system. There is more to NFS than what we have discussed here; feel free to utilize external resources to learn more.
]]>Let us get started.
Requirements
To set up a complete Kali Linux mirror, you will need to have a few resources. These include:
- An accessible web server with HTTP and HTTPs access
- A large disk space—As of writing this, according to Kali Linux maintainers, the Kali Linux package repository is 1.1 TB and growing fast
- HTTP and RSYNC services installed and running on the system
Set up a User for Kali Linux mirror
The first step is to set up a full account dedicated to kali Linux mirrors only. Use the adduser command:
Adding user `linuxhint’...
Adding new group `linuxhint’ (1001) ...
Adding new user `linuxhint’ (1001) with group `linuxhint’...
Creating home directory `/home/linuxhint' ...
Copying files from `/etc/skel' ...
Changing the user information for linuxhint
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Set up Mirror Directories
Next, we need to set up the directories that contain the mirrors and assign permissions to the user we’ve created.
chown linuxhint:linuxhint /srv/mirrors/kali{,-images}
The commands above will create the directories kali and kali-images and set ownership to the user we created earlier.
Set up rsync
The next step involves starting and configuring rsync service. Export the directories using the command:
# nano /etc/rsyncd.conf
# cat /etc/rsyncd.conf
uid = nobody
gid = nogroup
max connections = 25
socket options = SO_KEEPALIVE
[kali]
path = /srv/mirrors/kali
read only = true
[kali-images]
path = /srv/mirrors/kali-images
read only = true
# service rsync start
Starting rsync daemon: rsync.
Configuring your Mirrors
Next, we need to export the mirrors under http://domain.com/kali and http://domain.com/kali-images
We start by downloading and unarchiving the http://archive.kali.org/ftpsync.tar.gz archive in the user’s directory created earlier.
# wget http://archive.kali.org/ftpsync.tar.gz
# tar zxf ftpsync.tar.gz
Next set up the configuration file.
cp etc/ftpsync.conf.sample etc/ftpsync-kali.conf
nano etc/ftpsync-kali.conf
grep -E '^[^#]' etc/ftpsync-kali.conf
MIRRORNAME=`hostname -f`
TO="/srv/mirrors/kali/"
RSYNC_PATH="kali"
RSYNC_HOST=archive.kali.org
Configuring SSH Access
The final step is to configure SSH authorized keys for archive.kali.org to trigger the mirror.
chown 700 /home/linuxhint/.ssh
wget –O- -q http://archive.kali.org/pushmirror.pub >> /home/linuxhint/.ssh/authorized_keys
chown 644 /home/linuxhint/authorized_keys
Contacting Kali.org
Once you have finished setting up your system, send an email to [email protected] providing all details for your mirrors, including the user, the port to access the SSH service, and public hostname. You should also state who Kali should contact in case of problems and if any changes should get applied according to the mirror setup.
From there, all you have to do is wait for the first push from archive.kali.org.
]]>Let’s discuss how we can modify installed packages and rebuild them from the source.
NOTE: Before we begin, you will need to include the source deb-src package URIs in the sources.list file.
Adding deb-src Packages
To add the deb-src package in Kali Linux sources.list file, edit the file in /etc/apt/sources.list and uncomment the deb-src line.
![]()
Next, update your source packages before proceeding.
NOTE: Ensure you have the dpkg-dev package installed.
Downloading Source Packages
The next step is to download the source package. For this example, we will use vim. Run the commands:
sudo apt source vim
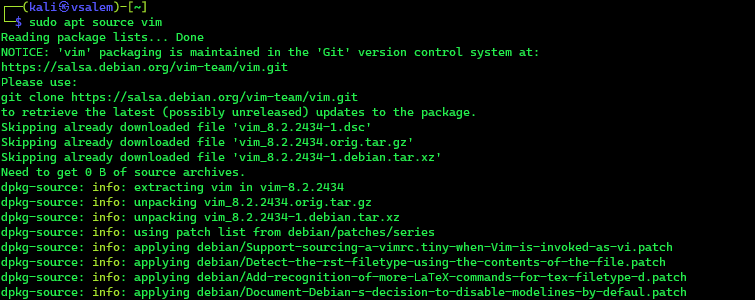
Next, navigate to the vim source package directory
Modify Package Source Code
The next step is to make changes to the source code as you see fit. I will not get into details because this will depend on the package you are modifying and your targeted needs.
Once you have made your appropriate modifications, save and close the file.
Check for Build Dependencies
Before rebuilding the source packages, you need to install the package dependencies. You can check the required dependencies using the command:
Running this command will display all the required dependencies before rebuilding the package. The result will be empty if no dependencies are required. For vim, you’ll see an output similar to the one shown below:
Installing Build Dependencies
Once you have the list of required dependencies, simply use apt to install them as:
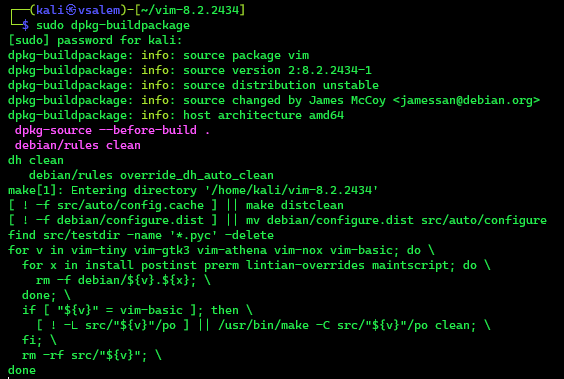
Building the Source Package
After fulfilling the required dependencies and saving the new source package changes, you can build the new package.
Use the command below to build the new package.
Installing New Package
Once the build completes successfully, you should have a .deb package that you can install using dpkg.
Conclusion
This quick guide has shown you how to source, modify, and rebuild packages in Kali Linux. Rebuilding packages can be very useful when you want a customized version of a tool.
Thank you for reading.
]]>This tutorial will show you how you can set up a simple blog using a static site generator that is very fast and easy to use.
What Is An SSG?
SSG, or Static Site Generator, is a web application that converts the dynamic content on a webpage into static content usually stored locally. Static site generators do not require databases and backends, thereby eliminating the need to learn how to code. It mainly focuses on writing and presenting the content.
SSG vs. CMS
The most popular way to create websites and manage content is using CMS or Content management systems such as WordPress, Drupal, Joomla, etc.
CMS systems work by creating and managing content directly using an interactive interface. Since data in a CMS is retrieved from the database, CMSs are very slow as the content is fetched and served as dynamic content. CMS systems are also prone to security vulnerabilities as they rely on external plugins written by other developers to increase functionality.
On the other hand, static site generators work by creating content offline mediums such as text editors and renders the final page view upon publication. Since the content is locally-rendered, with no need for a database, the page renders faster, and load speeds are incredibly fast.
Static site generators are made of pre-compiled code that acts as an engine to render the published content.
How to Build a Static Blog With Hexo
One of the popular choices for building a static site is Hexo.
Hexo is a simple, fast, and powerful SSG application written in NodeJS. Although there are other choices for building a static site, Hexo allows you to customize your site and integrate various tools.
Let us look at how we can set up a simple static site with Hexo.
Installing Hexo
Before we can build a site, we need to set up hexo requirements and install it. For this, we require NodeJS and git.
Start by updating your system:
sudo apt-get upgrade
Once you have your system up to date, install git
Next, install nodejs from nodesource using the command:
apt-get install -y nodejs
Once you have Nodejs installed, we can proceed to install hexo using the command:
Working with Hexo
Once you have installed hexo, you can create a site and publish content. Let us look at how to work with Hexo. Keep in mind that this is a quick, simple guide. Refer to the documentation to learn more.
Creating a site
To create a new hexo site, use the command below:
cd HexoSite
npm install
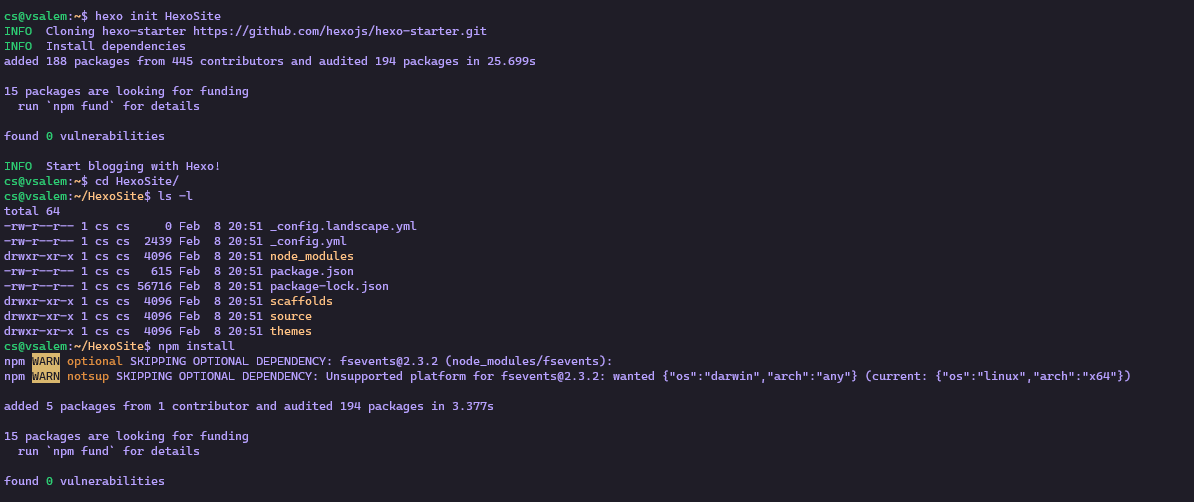
Understanding Hexo Directory structure
Once you initialize a new Hexo site, you will get a directory structure such as the one below:
-rw-r--r-- 1 cs cs 2439 Feb 8 20:51 _config.yml drwxr-xr-x 1 cs cs 4096 Feb 8 20:51 node_modules
-rw-r--r-- 1 cs cs 615 Feb 8 20:51 package.json
-rw-r--r-- 1 cs cs 56716 Feb 8 20:51 package-lock.json drwxr-xr-x 1 cs cs 4096 Feb 8 20:51 scaffolds drwxr-xr-x 1 cs cs 4096 Feb 8 20:51 source drwxr-xr-x 1 cs cs 4096 Feb 8 20:51 themes
The first file is the _config.yml contains all the settings for your site. Ensure to modify it before deploying your site because it will contain default values.
The next file is the package.json file that contains the NodeJS application data and configurations. Here, you will find installed packages and their versions.
You can learn more about the package.json from the resource page below:
https://docs.npmjs.com/cli/v6/configuring-npm/package-json
Creating a Blog
To create a simple blog in hexo, use the command:
Once created, you can file the markdown file under /source/_posts directory. You will need to use Markdown markup language to write content.
Creating a new page
Creating a page in Hexo is simple; use the command:
The page source is located under /source/Page-2/index.md
Generating and Serving content
Once you publish your content on hexo, you will need to run the application to generate the static content.
Use the commands below:
INFO Validating config
INFO Start processing
INFO Files loaded in 966 ms
INFO Generated: archives/index.html
INFO Generated: Page-2/index.html
INFO Generated: archives/2021/index.html
INFO Generated: index.html
INFO Generated: archives/2021/02/index.html
INFO Generated: js/script.js
INFO Generated: fancybox/jquery.fancybox.min.css
INFO Generated: 2021/02/08/Hello-World-Post/index.html
INFO Generated: css/style.css
INFO Generated: 2021/02/08/hello-world/index.html
INFO Generated: css/fonts/FontAwesome.otf
INFO Generated: css/fonts/fontawesome-webfont.woff
INFO Generated: css/fonts/fontawesome-webfont.eot
INFO Generated: fancybox/jquery.fancybox.min.js
INFO Generated: css/fonts/fontawesome-webfont.woff2
INFO Generated: js/jquery-3.4.1.min.js
INFO Generated: css/fonts/fontawesome-webfont.ttf
INFO Generated: css/images/banner.jpg
INFO Generated: css/fonts/fontawesome-webfont.svg
INFO 19 files generated in 2.08 s
To serve the application, run the command:
Conclusion
This quick and simple introduction has shown you how to use the Hexo static site. If you need more information on how to work with Hexo, please refer to the main documentation provided below:
Offensive Security took note of this and included a mode known called undercover mode in Kali Linux 2019.4.
The undercover mode in Kali Linux is a collection of scripts that allow you to simulate a Windows 10 environment on Kali Linux. It converts the entire interface into a Windows 10 equivalent, limiting the attention you would attract if you were running XFCE with various terminals running and the Kali dragon in the background.
To enable and use Kali Linux undercover mode, you will need to have Kali Linux 2019.4 or later.
Upgrading to 2019.4 or Later
Start by upgrading your distribution using the commands:
sudo apt -y full-upgrade
You may also need to use XFCE Desktop Environment
Enabling Kali Undercover Mode
To run undercover mode, open the terminal and enter the command:
If you prefer to use GUI, launch the application menu and search for Kali Linux Undercover.
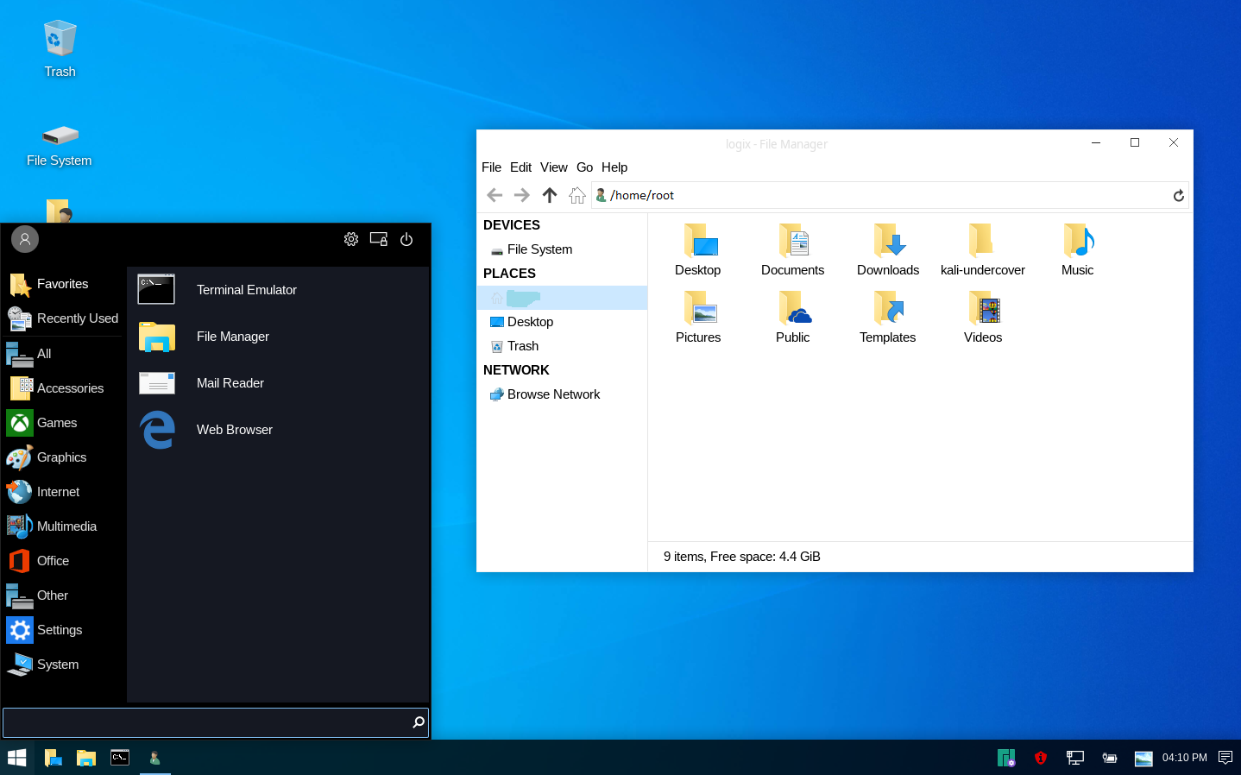
Reverting to Normal Mode
To return to the default mode, enter the command:
Its primary use is on GNU Gparted and PartitionMagic packages, although PartedMagic is a commercial Software. It’s essential for data.
This tutorial will walk you through PartedMagic operations like creating bootable media, booting up, partitioning, data recovery, etc.
How to Use PartedMagic To Create a Bootable Media
- Let us start by getting a copy of the PartedMagic ISO by navigating to the official website: https://partedmagic.com/store/
- Next, we need to burn the PartedMagic ISO to a CD or USB. For this tutorial, we will illustrate using a USB drive. You can use tools such as PowerISO (on Windows) or K3B (For Linux).
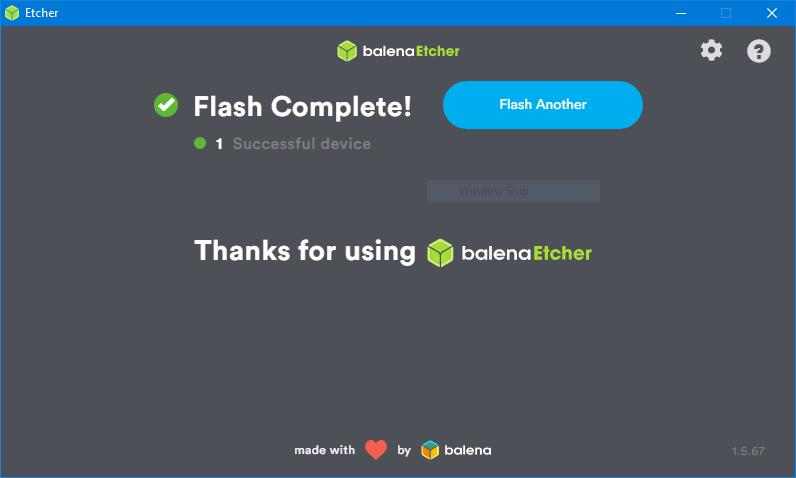
- Download a USB bootable media creation tool. Open the following resource link to download balenaEtcher: https://sourceforge.net/projects/etcher.mirror/
- Install the application—it works for Mac, Windows, and Linux systems, then launch it.
- Ensure you have your USB drive connected and is visible under the Devices* Tab in balenaEtcher.
- Select the PartedMagic iso to burn. If you have multiple USB drives connected, select the correct one and click Flash
- ALL THE DATA STORED IN THE DRIVE WILL BE ERASED! BACKUP IMPORTANT CONTENT!
- Wait until the Flash process completes, allowing you to boot into PartedMagic.
How to Boot Up PartedMagic
- To use PartedMagic, we need to boot into it like a Normal OS.
- Reboot your Machine and Press the Boot Key. Check this site for your boot-up key: https://www.disk-image.com/faq-bootmenu.htm
- This will take you to the PartedMagic Boot-up Menu. Here’re you have various options and operations you can perform. However, we want to boot into PartedMagic Interface.
- Select the Live with Default Settings 64
- Selecting this option will boot up the OS, and you will get to the PartedMagic Desktop Environment.
- Once in the desktop environment, you can perform tasks like partitioning disks, cloning, erasing, and surfing the web.
How to Use GParted
One of the tools available in the PartedMagic Toolset is GParted. It allows us to perform changes to disks and partitions. For example, we can use it to create a partition for a Linux system installation.
Let’s discuss how to use GParted to partition a disk.
DISCLAIMER: DO NOT try this on a Drive with valuable data. You will lose the data. We take no responsibility for any data loss that may occur due to instructions given in this tutorial. BACK UP YOUR DATA!
We will partition an existing disk and create a new partition that we can use to install a Linux distribution. We will not be formatting the partition. Unless you are an advanced Linux user, stick to Resizing a Partition.
After performing disk changes with GParted, perform a disk check to fix any errors that may keep the installation from booting up.
1. Start by booting up PartedMagic. Once you’re on the desktop, launch GParted by selecting Partition Editor on the desktop.

2. This will automatically launch GParted and list all the available disks. Select the target disk from the main menu. By default, GParted selects the first disk from the list of the connected devices. Choose the desired disk from the dropdown menu.
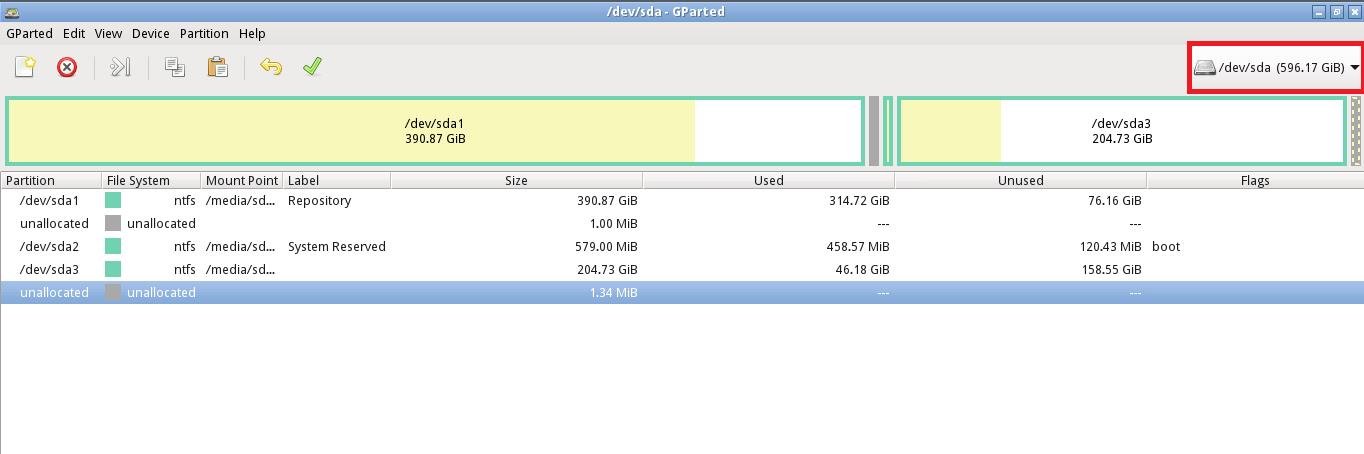
3. Once you have the desired disk selected, the system will reload the disk, displaying all the disk’s information such as Partitions, File system, Partition Tables, etc.
4. Now, select the partition you wish to resize and right-click. Select Resize/Move option. If you have multiple partitions, select the partition at the end, making it easy to reattach the partition if desired.
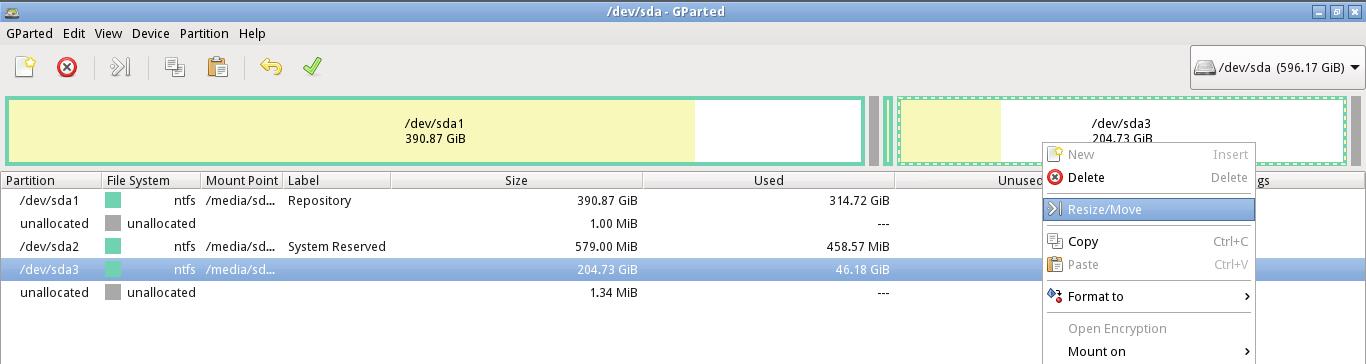
5. That will launch the Resize/Move /dev/sd_ dialog box.
6. At this point, you can specify the free space for the resized partition. For ease of use, use the colored indicator to resize the partition. Ensure to leave adequate free space on the existing partition.
7. Once you are satisfied with the size allocated to the partition, click on Resize, which will close the dialog box and navigate back to the GParted main window. Gparted will display changes performed to the disk but not applied.
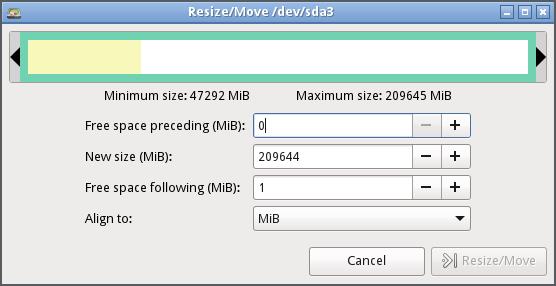
8. Complete the specified operation to the disks by selecting the Apply option on the main menu. If you’re performing tasks on a disk with data, ensure you are comfortable with the changes before applying.
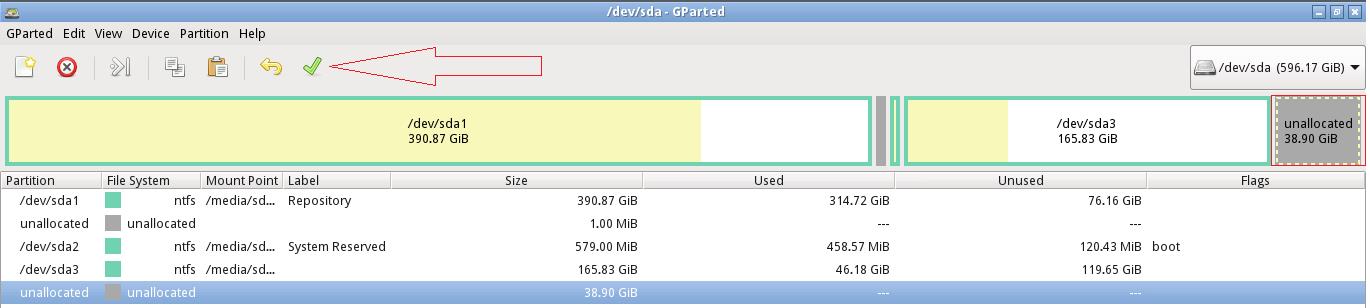
9. GParted will apply all the pending operations. It will display the progress as it occurs and shows the Applying Pending Operations complete dialog window.
10. To view the log of the recently performed operations, select View Details options.
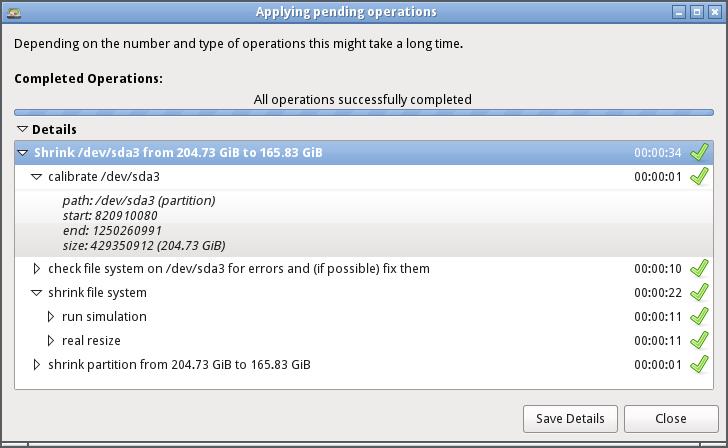
11. Resizing partition creates an unallocated disk space you can to perform tasks install a new Linux OS. You can perform the partitioning while installing the OS or create them using GParted. For the sake of this tutorial, we will not create the Filesystem.
Formatting A Partition
1. Once we have created a partition, we can format it using GParted.
2. Right-click on the unallocated partition we created and selected NEW
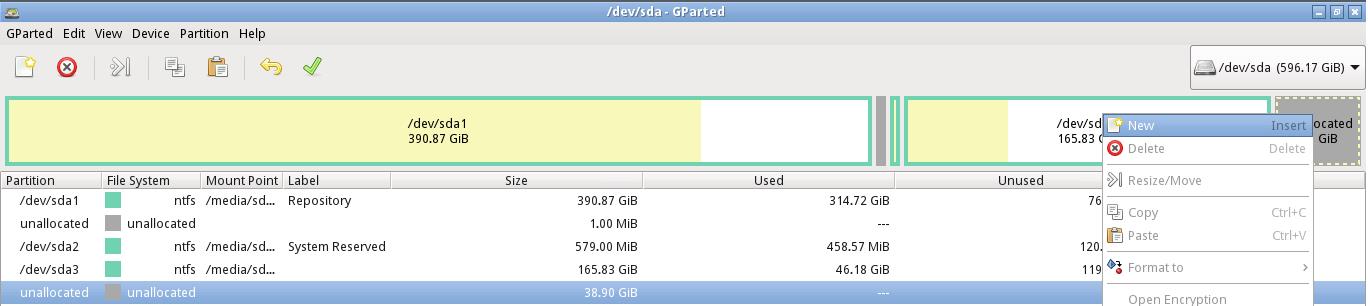
3. You can either create a Primary or Extended Partition. For those using MBR, you cannot have more than three primary partitions, and you will have to stick to the Extended partition
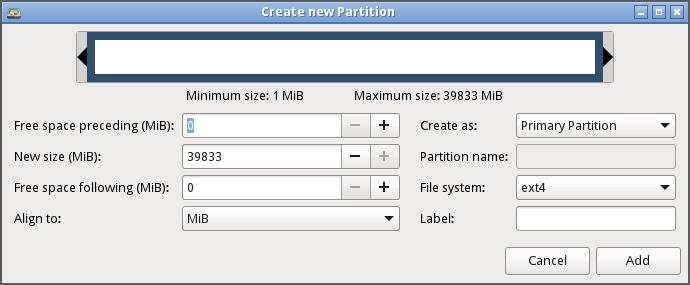
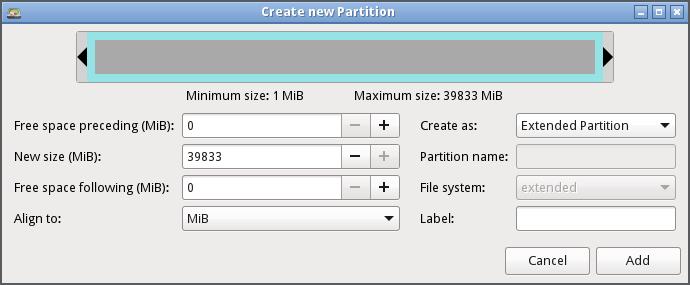
4. Select the Label the File system such as DOS, EXT4, ETX3, etc.
5. Finally, select ADD and apply all the changes.
Conclusion
You can perform other tasks with PartedMagic like copying files using the file manager, cloning a disk, erasing a disk, encryption, erase traces, etc.
TO AVOID LOSING, BE CAREFUL WHILE WORKING WITH PARTED MAGIC DATA!
]]>OpenVAS consists of:
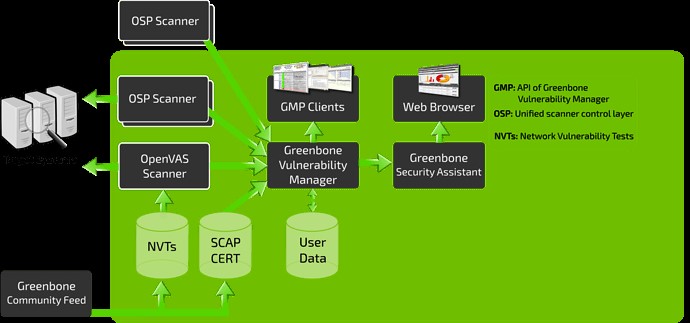
- A database comprised of results and configurations
- A Scanner that runs various Network Vulnerability Tests
- A Collection of Network Vulnerability tests
- A Greenbone Security Assistant, a web interface that allows you to run and manage scans in the browser
In this tutorial, we will cover how to install and configure the OpenVAS tool on Kali Linux.
Installing OpenVAS
Before installing OpenVAS, the first thing we need to do is ensure your system is up to date.
NOTE: Skip this step if you have an updated system:
sudo apt-get dist-upgrade
Once you have your system up to date, we can install OpenVAS:
Having installed OpenVAS successfully, you will have access to the setup script. Launch it to configure OpenVAS for first-time use:
NOTE: Depending on your system configuration, you may need to install an SQLite database.
Remember to note down the password generated during the setup process as you will require it to log in to the Greenbone Security Assistant web interface.
Starting and Stopping OpenVAS
If you have OpenVAS configured properly, you can run it by executing the command:
This command should launch the OpenVAS service and open the browser. You can manually navigate to the web interface using the default listening ports.
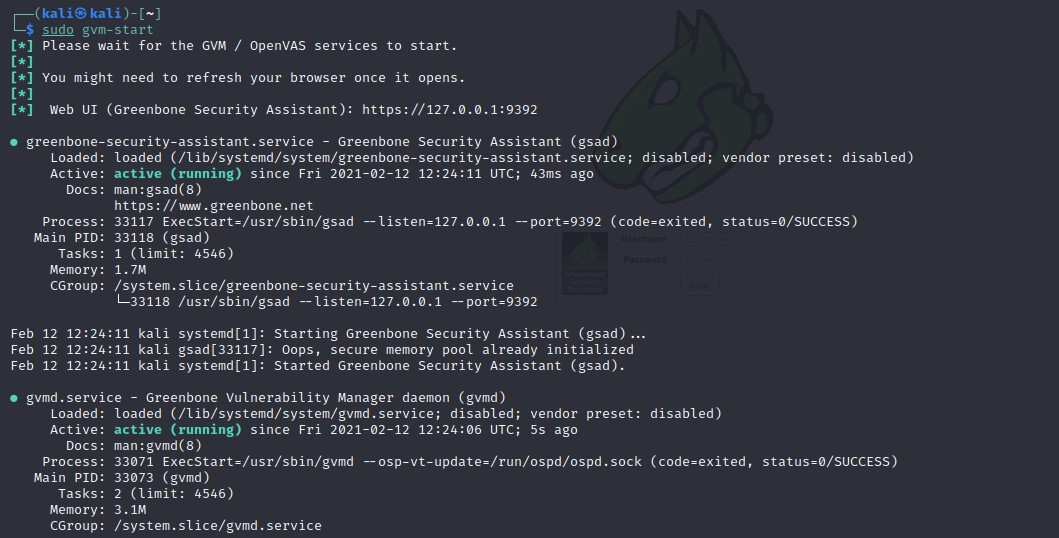
This command should launch the services listening on port 9390 and 9392
Troubleshooting Errors
Installing OpenVAS on older versions of Kali and other Debian flavors may result in some errors. Here’re some possible ways of fixing possible errors:
Install PostgreSQL or SQLite3 database
sudo service postgresql start
sudo apt-get install sqlite3
sudo service sqlite3 start
Next, use gvm commands:
sudo gvm-setup
sudo gvm-feed-update
sudo gvm-start
NOTE: Depending on the version you have installed, you may need to use the gvm (Greenbone Vulnerability Manager) command other than OpenVAS.
Accessing OpenVAS Web UI
Using the Greenbone Security Assistant features, you can access the OpenVAS web UI from your local machine. You will need to have OpenVAS running to access the interface.
Open your browser and navigate to http://localhost:9392
Use the username as admin and the password generated in the setup process.
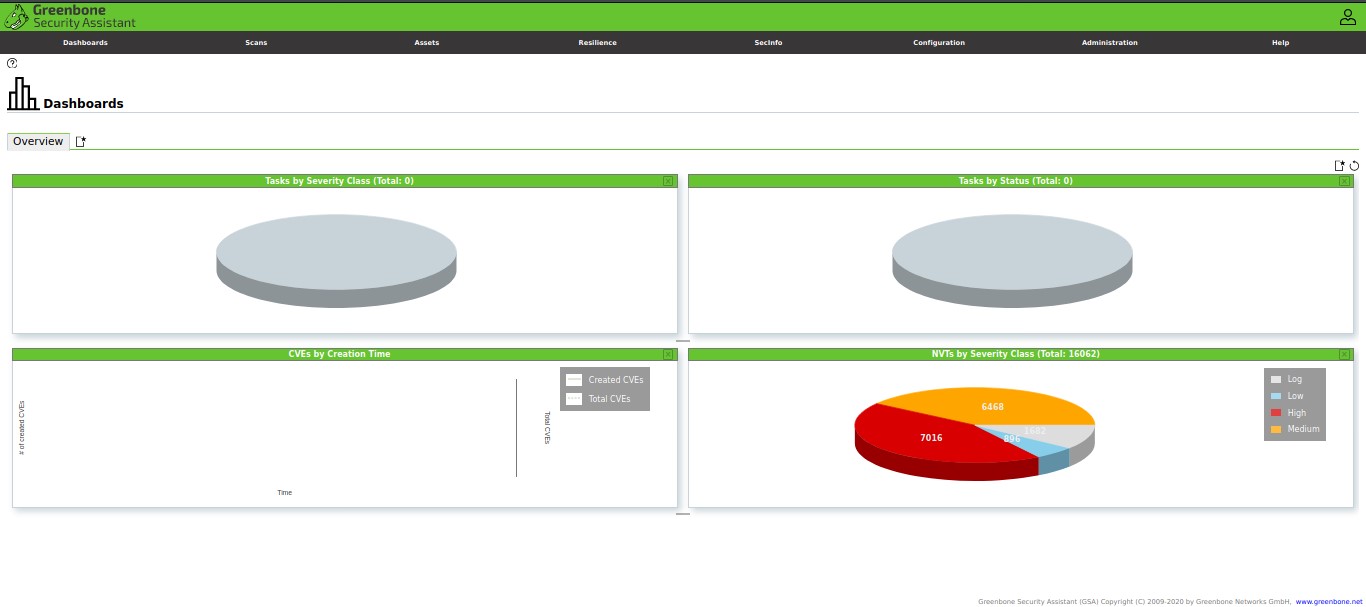
Once you log in, you should have access to OpenVAS web UI, which you can configure to suit your needs.
Add Target
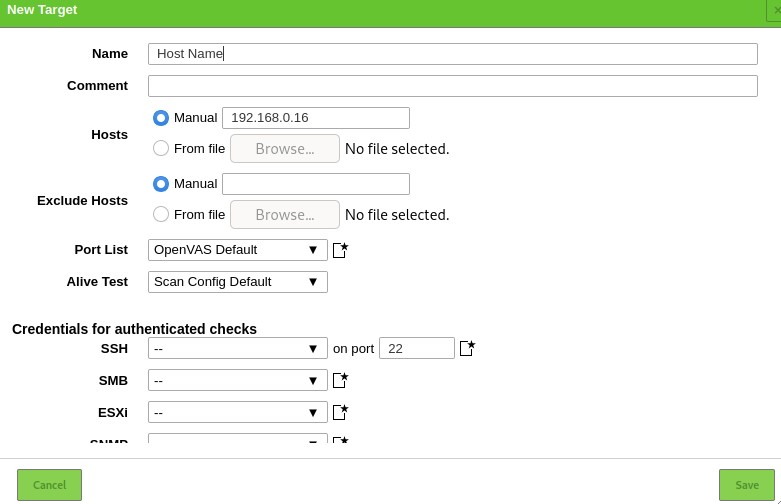
The first step to using the Security Assistant is to add targets. Navigate to the configuration menu and select targets.
On the top left corner, select a blue icon to start adding targets. Doing that will launch a dialogue window that allows you to add information about the target, such as:
- Target Name
- The IP address
Once you add all the relevant information about the target, you should see it listed in the targets section.
Creating a Scan Task
Let us now proceed to create a scan task. A task in OpenVAS defines the target(s) you want to be scanned and the required scanning parameters. For the sake of simplicity, we will use the default scan options.
Navigate to Scans sections and select Tasks in the dropdown menu. Click on the icon on the left-hand side to create a new task.
That will launch a window allowing you to provide all relevant information for a scanning task.
- Task name
- Scan target
- Schedule
Use the default settings and click on Create.
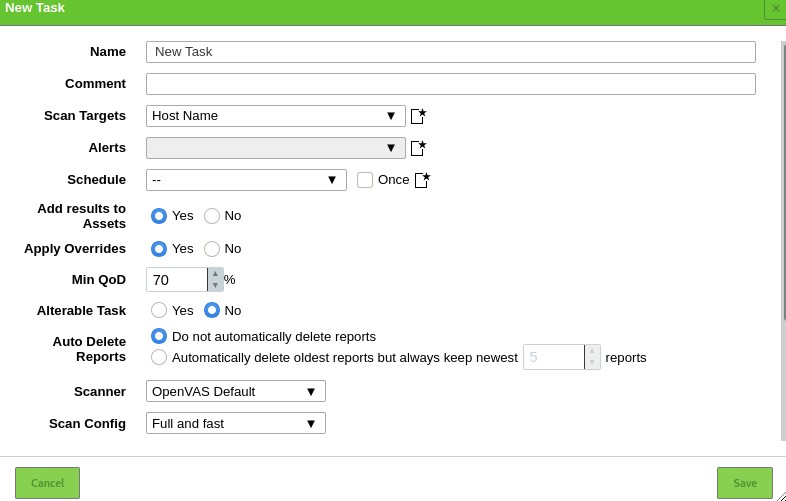
To run a task, click on the Play icon on the bottom left of the task list.

Adding Users
OpenVAS allows you to add various users and assign various roles to them. To add a user or role, navigate to the administration section and click on users. Select the add new icon and add the user information:
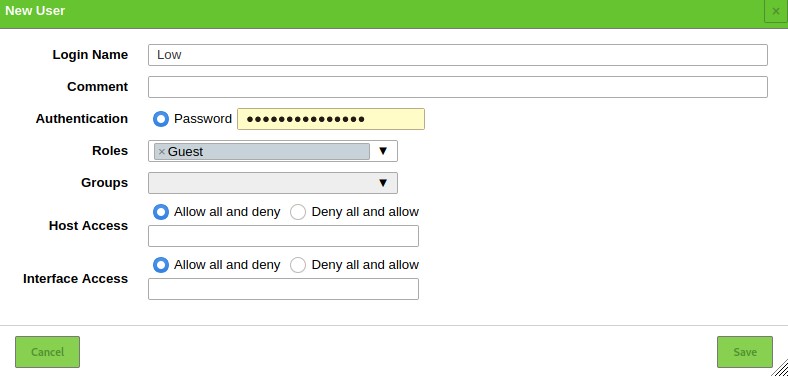
Conclusion
OpenVAS is a powerful tool that brings the power of cybersecurity research into your hands. You can use it to monitor devices in your network and websites on remote servers.
]]>One of the popular version control systems is git, which serves developers from their local systems to the cloud. Now, there are various ways through which you can utilize the power of git, for example, paying for remote repositories on services such as GitHub, GitLab, and many more. You can also build your own git system hosted on a server on the cloud and use it for your own projects and teams.
This tutorial will learn how to set up your version control system on Linux using Debian 10 and GOGs. Stay tuned to the end to learn more.
Introduction to GOGs
GOGs is a simple, painless self-hosted Git service written in Go language. It is simple, and it does not require heavy computing resources. Due to the nature of its programming language, GOGs is also incredibly fast.
GOGs is a popular choice for anyone looking to set up their own private git service without paying for a server on GitHub providers.
This tutorial will use a local Debian system, Go programming language, and MySQL as the database.
Installing Go Lang
Go is a fast, open-source programming language that is efficient at building applications. Since GOGs is written in Go, we need to install it before compiling GOGs on the system.
Installing Go language is simple.
First, open the terminal and download the go archive using wget as:
Next, extract the archive in /usr/local directory:
Once we have extracted the archive, we need to export the go binary location to the path in the .bashrc file.
Edit the file and add the following entries
export GOROOT=/usr/local/go
export PATH=${PATH}:$GOROOT/bin
Now save the file and apply the changes by sourcing the bashrc file:
Now verify that go is installed by calling the command go:
Installing the Database
Let us now build the backend database for the GOGs system. It is good to note that a database is completely optional, and GOGs will run with or without it.
The first step is to ensure you have your system is up to date:
Next, install the MySQL server:
Next, launch the SQL shell and enter the commands:
mysql> CREATE DATABASE gogs;
mysql> GRANT ALL ON gogs.* TO 'gogs';
Installing GOGs
Now that we have all the requirements to run GOGs on our system, we can proceed to compile the application.
First, download it using the git clone command:
Navigate to gogs directory
Compile the main program
Once completed, launch the gogs binary:
This will launch the webserver and listen for incoming http connections.
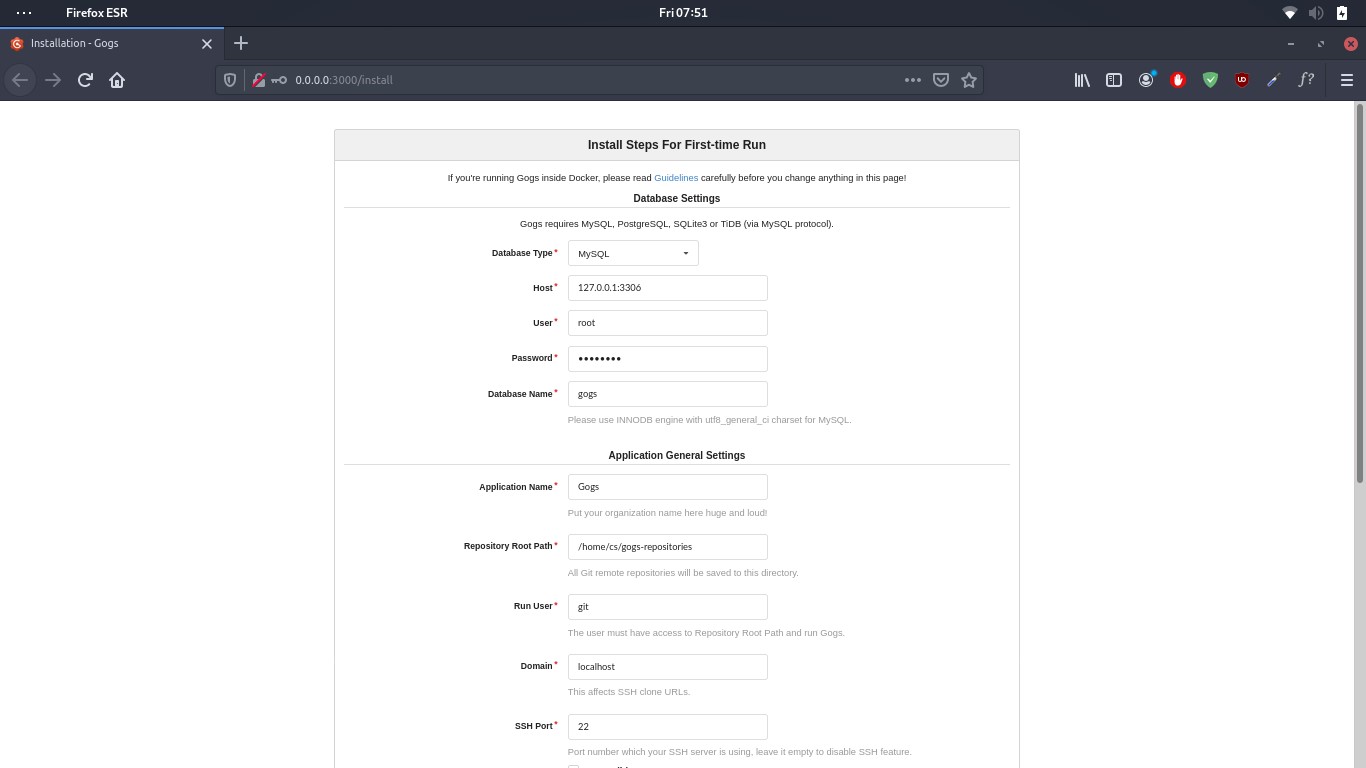
Configuring GOGs
Once the webserver is running, launch the gogs web interface using the address http://localhost:3000
This will launch the GOGs installer allowing you to configure GOGs backend.
Modify the information as we created in the MySQL database earlier.
Host = 127.0.0.1:3306
User = gogs
Password =
Database Name = gogs
Once you have configured the server correctly, create an admin account and start using GOGs.
If you are looking for a git tutorial, consider the article on how-to-install-and-use-git-on-Linux.
Conclusion
In this quick guide, we discussed installing and using GOGs, a self-hosted git service on a Debian system. This tutorial can be expanded greatly to host GOGs on a live server with a web address. However, it is a good starter guide for beginners.
]]>TeamSpeak is a virtual intercom that allows you to communicate with other people connected to the server. TeamSpeak is popular in gaming events, but in recent years, many people have adopted it for work events, collaboration on projects, and even friendly communications between family and friends.
Installing TeamSpeak Server
To get started, we need to install the TeamSpeak server. Start by launching your browser and navigate to:
https://teamspeak.com/en/downloads/#server
Under Linux, select 32bit or 64bit—download according to your system.
Now that you have the TeamSpeak Server downloaded, we can proceed to the next step.
You can also use the wget command to download the TeamSpeak archive as:
services.com/releases/server/3.13.3/teamspeak3-server_linux_amd64-3.13.3.tar.bz2
Now extract the archive with tar command as:
Next, navigate to the extracted directory and run create a file “.ts3server_license_accepted”. Add the line “license_accepted=1
license_accepted=1
Next, launch the server using the command:
Next, note all the information printed, including usernames and passwords. These are important, and you will require them to log in.
I M P O R T A N T
------------------------------------------------------------------
Server Query Admin Account created
loginname= "serveradmin", password= "V7+4mpYV"
apikey= "BAAvWDVfmburJhB0n_tSYPl8UVapmcVK13V4Tx-"
------------------------------------------------------------------
------------------------------------------------------------------
I M P O R T A N T
------------------------------------------------------------------
ServerAdmin privilege key created, please use it to gain
serveradmin rights for your virtual server. please
also, check the doc/privilegekey_guide.txt for details.
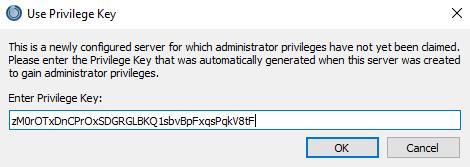
token=zM0rOTxDnCPrOxSDGRGLBKQ1sbvBpFxqsPqkV8tF
------------------------------------------------------------------
Installing The TeamSpeak Client
To login into the TeamSpeak server, you will need to have a TeamSpeak Client. Navigate to the resource page below and download the client for your system.
http://teamspeak.com/downloads
Once downloaded, launch the client and enter the IP address to your TeamSpeak server.
Next, provide the server name and password created in the initial launch of TeamSpeak.
Click on connect, then provide the server token and paste it.
Conclusion
You now know how to install TeamSpeak on Debian 10 and connect to it.
]]>In this tutorial, we will discuss using Weechat for Internet Relay Chats on Debian 10. If you’re new to using IRC, this tutorial will help you get started:
Let’s start at the very beginning:
What Is IRC?
Before we get into how to use WeeChat for IRC, let us define a few terms that will make it easier to understand everything we shall discuss:
IRC or Internet Relay chat is a type of application layer protocol used to create and manage IRC networks. IRC networks involve a client/server model that uses a simple IRC client such as WeeChat and a Server to connect to the network.
IRC servers are responsible for transporting messages to users in the connected IRC channels. A collection of more than one IRC server makes up an IRC network, allowing real-time communication between devices.
IRC networks have channels that users can join and communicate within that specific channel. Any registered user in the IRC network can create a channel and share it with other users who want to join.
Users can also create private channels that are usually private and hidden. An example of a channel is the #debian or #ubuntu for Debian and Ubuntu, respectively.
IRC channels are usually prefixed by a pound sign # followed by the channel name.
Users on an IRC network are managed by various characteristics such as their nickname, username, IP address, and real name.
An IRC nickname is a set of characters freely chosen by the user. Nicknames in an IRC network should be unique to each user. You will often hear them referred to as an IRC handle.
The username is simply an identifier for the specific user, which is different from the nickname. Usernames do not necessarily have to be unique.
The IP is simply the internet address of the host device from which the user is connecting.
The real name is an optional identifier that can help identify the user’s real name.
A typical user identity on an IRC is as:
With the basics nailed down, let’s move on and discuss how we can use WeeChat to connect to IRC networks.
Introduction to WeeChat
WeeChat is a simple, powerful, and intuitive C language-written IRC client. WeeChat is cross-platform and can run on Windows, Linux, and macOS. It is highly flexible and supports tool integration written in other programming languages such as Perl, Python, and Ruby.
Since WeeChat is cross-platform and terminal-based, making it a popular choice for many IRC users. It allows terminal customization and extensibility using extensions.
It also allows you to leave the IRC client running in the background as you use the terminal for other remote or local sessions.
Check the official WeeChat site for more details about its capabilities:
We need to install WeeChat before we can use it on our system:
How to Install WeeChat
This tutorial only covers WeeChat installation on a Debian system. Check the official documentation for other installation instructions.
WeeChat is available in the official Debian repositories.
Start by updating the system repos using the command below:
Once we have the system up to date, we can install WeeChat using the command:
Running WeeChat
Once you have WeeChat installed on your system, you can launch it by executing the command WeeChat in the terminal.
This command will launch the WeeChat tool as:
How to Use WeeChat
Once you are ready to use WeeChat, we can get started. The first thing we need to learn is how to connect to an IRC server.
Add and Connect to an IRC server
Before we can connect to any IRC server using WeeChat, we need to add it using the /server command:
Here’s an example of adding a Freenode server:
The above command tells WeeChat to add the server chat.freenode.net under the name Freenode.
You are free to use any suitable name for the servers you add.
Once you have a server added, we can connect to it using the /connect command:
For example, to connect to the Freenode server, we added:
Once you have connected to an IRC server, you can join any channels available in the server using the /join command as:
For example, to join the Debian IRC channel:
To leave a channel or part a channel that keeps the buffer open, you can use the command:
To completely close and leave the channel, use the /close command.
Managing channel buffers
A buffer refers to a component linked to a plugin using a numerical value, a category, and a name. A window is a view on a buffer. By default, WeeChat only displays one window on one buffer. However, you can split windows to view multiple windows with multiple buffers in a single instance.
Check out the IRC documentation to learn more about buffers and windows.
You can use the following commands to manage buffers and windows.
For buffer, use the command:
For windows, use the command:
For example, to split your screen into a large window, use the command:
You can remove the split by merging the windows using the command:
To switch between buffers, you can call them using the number or their name. For example, to switch to buffer one or buffer #debian respectively:
WeeChat also supports shortcuts to navigate between buffers. For example, use the ALT+number where the number is the buffer to switch to.
NOTE: By default, WeeChat does not display buffer names or numbers; you will need to install buffer.pl plugin to enable this feature. Check how to install a WeeChat plugin below.
Sending IRC private Messages
You can open a buffer to send a private message to a specific user in an IRC channel.
The general syntax is:
For example, to send a message to a linuxhint user, use the command:
If you want to establish a consistent buffer for sending private messages, you can use the /query command.
For example:
The command above will open a conversation buffer between you and the specified user.
How to Configure WeeChat
WeeChat is a useful tool for IRC. It provides a wide range of tools and configurations. You can edit the configuration file located in ~/.weechat or use commands to edit the configuration.
WeeChat config Commands
You will mainly use WeeChat commands to interact with users and perform configurations.
All Weechat commands have a preceding forward-slash (/), with most of the commands supported within IRC channels.
Some of WeeChat commands include:
- /help – it displays available commands or helps for a specific passed command.
- /quit – closes WeeChat sessions.
- /close – terminates a specific buffer in WeeChat.
- /join – joins a specified channel.
- /ms.- sends a private message to a specific user in the current buffer.
- /query – opens a private buffer to the specific user.
- /kick – removes a user from a channel.
- /ban – bans a specific user from a channel.
- /kickban – kicks out and bans a user from the channel.
- /topic – specifies topic channel.
- /whois – displays information about a specified user.
- /part – leaves the channel but does not terminate the buffer.
Those are some of the commands you can use to interact and configure WeeChat. To learn more, check out the official documentation.
https://weechat.org/files/doc/stable/weechat_quickstart.en.html#buffer_window
How to Install WeeChat Plugins
WeeChat allows you to extend features and functionality using Plugins, which, in essence, are modifications or extensions of the WeeChat tool. To install a plugin, we use the /script command.
For example, to install the buffer plugin:
You should always provide the name of the plugin, including the extension.
To view all the scripts available, use the /script command with no arguments.
To get a list of all WeeChat scripts, use the resource provided below:
How To Setup IRC Nickname and Username
You can also set up the default nickname and username that WeeChat uses on connect. This will remove the hustle of setting up the nickname or username every time you connect to a network.
To set a default nickname, use the command:
NOTE: You can pass a set of nicknames in case one of them.
To set a default username, use the command:
To change an already connected nickname, use the /nick command as:
Conclusion
We have gone over what IRC networks are, the basics of how they work, and how to install an IRC client on Debian systems and use it to connect to IRC networks. Although this tutorial is short and quick, it covers everything you need to get started with IRC.
To learn more about IRC(s), check out other IRC tutorials on our website.
]]>This tutorial will discuss using your Linux terminal to join other users and communicate with them in real-time. Using IRSSI as the IRC client, you will have the power to communicate in real-time with other users.
NOTE: This guide is a quick guide. It does not dive deep into what IRC networks are or how they work.
For information on how IRC works, check our tutorials on similar topics.
Introduction to IRSSI
IRSSI is a free and open-source, terminal-based, cross-platform IRC client. IRSSI is a popular IRC client because it’s simple to install and use on all the systems.
It also supports scripts that you can install to the existing application to add or expand functionality.
Installing IRSSI on Ubuntu 20.04
By default, the IRSSI client does not come pre-installed on Ubuntu; you will need to install it manually. However, it is available in the official repositories.
Start by updating the repos and system using the command:
Once you have your system up to date, install IRSSI using the command:
How to Use IRSSI
To start using the IRSSI client, enter the command:
This command should launch the IRSSI client, and you can start typing commands to connect to networks and join IRC channels.
Connecting to an IRC network
By default, IRSSI configuration comes with predefined servers that you can join. To view the available servers, use the /network command as:
Once you have the network you wish to connect to, you can use the /connect command followed by the server’s name to connect. For example, to connect to Freenode, type:
If the network you wish to connect to is not on the default list, you can pass the URL of the server to connect to it directly as:
To disconnect from a network, use the command /disconnect followed by the name of the network as:
You can also pass the URL of the network to disconnect.
Joining IRC Channels
Joining IRC channels is very easy using IRSSI. Check out our WeeChat tutorial to learn what channels are:
To join a channel, use the /join command followed by the channel name.
For example, join the official Ubuntu IRC channel:
Once you have connected to a specific channel, you can view the topics, users, and their roles in the room. You can also send messages to all users in that channel.
To leave a channel, use the /part command:
Send Private Messages
Once you have connected to a network, you can send a private message to a specific user instead of all channel users. Use the /msg command followed by the user’s nickname as:
You can use TAB to perform auto-completion for users’ nicknames.
NOTE: Messages are not encrypted or regarded as a secure form of communication.
How to Work with Nicknames
Working with Nicknames in IRSSI is very easy; all you have to do is use the /nick command to configure a new nickname.
For example:
Nicknames in an IRC network must be unique. If the nickname you wish to use is already in use, IRSSI will display a message indicating the nickname is not available.
If you change your nickname when connected to a channel, all users will receive a nickname change notification.
To view information about a specific nickname, use the /whois command as:
Managing Windows and Buffers
When working with IRSSI, every channel and private conversation is ordered in specific windows. You can switch between windows using the /win command followed by the window’s number:
For example:
To view all the available windows, use the command:
NOTE: You can also use the ALT + num of the window to navigate from one window to another.
IRSSI Configuration Commands
IRSSI provides a set of commands we can use to manage the IRC connections, each command preceded by a forward slash:
These commands include:
- /msg – used to send a private message to a specific user in the channel.
- /query – opens a private conversation window with a specific user
- /ban – bans a user in a channel
- /clear – removes a channel buffer
- /exit – closes the IRSSI client
- /window – manages windows settings
- /kick – kicks out a user from the current channel.
- /kickban – Kicks out and bans a user from the current channel.
- /unban – unbans a user.
- /topic – sets the topic for the specific channel.
Those are some of the commands supported by the IRSSI client. Check out the documentation below to learn more on how to configure the client to your needs.
https://irssi.org/documentation/
Conclusion
In this quick guide, we discussed how to use the IRSSI client for quick and efficient IRC communications. To learn more about how to configure the client further, check out the documentation.
]]>SELinux can seem daunting and very hard to implement in most modern systems. However, configuring SELinux has huge benefits both in enforcing security and troubleshooting.
This tutorial will discuss various concepts implemented by SELinux and explore various practical methods of implementing SELinux.
NOTE: Before we begin, it is good to use the commands in this tutorial as the root user or a user within the sudoers group.
Install SELinux Packages
Let us install various SELinux packages, which in turn will help to work with SELinux policies.
Before we proceed to install the SELinux packages, it is good we verify which are installed on the current system.
In most installations of REHL distributions, some packages are installed by default. These packages include:
- setools – this package is used for monitoring logs, querying policies, and context file management.
- policycoreutils-python – provides python core utilities for managing SELinux
- policycoreutils – this package also provides utilities for managing SELinux.
- mcstrans – mcstrans provides SELinux translation daemon, which translates various levels into easy formats which can be understood easily.
- setools-console – similar to setools.
- Selinux-policy – it provides a reference for configuring SELinux policy
- Selinux-policy-targeted – similar to SELinux-policy
- Libselinux-utils – SELinux libselinux utilities which help to manage SELinux
- Setroubleshoot-server – tools for troubleshooting SELinux
To verify which packages are already installed on your system, you can use the rpm –qa command and pipe the result to grep for SELinux as:
libselinux-utils-2.9-4.el8_3.x86_64
rpm-plugin-selinux-4.14.3-4.el8.x86_64
selinux-policy-targeted-3.14.3-54.el8_3.2.noarch
python3-libselinux-2.9-4.el8_3.x86_64
selinux-policy-3.14.3-54.el8_3.2.noarch
libselinux-2.9-4.el8_3.x86_64
This should give you an output of all the packages installed for SELinux support
If not all the SELinux packages are installed on your system, use yum to install them as shown in the command below:
SELinux Modes and States
Let us now start playing with SELinux, specifically, SELinux modes.
SELinux Modes
When enabled, SELinux can be three possible modes:
- Enforcing
- Permissive
- Disabled
Enforcing Mode
If SELinux mode to enforce, it will ensure that no unauthorized access to the system by any user or processes is denied. Enforcing mode also keeps logs of any attempts of unauthorized access.
Permissive Mode
Permissive mode acts like a partially enabled SELinux state. In this mode, no access is denied as SELinux does not enforce its policies in this mode. However, the permissive mode does keep a log of any policy violation attempts. This mode is very efficient for testing before enabling it fully as users and components can still interact with the system but still collecting logs. This allows you to fine-tune your system in ways you see fit.
Disabled Mode
The disabled mode can also be seen as a disabled state in which SELinux is disabled and does not offer any Security.
SELinux States
Once SELinux is installed on a system. It can have binary states: enabled and disabled. To view the state of SELinux, use the command:
Disabled
The above output indicates that SELinux is currently disabled.
You can also use the sestatus command as shown below:
SELinux status: disabled
Enable and Disable SELinux
States and configuration of SELinux are handled by the Configuration file located in /etc/selinux/config. You can use the cat command to view its contents.
#This file controls the state of SELinux on the system.
#SELINUX= can take one of these three values:
#enforcing - SELinux security policy is enforced.
#permissive - SELinux prints warnings instead of enforcing.
#disabled - No SELinux policy is loaded.
SELINUX=enforcing
#SELINUXTYPE= can take one of these three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
From the above output, we have two main directives enabled. The SELINUX directive specified the mode in which SELinux is configured. The SELINUXTYPE directive specifies the SELinux policy set. By default, SELinux uses a targeted policy that allows you to customize access control permissions. The other policy is Multilevel security or MLS.
You may find, minimum policy in some versions.
[ls -l
total 4
-rw-r--r-- 1 root root 548 Feb 16 22:40 config
drwxr-xr-x 1 root root 4096 Feb 16 22:43 mls
-rw-r--r-- 1 root root 2425 Jul 21 2020 semanage.conf
drwxr-xr-x 1 root root 4096 Feb 16 22:40 targeted
Let us now see how to enable SELinux on the system. We recommend first set the SELINUX mode to permissive and not enforced.
Now edit the SELINUX directive as:
Once you save the file, issue a system reboot.
NOTE: We highly recommend setting the SELINUX directive to permissive before enforcing SELinux.
Once you reboot the system, check for any logs reported by SELinux in /var/log/messages.
Next, ensure you have no errors and enforce SELinux by setting the directive to enforce in /etc/selinux/config
Finally, you can view the SELinux status using the sestatus command:
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: error (Success)
Policy MLS status: enabled
Policy deny_unknown status: allowed
Memory protection checking: actual(secure)
Max kernel policy version: 31
You can also use the setenforce command to switch between various SELinux modes. For example, to set the mode to permissive, use the command:
This mode is temporary and will be restored to one in the config file after a reboot.
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: permissive
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Memory protection checking: actual(secure)
Max kernel policy version: 31
SELinux Policy and Context
To avoid confusion for SELinux beginners, we will not dive deep into how SELinux policies are implemented but simply touch on it to give you an idea.
SELinux works by implementing security policies. An SELinux policy refers to a rule that is used to define access rights for every object in the system. Objects refer to users, processes, files, and roles.
Each context is defined in the form of the user:role:type:level.
For example, create a directory in your home directory and view its SELinux security context as shown in the commands below:
ls –Z ~/ | grep linuxhint
This will display output as shown below:
You may also find other directories with the security contexts as:
You may realize the above output follows the syntax of the user:role:type:level.
Conclusion
That was a beginner’s tutorial to SELinux using CentOS 8. Although the tutorial is designed for beginners, it is more than enough to get your feet running in SELinux and remove the intimidating nature of SELinux.
Thank you for reading.
]]>However, most WordPress users are only familiar with its graphical workflow; very few people have explored its terminal side.
This tutorial will introduce you to WP-CLI, a command-line tool for managing WordPress sites.
Let us dive into the world of WP-CLI:
How to Install WP-CLI
Installing WP-CLI is relatively easy. The tool is in the form of a PHP archive which you can download and execute.
Start by downloading the archive using wget or cURL as:
For cURL users, use the command:
Once downloaded, make the file executable and move the archive to a PATH in your system such as /usr/local/bin as:
To confirm that you have successfully installed it and it’s working, use the command:
This should give you an output similar to the one shown below, indicating that you’ve installed the tool successfully.
NOTE: Ensure you have PHP installed; otherwise, you will get an env error.
WP-CLI vendor dir: phar://wp-cli.phar/vendor
WP_CLI phar path: /home/root
WP-CLI packages dir:
WP-CLI global config:
WP-CLI project config:
WP-CLI version: 2.4.0
How to Use WP-CLI
WP-CLI is a terminal or command line alternative to the wp-admin dashboard. Hence, there is a WP-CLI command for all the tasks you can perform with the WordPress admin web interface.
Let us learn how to use them, but before that:
How to enable WP-CLI Bash Completion
The WP-CLI tool allows you to enable the Bash Completion Feature to view and autocomplete commands using the TAB key. Let us enable it to make our tasks easier.
We begin by downloading the Bash Completion Script with the command:
To load the Bash Completion Script on every terminal session, let us edit our bash profile config file. Enter the following entry in the .bashrc file.
Next, reload the bash profile to load all the changes:
Once completed, you should have Bash Completion enabled. If you are using another shell, perhaps ZSH, check the official documentation for information on how to enable completion.
To test if it is working, enter the command wp + TAB. That should give you all available commands as:
option rewrite shell term cap
cron export maintenance-mode package
role sidebar theme cli db
help media plugin scaffold
site transient comment embed i18n
menu post search-replace super-admin
user config eval import network
post-type server taxonomy widget
Installing WordPress with WP-CLI
Before we get to the WordPress admin, we have to install WordPress first. Let’s discuss how to install it using WP-CLI.
NOTE: Ensure you have a web server and MySQL database installed.
First, log in to MySQL shell and create a database
Enter Password:
Next, we need to create a database:
Next, we need to create a user and grant all privileges as:
GRANT ALL PRIVILEGES ON wp.* TO wpadmin;
FLUSH PRIVILEGES;
The next step is to download the WordPress installation file. For this, we are going to use the /var/www/html directory.
Change to /var/www/html
To ensure we have r/w permission to that directory, chown the www-data user created by apache as:
sudo chown www-data:www-data .
Next, download WordPress using WP-CLI. You will need to invoke the wp command as www-data as the user has to write permission to the /var/www/html directory. Avoid using root.
This will download WordPress and extract it into the current directory. Ignore the error shown below:
Warning: Failed to create directory '/var/www/.wp-cli/cache/': mkdir(): Permission denied.
md5 hash verified: e9377242a433acbb2df963966f98c31d Success: WordPress downloaded.
Confirm you have WordPress installed by listing the contents of the /var/www/html directory:
-rw-r--r-- 1 www-data www-data 405 Feb 5 22:22 index.php
-rw-r--r-- 1 www-data www-data 19915 Feb 5 22:22 license.txt
-rw-r--r-- 1 www-data www-data 7278 Feb 5 22:22 readme.html
-rw-r--r-- 1 www-data www-data 7101 Feb 5 22:22 wp-activate.php drwxr-xr-x 1 www-data www-data 4096 Feb 5 22:23 wp-admin
-rw-r--r-- 1 www-data www-data 351 Feb 5 22:23 wp-blog-header.php
-rw-r--r-- 1 www-data www-data 2328 Feb 5 22:23 wp-comments-post.php
-rw-r--r-- 1 www-data www-data 2913 Feb 5 22:23 wp-config-sample.php drwxr-xr-x 1 www-data www-data 4096 Feb 5 22:23 wp-content
-rw-r--r-- 1 www-data www-data 3939 Feb 5 22:23 wp-cron.php drwxr-xr-x 1 www-data www-data 4096 Feb 5 22:24 wp-includes
Next, we need to generate the WordPress configuration file and add the relevant information. Use the command below and replace the values appropriately.
Once we have all the relevant configuration setup, we can finally run the installer setting up the WordPress user as:
Success: WordPress installed successfully.
With that, you have WordPress installed on the system. You can test the site by navigating to http://localhost, which should display the default WordPress:
How to Manage a WordPress Site with CLI
Now you have an entire WordPress site installed and managed using WP-CLI. How about we try to perform basic tasks such as installing a plugin.
Install a Plugin with WP-CLI
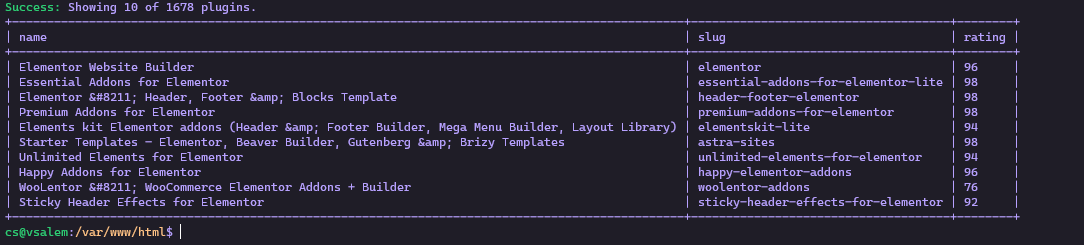
While still in the WordPress site installation directory (/var/www/html), let us search for a plugin to install. Let us use the Elementor Page Builder as an example:
Running this command should give you all the possible plugins in tabular form—as shown below:
Cool right? Now let us see how we can install the plugin once we find the appropriate name.
To install it, use the plugin slug as:
Warning: Failed to create directory '/var/www/.wp-cli/cache/': mkdir(): Permission denied.
Downloading installation package from https://downloads.wordpress.org/plugin/elementor.3.1.1.zip...
Unpacking the package...
Installing the plugin...
Plugin installed successfully.
Success: Installed 1 of 1 plugins.
Once we have successfully installed the plugin we need, we can simply activate it using a similar command as:
Success: Activated 1 of 1 plugins.
Uninstall a Plugin with WP-CLI
If you can install a plugin with WP-CLI, you can uninstall it.
Success: Deactivated 1 of 1 plugins.
Once deactivated, you can uninstall it easily as:
Success: Uninstalled 1 of 1 plugins.
Installing WordPress Themes with WP-CLI
Themes are a common WordPress feature. Let’s discuss how to manage them from the command line.
To search for a theme, use the command:
+--------+--------+--------+
| name | slug | rating |
+--------+--------+--------+
| Astra | astra | 100 |
| Astral | astral | 100 |
+--------+--------+--------+
Once you have the theme you wish to install, use the command as shown below:
Warning: Failed to create directory '/var/www/.wp-cli/cache/': mkdir(): Permission denied.
Downloading installation package from https://downloads.wordpress.org/theme/astra.3.0.2.zip...
Unpacking the package...
Installing the theme...
Theme installed successfully.
Success: Installed 1 of 1 themes.
Once you install the theme, you can activate it with the command:
To install it from a zip file, use the command shown below:
Installing the theme...
Theme installed successfully.
Success: Installed 1 of 1 themes.
Uninstalling a WordPress theme with WP-CLI
To remove a theme with CLI, first, activate another theme and then uninstall the one you want to uninstall using the command:
Deleted ‘astra’ theme.
Success: Deleted 1 of 1 themes.
View Themes and Plugins
To list all the themes and plugins in the WordPress instance, use the commands shown below:
wp plugin list
This command should list available themes and plugins, respectively, as shown below:
| name | status | update | version |
+-----------------+----------+--------+---------+
| oceanwp | active | none | 2.0.2 |
| twentynineteen | inactive | none | 1.9 |
| twentytwenty | inactive | none | 1.6 |
| twentytwentyone | inactive | none | 1.1 |
+-----------------+----------+--------+---------+
+---------+----------+--------+---------+
| name | status | update | version |
+---------+----------+--------+---------+
| akismet | inactive | none | 4.1.8 |
| hello | inactive | none | 1.7.2 |
+---------+----------+--------+---------+
Updating Themes and Plugins with WP-CLI
You can also update plugins and themes using the CLI. For example, to update all themes, use the command;
Success: Theme already updated.
NOTE: You can specify the specific theme name to update a single theme.
Updating WordPress from CLI
When the WordPress team releases a new version, you can update from the command line with a few single commands:
The first step is to update the site’s files first as:
Next, we need to update the database as:
Success: WordPress database already at latest db version 49752.
Creating a WordPress post with CLI
To create a post using WP-CLI, use the command below:
Success: Created post 5.
Deleting a Post
To delete a post, specify its numerical identifier as:
Success: Trashed post 5.
Conclusion
This guide has shown you how you use the powerful WP-CLI to manage a WordPress site from the command line. If you want to learn more about how to work with WordPress CLI, consider the documentation resource provided below:
This tutorial will show you how to use the _cat API to view information about shards in an Elasticsearch cluster, what node the replica is, the size it takes up the disk, and more.
How to List All Shards in a Cluster
To view all the shards in an Elasticsearch cluster, you can use the GE request at the _cat/shards API endpoint, as follows:
If you are a cURL user, use the following command:
Executing the above command will give you information about all the shards in the cluster, as shown below (output truncated):
kibana_sample_data_flights 0 r STARTED 13059 5.3mb 172.28.27.142 instance-0000000001
.slm-history-3-000001 0 p STARTED 172.28.86.133 instance-0000000003
.slm-history-3-000001 0 r STARTED 172.28.27.142 instance-0000000001
destination_index 0 p STARTED 13232 5.9mb 172.28.27.142 instance-0000000001
.monitoring-es-7-2021.01.22 0 p STARTED 279515 153.5mb 172.28.86.133 instance-0000000003
.monitoring-es-7-2021.01.22 0 r STARTED 279467 268.5mb 172.28.27.142 instance-0000000001
.kibana_task_manager_1 0 p STARTED 6 205.6kb 172.28.86.133 instance-0000000003
.kibana_task_manager_1 0 r STARTED 6 871.5kb 172.28.27.142 instance-0000000001
.monitoring-beats-7-2021.01.22 0 p STARTED 6245 8mb 172.28.86.133 instance-0000000003
--------------------------------output truncated---------------------
You can also filter the output and specify the format of the result. For example, to obtain the output in YAML format, add the format=yaml parameter to the request, as follows:
The cURL command for this is:
The output should in YAML format as:
shard: "0"
prirep: "p"
state: "STARTED"
docs: "2"
store: "14.7kb"
ip: "172.28.27.142"
node: "instance-0000000001"
- index: "source_index"
shard: "0"
prirep: "p"
state: "STARTED"
docs: "0"
store: "208b"
ip: "172.28.86.133"
node: "instance-0000000003"
- index: "kibana_sample_type_diff"
shard: "0"
prirep: "p"
state: "STARTED"
docs: "13059"
store: "5.7mb"
ip: "172.28.86.133"
node: "instance-0000000003"
- index: "kibana_sample_type_diff"
shard: "0"
prirep: "r"
state: "STARTED"
docs: "13059"
store: "9.8mb"
ip: "172.28.27.142"
node: "instance-0000000001"
--------------------------------OUTPUT TRUNCATED---------------------
You can even choose to obtain specific headers. For example, to obtain the index name, shard name, shard state, shard disk space, node id, and node IP, filter by passing them to the header argument as:
The cURL command is as follows:
Executing the above command gives you selected information about the shards in the JSON format. Skip the format parameters to use the default tabular format.
{
"index" : "kibana_sample_data_flights",
"shard" : "0",
"state" : "STARTED",
"store" : "5.3mb",
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : "kibana_sample_data_flights",
"shard" : "0",
"state" : "STARTED",
"store" : "5.3mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : ".slm-history-3-000001",
"shard" : "0",
"state" : "STARTED",
"store" : null,
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : ".slm-history-3-000001",
"shard" : "0",
"state" : "STARTED",
"store" : null,
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : "destination_index",
"shard" : "0",
"state" : "STARTED",
"store" : "5.9mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : ".monitoring-es-7-2021.01.22",
"shard" : "0",
"state" : "STARTED",
"store" : "154.7mb",
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : ".monitoring-es-7-2021.01.22",
"shard" : "0",
"state" : "STARTED",
"store" : "270.2mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
-----------------------------------OUTPUT TRUNCATED-------------------------
Shard Information for Specific Indices
T0 0btain information about a shard for a specific index, pass the name of the index as follows:
Input the cURL command as follows:
This command gives you information about the shards of that specific index:
kibana_sample_data_flights 0 r STARTED 13059 5.3mb 172.28.27.142 instance-0000000001
NOTE: You can also use parameters to filter the data above.
Conclusion
In this guide, we showed you how to use the cat API to obtain information about shards running in the Elasticsearch cluster.
]]>Automatic shard rebalancing conforms to restrictions and rules like allocation filtering and forced awareness, leading to the most efficient and well-balanced cluster possible.
NOTE: Do not confuse shard reallocation, which is the process of finding and moving unassigned shards to the nodes in which they reside, with rebalancing. Rebalancing takes assigned shards and moves them evenly to various nodes, the purpose being the equal distribution of shards per node.
How to Enable Automatic Rebalancing
To enable automatic cluster rebalancing in Elasticsearch, we can use the PUT request to_cluster API endpoint and add the settings we need.
The settings available for dynamic shard rebalancing include:
- cluster.routing.rebalance.enable: Controls automatic rebalancing for various shard types, such as:
- All: Sets enable shard rebalancing for all indices.
- None: Disables shard rebalance for all indices.
- Replicas: Only replica shard rebalance is allowed.
- Primary: Only primary shard rebalancing is allowed.
- cluster.routing.allocation.allow_rebalance: Sets the value for shard rebalancing. Options include:
- Always: Enables rebalancing indefinitely.
- Indices_primaries_active: Allows rebalancing only when all primary shards in the cluster are allocated.
- Indices_all_active: Allows rebalancing when only the shards in the cluster are allocated. This includes both the primary and the replica shards.
- cluster.routing.allocation.cluster.concurrent.rebalance: This option sets the number of concurrent rebalances allowed in the cluster. The default value is 2.
Consider the request below to allow automatic shard rebalancing for the cluster.
{
"persistent": {
"cluster.routing.rebalance.enable": "primaries",
"cluster.routing.allocation.allow_rebalance": "always" ,
"cluster.routing.allocation.cluster_concurrent_rebalance":"2"
}
}
The following is the cURL command:
This command should return a response as the JSON object acknowledges the settings that are updated.
“acknowledged”: true,
"persistent" : {
"cluster" : {
"routing" : {
"rebalance" : {
"enable" : "primaries"
},
"allocation" : {
"allow_rebalance" : "always",
"cluster_concurrent_rebalance" : "2"
}
}
}
},
"transient" : { }
}
Manual Index Rebalancing
You can also rebalance a shard manually for a specific index. I would not recommend this option because the Elasticsearch default rebalancing options are very efficient.
However, should the need to perform manual rebalancing arise, you can use the following request:
“acknowledged”: true,
"persistent" : {
"cluster" : {
"routing" : {
"rebalance" : {
"enable" : "primaries"
},
"allocation" : {
"allow_rebalance" : "always",
"cluster_concurrent_rebalance" : "2"
}
}
}
},
"transient" : { }
}
The cURL command is:
NOTE: Keep in mind that if you perform a manual rebalance, Elasticsearch may move the shards automatically to ensure the best rebalance possible.
Conclusion
This guide walked you through updating and modifying the settings for an Elasticsearch cluster to enable automatic shard rebalancing. The article also covered manual rebalancing, if you require it.
]]>However, as you know, once data gets mapped into an index, it’s unmodifiable. To do this, you will need to reindex the data with the modifications you require. This process may lead to downtime, which is not a very good practice, especially for a service that is already in circulation.
To circumvent this, we can use index aliases, which allow us to switch between indices seamlessly.
How to Create an Index?
The first step is to ensure you have an existing index that you wish to update the data.
For this tutorial, we will have an old and new index that will function as their names.
{
"settings": {
"number_of_shards": 1
},
"aliases": {
"use_me": {}
},
“mappings”: {
"properties": {
"name":{
"type": "text"
},
"id":{
"type": "integer"
},
"paid": {
"type": "boolean"
}
}
}
}
For cURL users, use the appended command:
Next, create a new index that we are going to use. Copy all the settings and mappings from the old index as:
{
"settings": {
"number_of_shards": 1
},
"aliases": {
"use_me": {}
},
“mappings”: {
"properties": {
"name":{
"type": "text"
},
"id":{
"type": "integer"
},
"paid": {
"type": "object"
}
}
}
}
Here’s the cURL command:
Having the setting and mappings in the new index, use the reindex api to copy the data from the old index to the new one:
{
“source”: {
"index": "old_index"
},
"dest": {
"index": "new_index"
}
}
Here’s the cURL command:
Now, copy the alias of the old index to the new one using the _alias api as:
{
"actions" : [
{ "add" : { "index" : "new_index", "alias" : "use_me" } }
]
}
Here’s the cURL command:
Once completed, you can now remove the old index, and the applications will use the new index (due to the alias) with no downtime.
Conclusion
Once you master the concepts discussed in this tutorial, you will be in a position to reindex data from an old index to a new one in place.
]]>Working with databases is very fun but can sometimes be challenging, especially when dealing with already-existing data.
For example, if you want to change the type of a specific field, it might require you to take the service down, which can have grave repercussions, especially in services that process large amounts of data.
Fortunately, we can use Elasticsearch’s powerful features such as Reindexing, ingest nodes, pipelines, and processors to make such tasks very easy.
This tutorial will show you how to change a field type in a specific index to another, using Elasticsearch Ingest nodes. Using this approach will eliminate downtime that affects services while still managing to perform the field type change tasks.
Introduction to Ingest Nodes
Elasticsearch’s ingest node allows you to pre-process documents before their indexing.
An Elasticsearch node is a specific instance of Elasticsearch; connected nodes (more than one) make a single cluster.
You can view the nodes available in the running cluster with the request:
The cURL command for this is:
Executing this command should give you massive information about the nodes, as shown below (truncated output):
"_nodes" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"cluster_name" : "22e0bee6ef91461d82d9b0f1b4b13b4a",
"nodes" : {
"gSlMjTKyTemoOX-EO7Em4w" : {
"name" : "instance-0000000003",
"transport_address" : "172.28.86.133:19925",
"host" : "172.28.86.133",
"ip" : "172.28.86.133",
"version" : "7.10.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"total_indexing_buffer" : 214748364,
"roles" : [
"data",
"data_cold",
"data_content",
"data_hot",
"data_warm",
"ingest",
"master",
"remote_cluster_client",
“transform”
],
"attributes" : {
"logical_availability_zone" : "zone-0",
"server_name" : "instance-0000000003.22e0bee6ef91461d82d9b0f1b4b13b4a",
"availability_zone" : "us-west-1c",
"xpack.installed" : "true",
"instance_configuration" : "aws.data.highio.i3",
"transform.node" : "true",
"region" : "us-west-1"
},
"settings" : {
"s3" : {
"client" : {
"elastic-internal-22e0be" : {
"endpoint" : "s3-us-west-1.amazonaws.com"
}
}
},
--------------------------------output truncated---------------------
By default, all Elasticsearch nodes enable ingest and are capable of handling ingest operations. However, for heavy ingest operations, you can create a single node dedicated to ingesting only.
To handle pre_process, before indexing the documents, we need to define a pipeline that states the preprocessors series.
Preprocessors are sets of instructions wrapped around a pipeline and are executed one at a time.
The following is the general syntax of how to define a pipeline:
"description" : "Convert me",
"processors" : [{
"convert" : {
"field" : "id",
"type": "integer"
} ]
}
The description property says what the pipeline should achieve. The next parameter is the preprocessors, passed on as a list in the order of their execution.
Create a Convert Pipeline
To create a pipeline that we will use to convert a type, use the PUT request with the _ingest API endpoint as:
{
“description”: “converts the field dayOfWeek field to a long from integer”,
"processors" : [
{
"convert" : {
"field" : "dayOfWeek",
"type": "long"
}
}
]
}
For cURL, use the command:
Reindex and Convert Type
Once we have the pipeline in the ingest node, all we need to do is call the indexing API and pass the pipeline as an argument in the dest of the request body as:
{
“source”: {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "kibana_sample_type_diff",
"pipeline": "convert_pipeline"
}
}
For cURL:
Verify Conversion
To verify that the pipeline has applied correctly, use the GET request to fetch that specific field as:
GET /kibana_sample_type_diff/_mapping/field/dayOfWeek
This should return the data as:
{
"kibana_sample_data_flights" : {
"mappings" : {
"dayOfWeek" : {
"full_name" : "dayOfWeek",
"mapping" : {
"dayOfWeek" : {
"type" : "integer"
}
}
}
}
}
}
-------------------------REINDEXED DATA-------------------------------
{
"kibana_sample_type_diff" : {
"mappings" : {
"dayOfWeek" : {
"full_name" : "dayOfWeek",
"mapping" : {
"dayOfWeek" : {
"type" : "long"
}
}
}
}
}
}
Conclusion
In this guide, we have looked at how to work with Elasticsearch Ingest nodes to pre-process documents before indexing, thus converting a field from one type to another.
Consider the documentation to learn more.
https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html
]]>In this quick guide, we will examine how to enable Elasticsearch Xpack security features and how to use security API to create users and roles.
Let us get started!
NOTE: We are assuming you already have Elasticsearch installed and running on your system. If not, consider the following tutorials to install Elasticsearch.
https://linuxhint.com/visualize_apache_logs_with_elk_stack/
https://linuxhint.com/install-elasticsearch-ubuntu/
How to Enable Elasticsearch Security Features?
By default, Elasticsearch Features, Xpack, are disabled, and you will need to enable them. First, stop Elasticsearch and Kibana, so you can edit the configuration.
In the Elasticsearch configuration file, edit the xpack.security.enabled entry and set it to true.
By default, you’ll find the elasticsearch.yml located in /etc/elasticsearch.
Save the file and restart Elasticsearch and Kibana.
NOTE: Depending on the license you have, once you’ve activated xpack, you will need to run the command below to set up passwords and authentication:
How to Create Users Using Kibana?
If you have Elasticsearch and Kibana coupled, you can easily create users in the Kibana stack management.
Start by launching Kibana, then log in. Use the passwords you used when setting up.
Once logged in, select the Kibana Dock and navigate to Stack Management and the security section.
Now, navigate to users and click on “create user.” When creating a user, Kibana will ask you to assign a role. You can view all available roles in Stack Management – Security –Roles.
Provide the username, password, and full name.
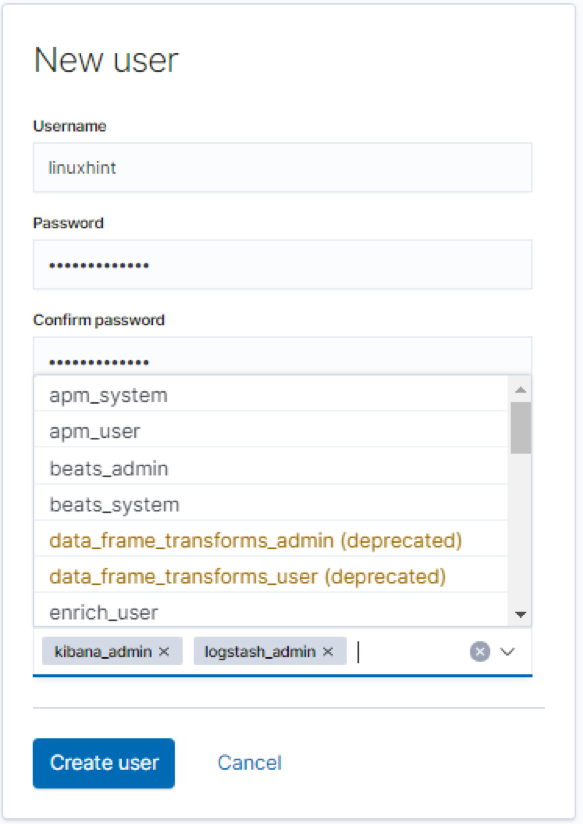
Besides this simple way to create Elasticsearch users, you can use the more powerful method discussed below:
How to Create Users with Elasticsearch API?
Another way to create native users in Elasticsearch is to use the API, using {security} as the endpoint, we can add, update, and remove users in Elasticsearch.
Let us look at how to carry out these operations.
To interact with the security API, we use POST and PUT HTTP requests, making sure we have the user information in the request’s body.
When creating a new user, you must pass the user’s username and password; both are required parameters. Elasticsearch usernames must not be more than 1024 characters and can be alphanumeric. Usernames do not allow whitespaces.
The information you can provide in the request body include:
- Password: This is a required parameter of type string. Passwords in Elasticsearch must be at least six characters long.
- Full_name: This specifies the full name of the user (String).
- Email: This sets the email of the specified user.
- Roles: This is another required parameter of the type list. It specifies the roles the specified user holds. You can create an empty list [] if the user does not have any assigned roles.
- Enabled: The enabled parameter (Boolean) specifies if the user is active or not.
Once you have the body of the request containing it, send the post request to _security/user/<username>.
Consider the request below that shows how to create a user using API.
{
"password" : "linuxhint",
"enabled": true,
"roles" : [ "superuser", "kibana_admin" ],
"full_name" : "Linux Hint",
"email" : "[email protected]",
"metadata" : {
"intelligence" : 7
}
}
If you’re using cURL, enter the command below:
This should return created: true as a JSON object.
"created" : true
}
How to Enable User Information?
If you create a user in Elasticsearch and set the enabled parameter as false, you will need to enable the account before using it. To do this, we can use the _enable API.
You should ensure to pass the username you wish to enable in the PUT request. The general syntax is as:
For example, the request below enables the user linuxhint:
The cURL command is:
The reverse is also true; to disable a user, use the _disable endpoint:
The cURL command is:
How to View Users?
To view user information, use the GET request followed by the username you wish to view. For example:
The cURL command is:
That should display information about the specified username, as shown below:
"linuxhint" : {
"username" : "linuxhint",
"roles" : [
“superuser”,
“kibana_admin”
],
"full_name" : "Linux Hint",
"email" : "[email protected]",
"metadata" : {
"intelligence" : 7
},
"enabled" : false
}
}
To view information about all the users in the Elasticsearch cluster, omit the username and send the GET request as:
How to Delete Users?
If you can create users, you can delete them too. To use the API to remove a user, simply send the DELETE request to _security/user/<username>.
Example:
The cURL command is:
That should return a JSON object with found:true as:
"found" : true
}
Conclusion
This tutorial taught you how to enable Elasticsearch Security features. We also discussed how to use Kibana Stack Management to manage users. Finally, we discussed how to create users, view user information, and delete users.
This information should get you started but remember that mastery comes from practice.
Thank you for reading.
]]>When you’re modifying data in an Elasticsearch index, it can lead to downtime as the functionality gets completed and the data gets reindexed.
This tutorial will give you a much better way of updating indices without experiencing any downtime with the existing data source. Using the Elasticsearch re-indexing API, we will copy data from a specific source to another.
Let us get started.
NOTE: Before we get started, Reindexing operations are resource-heavy, especially on large indices. To minimize the time required for Reindexing, disable number_of_replicas by setting the value to 0 and enable them once the process is complete.
Enable _Source Field
The Reindexing operation requires the source field to be enabled on all the documents in the source index. Note that the source field is not indexed and cannot be searched but is useful for various requests.
Enable the _Source field by adding an entry as shown below:
{
“mappings”: {
"_source": {
"enabled": true
}
}
}
Reindex All Documents
To reindex documents, we need to specify the source and destination. Source and destination can be an existing index, index alias, and data streams. You can use indices from the local or a remote cluster.
NOTE: For indexing to occur successfully, both source and destination cannot be similar. You must also configure the destination as required before Reindexing because it does not apply settings from the source or any associated template.
The general syntax for Reindexing is as:
Let us start by creating two indices. The first one will be the source, and the other one will be the destination.
{
"settings": {"number_of_replicas": 0, "number_of_shards": 1},
"mappings": {"_source": {"enabled": true}},"aliases": {
"alias_1": {},
"alias_2": {
"filter": {"term": {
"user.id": "kibana"
}},"routing": "1"
}
}
}
The cURL command is:
Now for the destination index (you can use the above command and change a few things or use the one given below):
{
"settings": {"number_of_replicas": 0, "number_of_shards": 1},
"mappings": {"_source": {"enabled": true}},"aliases": {
"alias_3": {},
"alias_4": {
"filter": {"term": {
"user.id": "kibana"
}},"routing": "1"
}
}
}
As always, cURL users can use the command:
Now, we have the indices that we want to use, we can then move on to reindex the documents.
Consider the request below that copies the data from source_index to destination_index:
{
“source”: {
"index": "source_index"
},
"dest": {
"index": "destination_index"
}
}
The cURL command for this is:
Executing this command should give you detailed information about the operation carried out.
NOTE: The source_index should have data.
"took" : 2836,
"timed_out" : false,
"total" : 13059,
"updated" : 0,
"created" : 13059,
"deleted" : 0,
"batches" : 14,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
Checking Reindexing Status
You can view the status of the Reindexing operations by simply using the _tasks. For example, consider the request below:
The cURL command is:
That should give you detailed information about the Reindexing process as shown below:
"tasks" : {
"FTd_2iXjSXudN_Ua4tZhHg:51847" : {
"node" : "FTd_2iXjSXudN_Ua4tZhHg",
"id" : 51847,
"type" : "transport",
"action" : "indices:data/write/reindex",
"status" : {
"total" : 13059,
"updated" : 9000,
"created" : 0,
"deleted" : 0,
"batches" : 10,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0
},
"description" : "reindex from [source_index] to [destination_index][_doc]",
"start_time_in_millis" : 1611247308063,
"running_time_in_nanos" : 2094157836,
"cancellable" : true,
"headers" : { }
}
}
}
Conclusion
We’ve covered everything you need to know about using Elasticsearch Reindexing API to copy documents from one index (source) to another (destination). Although there is more to the Reindexing API, this guide should help you get started.
]]>This tutorial discusses the art of using Elasticsearch CAT API to view detailed information about indices in the cluster. This information should help you manage how the clusters are performing and what actions to take.
You may already know that Elasticsearch loves JSON and uses it for all its APIs. However, displayed information or data is only useful to you when it’s in a simple, well-organized form; JSON might not accomplish this very well. Thus, Elasticsearch does not recommend using CAT API with applications but for human reading only.
With that out of the way, let’s dive in!
How to View High-Level Information about Indices?
To get high-level information about an Elasticsearch index, we use the_cat API. For example, to view information about a specific cluster, use the command:
You can also use the cRUL command:
Once you execute the request above, you will get information about the specified index. This information may include:
- Number of shards
- Documents available in the index
- Number of deleted documents in the index
- The primary size
- The total size of all the index shards (replicas included)
The _cat API can also fetch high-level information about all indices in a cluster, for example:
For cURL users, enter the command:
This should display information about all indices in the cluster, as shown below:
green open .monitoring-beats-7-2021.01.21 iQZnVRaNQg-m7lkeEKA8Bw 1 1 3990 0 7mb 3.4mb
green open elastic-cloud-logs-7-2021.01.20-000001 cAVZV5d1RA-GeonwMej5nA 1 1 121542 0 43.4mb 21.4mb
green open .triggered_watches FyLc7T7wSxSW9roVJxyiPA 1 1 0 0 518.7kb 30.1kb
green open apm-7.10.2-onboarding-2021.01.20 zz-RRPjXQ1WGZIrRiqsLOQ 1 1 2 0 29.4kb 14.7kb
green open kibana_sample_data_flights 9nA2U3m7QX2g9u_JUFsgXQ 1 1 13059 0 10.6mb 5.3mb
green open .monitoring-kibana-7-2021.01.21 WiGi5NaaTdyUUyKSBgNx9w 1 1 6866 0 3.1mb 1.7mb
green open .monitoring-beats-7-2021.01.20 1Lx1vaQdTx2lEevMH1N3lg 1 1 4746 0 8mb 4mb
------------------------------------OUTPUT TRUNCATED-------------------------
How to Filter Required Information?
In most cases, you will only need specific information about indices. To accomplish this, you can use _cat API parameters.
For example, to get only the UUID of the index, size, and health status, you can use the h parameter to accomplish this. For example, consider the request below:
The cURL command for this example is:
That should display filtered information for all indices in the cluster. Here’s an example output:
YFRPjV8wQju_ZZupE1s12g green 416b
iQZnVRaNQg-m7lkeEKA8Bw green 7.1mb
cAVZV5d1RA-GeonwMej5nA green 44.1mb
FyLc7T7wSxSW9roVJxyiPA green 518.7kb
zz-RRPjXQ1WGZIrRiqsLOQ green 29.4kb
9nA2U3m7QX2g9u_JUFsgXQ green 10.6mb
WiGi5NaaTdyUUyKSBgNx9w green 3.9mb
QdXSZTY8TA2mDyJ5INSaHg green 2.8mb
1Lx1vaQdTx2lEevMH1N3lg green 8mb
aBlLAWhPRXap32EqrKMPXA green 67.7kb
Bg2VT1QpT4CSjnwe1hnq_w green 416b
aoWhhWu9QsWW4T5CY_XWZw green 416b
6SAhoYJaS_6y_u8AZ0m3KQ green 416b
Wco9drGpSn67zYME6wFCEQ green 485.5kb
eN2loWymSpqLlC2-ElYm1Q green 416b
K5C9TeLcSy69SsUdtkyGOg green 40.2kb
bUDul_72Rw6_9hWMagiSFQ green 3.1mb
c7dOH6MQQUmHM2MKJ73ekw green 416b
aoTRvqdfR8-dGjCmcKSmjw green 48.9kb
IG7n9JghR1ikeCk7BqlaqA green 416b
BWAbxK06RoOSmL_KiPe09w green 12.5kb
feAUC7k2RiKrEws9iveZ0w green 4.6mb
F73wTiN2TUiAVcm2giAUJA green 416b
hlhLemJ5SnmiQUPYU2gQuA green 416b
jbUeUWFfR6y2TKb-6tEh6g green 416b
2ZyqPCAaTia0ydcy2jZd3A green 304.5kb
---------------------------------OUTPUT TRUNCATED----------------------------
How to Get All Index Metrics?
Suppose you want detailed statistics for a specific index. In such cases, you can use the _stats endpoint to query the data. For example, to get detailed information about an index called temp_2, use the request:
You can also use cURL as:
An example statistic information should be as shown below:
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_all" : {
"primaries" : {
"docs" : {
"count" : 0,
"deleted" : 0
},
"store" : {
"size_in_bytes" : 208,
"reserved_in_bytes" : 0
},
"indexing" : {
"index_total" : 0,
"index_time_in_millis" : 0,
"index_current" : 0,
"index_failed" : 0,
"delete_total" : 0,
"delete_time_in_millis" : 0,
"delete_current" : 0,
"noop_update_total" : 0,
"is_throttled" : false,
"throttle_time_in_millis" : 0
},
"get" : {
"total" : 0,
"time_in_millis" : 0,
"exists_total" : 0,
"exists_time_in_millis" : 0,
"missing_total" : 0,
"missing_time_in_millis" : 0,
"current" : 0
},
-----------------------------OUTPUT TRUNCATED------------------------------
Conclusion
In this quick tutorial, we have learned how to use Elasticsearch API to get information about single or multiple indices within a cluster. We also learned how to filter data to get only the required values. You can learn more by checking the _cat and _stats API.
For more Elasticsearch tutorials, search the site.
Thank you for reading.
]]>