This tutorial will show you how to use the _cat API to view information about shards in an Elasticsearch cluster, what node the replica is, the size it takes up the disk, and more.
How to List All Shards in a Cluster
To view all the shards in an Elasticsearch cluster, you can use the GE request at the _cat/shards API endpoint, as follows:
If you are a cURL user, use the following command:
Executing the above command will give you information about all the shards in the cluster, as shown below (output truncated):
kibana_sample_data_flights 0 r STARTED 13059 5.3mb 172.28.27.142 instance-0000000001
.slm-history-3-000001 0 p STARTED 172.28.86.133 instance-0000000003
.slm-history-3-000001 0 r STARTED 172.28.27.142 instance-0000000001
destination_index 0 p STARTED 13232 5.9mb 172.28.27.142 instance-0000000001
.monitoring-es-7-2021.01.22 0 p STARTED 279515 153.5mb 172.28.86.133 instance-0000000003
.monitoring-es-7-2021.01.22 0 r STARTED 279467 268.5mb 172.28.27.142 instance-0000000001
.kibana_task_manager_1 0 p STARTED 6 205.6kb 172.28.86.133 instance-0000000003
.kibana_task_manager_1 0 r STARTED 6 871.5kb 172.28.27.142 instance-0000000001
.monitoring-beats-7-2021.01.22 0 p STARTED 6245 8mb 172.28.86.133 instance-0000000003
--------------------------------output truncated---------------------
You can also filter the output and specify the format of the result. For example, to obtain the output in YAML format, add the format=yaml parameter to the request, as follows:
The cURL command for this is:
The output should in YAML format as:
shard: "0"
prirep: "p"
state: "STARTED"
docs: "2"
store: "14.7kb"
ip: "172.28.27.142"
node: "instance-0000000001"
- index: "source_index"
shard: "0"
prirep: "p"
state: "STARTED"
docs: "0"
store: "208b"
ip: "172.28.86.133"
node: "instance-0000000003"
- index: "kibana_sample_type_diff"
shard: "0"
prirep: "p"
state: "STARTED"
docs: "13059"
store: "5.7mb"
ip: "172.28.86.133"
node: "instance-0000000003"
- index: "kibana_sample_type_diff"
shard: "0"
prirep: "r"
state: "STARTED"
docs: "13059"
store: "9.8mb"
ip: "172.28.27.142"
node: "instance-0000000001"
--------------------------------OUTPUT TRUNCATED---------------------
You can even choose to obtain specific headers. For example, to obtain the index name, shard name, shard state, shard disk space, node id, and node IP, filter by passing them to the header argument as:
The cURL command is as follows:
Executing the above command gives you selected information about the shards in the JSON format. Skip the format parameters to use the default tabular format.
{
"index" : "kibana_sample_data_flights",
"shard" : "0",
"state" : "STARTED",
"store" : "5.3mb",
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : "kibana_sample_data_flights",
"shard" : "0",
"state" : "STARTED",
"store" : "5.3mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : ".slm-history-3-000001",
"shard" : "0",
"state" : "STARTED",
"store" : null,
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : ".slm-history-3-000001",
"shard" : "0",
"state" : "STARTED",
"store" : null,
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : "destination_index",
"shard" : "0",
"state" : "STARTED",
"store" : "5.9mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
{
"index" : ".monitoring-es-7-2021.01.22",
"shard" : "0",
"state" : "STARTED",
"store" : "154.7mb",
"id" : "gSlMjTKyTemoOX-EO7Em4w",
"ip" : "172.28.86.133"
},
{
"index" : ".monitoring-es-7-2021.01.22",
"shard" : "0",
"state" : "STARTED",
"store" : "270.2mb",
"id" : "FTd_2iXjSXudN_Ua4tZhHg",
"ip" : "172.28.27.142"
},
-----------------------------------OUTPUT TRUNCATED-------------------------
Shard Information for Specific Indices
T0 0btain information about a shard for a specific index, pass the name of the index as follows:
Input the cURL command as follows:
This command gives you information about the shards of that specific index:
kibana_sample_data_flights 0 r STARTED 13059 5.3mb 172.28.27.142 instance-0000000001
NOTE: You can also use parameters to filter the data above.
Conclusion
In this guide, we showed you how to use the cat API to obtain information about shards running in the Elasticsearch cluster.
]]>Automatic shard rebalancing conforms to restrictions and rules like allocation filtering and forced awareness, leading to the most efficient and well-balanced cluster possible.
NOTE: Do not confuse shard reallocation, which is the process of finding and moving unassigned shards to the nodes in which they reside, with rebalancing. Rebalancing takes assigned shards and moves them evenly to various nodes, the purpose being the equal distribution of shards per node.
How to Enable Automatic Rebalancing
To enable automatic cluster rebalancing in Elasticsearch, we can use the PUT request to_cluster API endpoint and add the settings we need.
The settings available for dynamic shard rebalancing include:
- cluster.routing.rebalance.enable: Controls automatic rebalancing for various shard types, such as:
- All: Sets enable shard rebalancing for all indices.
- None: Disables shard rebalance for all indices.
- Replicas: Only replica shard rebalance is allowed.
- Primary: Only primary shard rebalancing is allowed.
- cluster.routing.allocation.allow_rebalance: Sets the value for shard rebalancing. Options include:
- Always: Enables rebalancing indefinitely.
- Indices_primaries_active: Allows rebalancing only when all primary shards in the cluster are allocated.
- Indices_all_active: Allows rebalancing when only the shards in the cluster are allocated. This includes both the primary and the replica shards.
- cluster.routing.allocation.cluster.concurrent.rebalance: This option sets the number of concurrent rebalances allowed in the cluster. The default value is 2.
Consider the request below to allow automatic shard rebalancing for the cluster.
{
"persistent": {
"cluster.routing.rebalance.enable": "primaries",
"cluster.routing.allocation.allow_rebalance": "always" ,
"cluster.routing.allocation.cluster_concurrent_rebalance":"2"
}
}
The following is the cURL command:
This command should return a response as the JSON object acknowledges the settings that are updated.
“acknowledged”: true,
"persistent" : {
"cluster" : {
"routing" : {
"rebalance" : {
"enable" : "primaries"
},
"allocation" : {
"allow_rebalance" : "always",
"cluster_concurrent_rebalance" : "2"
}
}
}
},
"transient" : { }
}
Manual Index Rebalancing
You can also rebalance a shard manually for a specific index. I would not recommend this option because the Elasticsearch default rebalancing options are very efficient.
However, should the need to perform manual rebalancing arise, you can use the following request:
“acknowledged”: true,
"persistent" : {
"cluster" : {
"routing" : {
"rebalance" : {
"enable" : "primaries"
},
"allocation" : {
"allow_rebalance" : "always",
"cluster_concurrent_rebalance" : "2"
}
}
}
},
"transient" : { }
}
The cURL command is:
NOTE: Keep in mind that if you perform a manual rebalance, Elasticsearch may move the shards automatically to ensure the best rebalance possible.
Conclusion
This guide walked you through updating and modifying the settings for an Elasticsearch cluster to enable automatic shard rebalancing. The article also covered manual rebalancing, if you require it.
]]>However, as you know, once data gets mapped into an index, it’s unmodifiable. To do this, you will need to reindex the data with the modifications you require. This process may lead to downtime, which is not a very good practice, especially for a service that is already in circulation.
To circumvent this, we can use index aliases, which allow us to switch between indices seamlessly.
How to Create an Index?
The first step is to ensure you have an existing index that you wish to update the data.
For this tutorial, we will have an old and new index that will function as their names.
{
"settings": {
"number_of_shards": 1
},
"aliases": {
"use_me": {}
},
“mappings”: {
"properties": {
"name":{
"type": "text"
},
"id":{
"type": "integer"
},
"paid": {
"type": "boolean"
}
}
}
}
For cURL users, use the appended command:
Next, create a new index that we are going to use. Copy all the settings and mappings from the old index as:
{
"settings": {
"number_of_shards": 1
},
"aliases": {
"use_me": {}
},
“mappings”: {
"properties": {
"name":{
"type": "text"
},
"id":{
"type": "integer"
},
"paid": {
"type": "object"
}
}
}
}
Here’s the cURL command:
Having the setting and mappings in the new index, use the reindex api to copy the data from the old index to the new one:
{
“source”: {
"index": "old_index"
},
"dest": {
"index": "new_index"
}
}
Here’s the cURL command:
Now, copy the alias of the old index to the new one using the _alias api as:
{
"actions" : [
{ "add" : { "index" : "new_index", "alias" : "use_me" } }
]
}
Here’s the cURL command:
Once completed, you can now remove the old index, and the applications will use the new index (due to the alias) with no downtime.
Conclusion
Once you master the concepts discussed in this tutorial, you will be in a position to reindex data from an old index to a new one in place.
]]>Working with databases is very fun but can sometimes be challenging, especially when dealing with already-existing data.
For example, if you want to change the type of a specific field, it might require you to take the service down, which can have grave repercussions, especially in services that process large amounts of data.
Fortunately, we can use Elasticsearch’s powerful features such as Reindexing, ingest nodes, pipelines, and processors to make such tasks very easy.
This tutorial will show you how to change a field type in a specific index to another, using Elasticsearch Ingest nodes. Using this approach will eliminate downtime that affects services while still managing to perform the field type change tasks.
Introduction to Ingest Nodes
Elasticsearch’s ingest node allows you to pre-process documents before their indexing.
An Elasticsearch node is a specific instance of Elasticsearch; connected nodes (more than one) make a single cluster.
You can view the nodes available in the running cluster with the request:
The cURL command for this is:
Executing this command should give you massive information about the nodes, as shown below (truncated output):
"_nodes" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"cluster_name" : "22e0bee6ef91461d82d9b0f1b4b13b4a",
"nodes" : {
"gSlMjTKyTemoOX-EO7Em4w" : {
"name" : "instance-0000000003",
"transport_address" : "172.28.86.133:19925",
"host" : "172.28.86.133",
"ip" : "172.28.86.133",
"version" : "7.10.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"total_indexing_buffer" : 214748364,
"roles" : [
"data",
"data_cold",
"data_content",
"data_hot",
"data_warm",
"ingest",
"master",
"remote_cluster_client",
“transform”
],
"attributes" : {
"logical_availability_zone" : "zone-0",
"server_name" : "instance-0000000003.22e0bee6ef91461d82d9b0f1b4b13b4a",
"availability_zone" : "us-west-1c",
"xpack.installed" : "true",
"instance_configuration" : "aws.data.highio.i3",
"transform.node" : "true",
"region" : "us-west-1"
},
"settings" : {
"s3" : {
"client" : {
"elastic-internal-22e0be" : {
"endpoint" : "s3-us-west-1.amazonaws.com"
}
}
},
--------------------------------output truncated---------------------
By default, all Elasticsearch nodes enable ingest and are capable of handling ingest operations. However, for heavy ingest operations, you can create a single node dedicated to ingesting only.
To handle pre_process, before indexing the documents, we need to define a pipeline that states the preprocessors series.
Preprocessors are sets of instructions wrapped around a pipeline and are executed one at a time.
The following is the general syntax of how to define a pipeline:
"description" : "Convert me",
"processors" : [{
"convert" : {
"field" : "id",
"type": "integer"
} ]
}
The description property says what the pipeline should achieve. The next parameter is the preprocessors, passed on as a list in the order of their execution.
Create a Convert Pipeline
To create a pipeline that we will use to convert a type, use the PUT request with the _ingest API endpoint as:
{
“description”: “converts the field dayOfWeek field to a long from integer”,
"processors" : [
{
"convert" : {
"field" : "dayOfWeek",
"type": "long"
}
}
]
}
For cURL, use the command:
Reindex and Convert Type
Once we have the pipeline in the ingest node, all we need to do is call the indexing API and pass the pipeline as an argument in the dest of the request body as:
{
“source”: {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "kibana_sample_type_diff",
"pipeline": "convert_pipeline"
}
}
For cURL:
Verify Conversion
To verify that the pipeline has applied correctly, use the GET request to fetch that specific field as:
GET /kibana_sample_type_diff/_mapping/field/dayOfWeek
This should return the data as:
{
"kibana_sample_data_flights" : {
"mappings" : {
"dayOfWeek" : {
"full_name" : "dayOfWeek",
"mapping" : {
"dayOfWeek" : {
"type" : "integer"
}
}
}
}
}
}
-------------------------REINDEXED DATA-------------------------------
{
"kibana_sample_type_diff" : {
"mappings" : {
"dayOfWeek" : {
"full_name" : "dayOfWeek",
"mapping" : {
"dayOfWeek" : {
"type" : "long"
}
}
}
}
}
}
Conclusion
In this guide, we have looked at how to work with Elasticsearch Ingest nodes to pre-process documents before indexing, thus converting a field from one type to another.
Consider the documentation to learn more.
https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html
]]>In this quick guide, we will examine how to enable Elasticsearch Xpack security features and how to use security API to create users and roles.
Let us get started!
NOTE: We are assuming you already have Elasticsearch installed and running on your system. If not, consider the following tutorials to install Elasticsearch.
https://linuxhint.com/visualize_apache_logs_with_elk_stack/
https://linuxhint.com/install-elasticsearch-ubuntu/
How to Enable Elasticsearch Security Features?
By default, Elasticsearch Features, Xpack, are disabled, and you will need to enable them. First, stop Elasticsearch and Kibana, so you can edit the configuration.
In the Elasticsearch configuration file, edit the xpack.security.enabled entry and set it to true.
By default, you’ll find the elasticsearch.yml located in /etc/elasticsearch.
Save the file and restart Elasticsearch and Kibana.
NOTE: Depending on the license you have, once you’ve activated xpack, you will need to run the command below to set up passwords and authentication:
How to Create Users Using Kibana?
If you have Elasticsearch and Kibana coupled, you can easily create users in the Kibana stack management.
Start by launching Kibana, then log in. Use the passwords you used when setting up.
Once logged in, select the Kibana Dock and navigate to Stack Management and the security section.
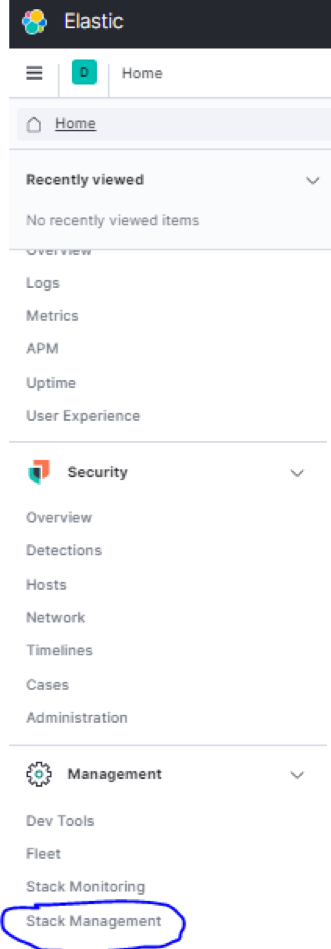
Now, navigate to users and click on “create user.” When creating a user, Kibana will ask you to assign a role. You can view all available roles in Stack Management – Security –Roles.
Provide the username, password, and full name.
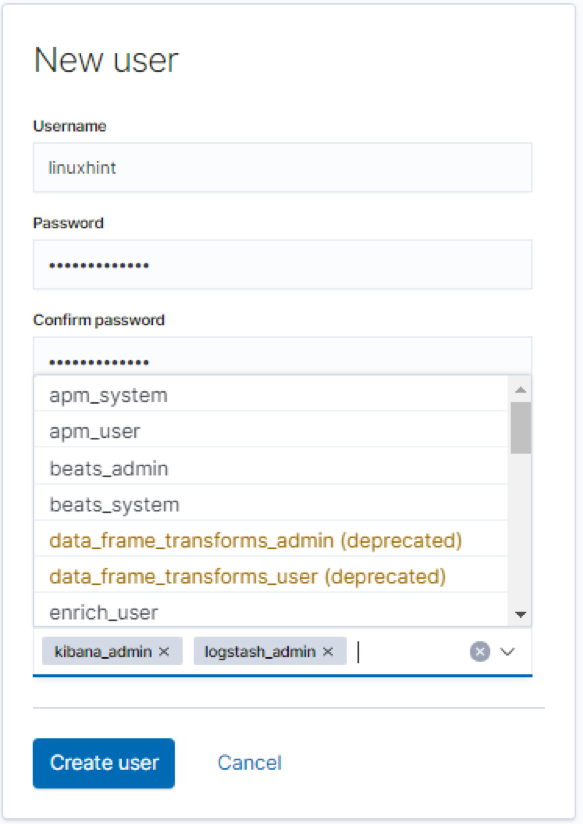
Besides this simple way to create Elasticsearch users, you can use the more powerful method discussed below:
How to Create Users with Elasticsearch API?
Another way to create native users in Elasticsearch is to use the API, using {security} as the endpoint, we can add, update, and remove users in Elasticsearch.
Let us look at how to carry out these operations.
To interact with the security API, we use POST and PUT HTTP requests, making sure we have the user information in the request’s body.
When creating a new user, you must pass the user’s username and password; both are required parameters. Elasticsearch usernames must not be more than 1024 characters and can be alphanumeric. Usernames do not allow whitespaces.
The information you can provide in the request body include:
- Password: This is a required parameter of type string. Passwords in Elasticsearch must be at least six characters long.
- Full_name: This specifies the full name of the user (String).
- Email: This sets the email of the specified user.
- Roles: This is another required parameter of the type list. It specifies the roles the specified user holds. You can create an empty list [] if the user does not have any assigned roles.
- Enabled: The enabled parameter (Boolean) specifies if the user is active or not.
Once you have the body of the request containing it, send the post request to _security/user/<username>.
Consider the request below that shows how to create a user using API.
{
"password" : "linuxhint",
"enabled": true,
"roles" : [ "superuser", "kibana_admin" ],
"full_name" : "Linux Hint",
"email" : "[email protected]",
"metadata" : {
"intelligence" : 7
}
}
If you’re using cURL, enter the command below:
This should return created: true as a JSON object.
"created" : true
}
How to Enable User Information?
If you create a user in Elasticsearch and set the enabled parameter as false, you will need to enable the account before using it. To do this, we can use the _enable API.
You should ensure to pass the username you wish to enable in the PUT request. The general syntax is as:
For example, the request below enables the user linuxhint:
The cURL command is:
The reverse is also true; to disable a user, use the _disable endpoint:
The cURL command is:
How to View Users?
To view user information, use the GET request followed by the username you wish to view. For example:
The cURL command is:
That should display information about the specified username, as shown below:
"linuxhint" : {
"username" : "linuxhint",
"roles" : [
“superuser”,
“kibana_admin”
],
"full_name" : "Linux Hint",
"email" : "[email protected]",
"metadata" : {
"intelligence" : 7
},
"enabled" : false
}
}
To view information about all the users in the Elasticsearch cluster, omit the username and send the GET request as:
How to Delete Users?
If you can create users, you can delete them too. To use the API to remove a user, simply send the DELETE request to _security/user/<username>.
Example:
The cURL command is:
That should return a JSON object with found:true as:
"found" : true
}
Conclusion
This tutorial taught you how to enable Elasticsearch Security features. We also discussed how to use Kibana Stack Management to manage users. Finally, we discussed how to create users, view user information, and delete users.
This information should get you started but remember that mastery comes from practice.
Thank you for reading.
]]>When you’re modifying data in an Elasticsearch index, it can lead to downtime as the functionality gets completed and the data gets reindexed.
This tutorial will give you a much better way of updating indices without experiencing any downtime with the existing data source. Using the Elasticsearch re-indexing API, we will copy data from a specific source to another.
Let us get started.
NOTE: Before we get started, Reindexing operations are resource-heavy, especially on large indices. To minimize the time required for Reindexing, disable number_of_replicas by setting the value to 0 and enable them once the process is complete.
Enable _Source Field
The Reindexing operation requires the source field to be enabled on all the documents in the source index. Note that the source field is not indexed and cannot be searched but is useful for various requests.
Enable the _Source field by adding an entry as shown below:
{
“mappings”: {
"_source": {
"enabled": true
}
}
}
Reindex All Documents
To reindex documents, we need to specify the source and destination. Source and destination can be an existing index, index alias, and data streams. You can use indices from the local or a remote cluster.
NOTE: For indexing to occur successfully, both source and destination cannot be similar. You must also configure the destination as required before Reindexing because it does not apply settings from the source or any associated template.
The general syntax for Reindexing is as:
Let us start by creating two indices. The first one will be the source, and the other one will be the destination.
{
"settings": {"number_of_replicas": 0, "number_of_shards": 1},
"mappings": {"_source": {"enabled": true}},"aliases": {
"alias_1": {},
"alias_2": {
"filter": {"term": {
"user.id": "kibana"
}},"routing": "1"
}
}
}
The cURL command is:
Now for the destination index (you can use the above command and change a few things or use the one given below):
{
"settings": {"number_of_replicas": 0, "number_of_shards": 1},
"mappings": {"_source": {"enabled": true}},"aliases": {
"alias_3": {},
"alias_4": {
"filter": {"term": {
"user.id": "kibana"
}},"routing": "1"
}
}
}
As always, cURL users can use the command:
Now, we have the indices that we want to use, we can then move on to reindex the documents.
Consider the request below that copies the data from source_index to destination_index:
{
“source”: {
"index": "source_index"
},
"dest": {
"index": "destination_index"
}
}
The cURL command for this is:
Executing this command should give you detailed information about the operation carried out.
NOTE: The source_index should have data.
"took" : 2836,
"timed_out" : false,
"total" : 13059,
"updated" : 0,
"created" : 13059,
"deleted" : 0,
"batches" : 14,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
Checking Reindexing Status
You can view the status of the Reindexing operations by simply using the _tasks. For example, consider the request below:
The cURL command is:
That should give you detailed information about the Reindexing process as shown below:
"tasks" : {
"FTd_2iXjSXudN_Ua4tZhHg:51847" : {
"node" : "FTd_2iXjSXudN_Ua4tZhHg",
"id" : 51847,
"type" : "transport",
"action" : "indices:data/write/reindex",
"status" : {
"total" : 13059,
"updated" : 9000,
"created" : 0,
"deleted" : 0,
"batches" : 10,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0
},
"description" : "reindex from [source_index] to [destination_index][_doc]",
"start_time_in_millis" : 1611247308063,
"running_time_in_nanos" : 2094157836,
"cancellable" : true,
"headers" : { }
}
}
}
Conclusion
We’ve covered everything you need to know about using Elasticsearch Reindexing API to copy documents from one index (source) to another (destination). Although there is more to the Reindexing API, this guide should help you get started.
]]>This tutorial discusses the art of using Elasticsearch CAT API to view detailed information about indices in the cluster. This information should help you manage how the clusters are performing and what actions to take.
You may already know that Elasticsearch loves JSON and uses it for all its APIs. However, displayed information or data is only useful to you when it’s in a simple, well-organized form; JSON might not accomplish this very well. Thus, Elasticsearch does not recommend using CAT API with applications but for human reading only.
With that out of the way, let’s dive in!
How to View High-Level Information about Indices?
To get high-level information about an Elasticsearch index, we use the_cat API. For example, to view information about a specific cluster, use the command:
You can also use the cRUL command:
Once you execute the request above, you will get information about the specified index. This information may include:
- Number of shards
- Documents available in the index
- Number of deleted documents in the index
- The primary size
- The total size of all the index shards (replicas included)
The _cat API can also fetch high-level information about all indices in a cluster, for example:
For cURL users, enter the command:
This should display information about all indices in the cluster, as shown below:
green open .monitoring-beats-7-2021.01.21 iQZnVRaNQg-m7lkeEKA8Bw 1 1 3990 0 7mb 3.4mb
green open elastic-cloud-logs-7-2021.01.20-000001 cAVZV5d1RA-GeonwMej5nA 1 1 121542 0 43.4mb 21.4mb
green open .triggered_watches FyLc7T7wSxSW9roVJxyiPA 1 1 0 0 518.7kb 30.1kb
green open apm-7.10.2-onboarding-2021.01.20 zz-RRPjXQ1WGZIrRiqsLOQ 1 1 2 0 29.4kb 14.7kb
green open kibana_sample_data_flights 9nA2U3m7QX2g9u_JUFsgXQ 1 1 13059 0 10.6mb 5.3mb
green open .monitoring-kibana-7-2021.01.21 WiGi5NaaTdyUUyKSBgNx9w 1 1 6866 0 3.1mb 1.7mb
green open .monitoring-beats-7-2021.01.20 1Lx1vaQdTx2lEevMH1N3lg 1 1 4746 0 8mb 4mb
------------------------------------OUTPUT TRUNCATED-------------------------
How to Filter Required Information?
In most cases, you will only need specific information about indices. To accomplish this, you can use _cat API parameters.
For example, to get only the UUID of the index, size, and health status, you can use the h parameter to accomplish this. For example, consider the request below:
The cURL command for this example is:
That should display filtered information for all indices in the cluster. Here’s an example output:
YFRPjV8wQju_ZZupE1s12g green 416b
iQZnVRaNQg-m7lkeEKA8Bw green 7.1mb
cAVZV5d1RA-GeonwMej5nA green 44.1mb
FyLc7T7wSxSW9roVJxyiPA green 518.7kb
zz-RRPjXQ1WGZIrRiqsLOQ green 29.4kb
9nA2U3m7QX2g9u_JUFsgXQ green 10.6mb
WiGi5NaaTdyUUyKSBgNx9w green 3.9mb
QdXSZTY8TA2mDyJ5INSaHg green 2.8mb
1Lx1vaQdTx2lEevMH1N3lg green 8mb
aBlLAWhPRXap32EqrKMPXA green 67.7kb
Bg2VT1QpT4CSjnwe1hnq_w green 416b
aoWhhWu9QsWW4T5CY_XWZw green 416b
6SAhoYJaS_6y_u8AZ0m3KQ green 416b
Wco9drGpSn67zYME6wFCEQ green 485.5kb
eN2loWymSpqLlC2-ElYm1Q green 416b
K5C9TeLcSy69SsUdtkyGOg green 40.2kb
bUDul_72Rw6_9hWMagiSFQ green 3.1mb
c7dOH6MQQUmHM2MKJ73ekw green 416b
aoTRvqdfR8-dGjCmcKSmjw green 48.9kb
IG7n9JghR1ikeCk7BqlaqA green 416b
BWAbxK06RoOSmL_KiPe09w green 12.5kb
feAUC7k2RiKrEws9iveZ0w green 4.6mb
F73wTiN2TUiAVcm2giAUJA green 416b
hlhLemJ5SnmiQUPYU2gQuA green 416b
jbUeUWFfR6y2TKb-6tEh6g green 416b
2ZyqPCAaTia0ydcy2jZd3A green 304.5kb
---------------------------------OUTPUT TRUNCATED----------------------------
How to Get All Index Metrics?
Suppose you want detailed statistics for a specific index. In such cases, you can use the _stats endpoint to query the data. For example, to get detailed information about an index called temp_2, use the request:
You can also use cURL as:
An example statistic information should be as shown below:
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_all" : {
"primaries" : {
"docs" : {
"count" : 0,
"deleted" : 0
},
"store" : {
"size_in_bytes" : 208,
"reserved_in_bytes" : 0
},
"indexing" : {
"index_total" : 0,
"index_time_in_millis" : 0,
"index_current" : 0,
"index_failed" : 0,
"delete_total" : 0,
"delete_time_in_millis" : 0,
"delete_current" : 0,
"noop_update_total" : 0,
"is_throttled" : false,
"throttle_time_in_millis" : 0
},
"get" : {
"total" : 0,
"time_in_millis" : 0,
"exists_total" : 0,
"exists_time_in_millis" : 0,
"missing_total" : 0,
"missing_time_in_millis" : 0,
"current" : 0
},
-----------------------------OUTPUT TRUNCATED------------------------------
Conclusion
In this quick tutorial, we have learned how to use Elasticsearch API to get information about single or multiple indices within a cluster. We also learned how to filter data to get only the required values. You can learn more by checking the _cat and _stats API.
For more Elasticsearch tutorials, search the site.
Thank you for reading.
]]>Luckily, with Elasticsearch, when data become redundant, all you need to do is access a tool to perform requests and transfer data over the network.
This quick guide will show you how to use the mighty Elasticsearch API to delete documents and indices.
NOTE: We assume you have Elasticsearch running on your system and that you have a tool for making requests such as cURL. We also provide raw Kibana requests if you are using the Kibana Console (recommended).
How to List Index?
If you want to delete and index in Elasticsearch, you first need to verify it exists before sending the DELETE request.
If you try to delete a non-existing index, you will get an error, similar to the one shown below:
For cURL command:
Deleting an index will give an error as:
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [this_index_does_not_exist]",
"index_uuid" : "_na_",
"resource.type" : "index_or_alias",
"resource.id" : "this_index_does_not_exist",
"index" : "this_index_does_not_exist"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [this_index_does_not_exist]",
"index_uuid" : "_na_",
"resource.type" : "index_or_alias",
"resource.id" : "this_index_does_not_exist",
"index" : "this_index_does_not_exist"
},
"status" : 404
}
There are various ways to check if an index exists; the best is to list its name. For example, you can use wildcards to match a specific name.
The example request below lists indices with names te*
The cURL command is:
This command should return all the indices matching that specific pattern, allowing you to remember only the partial name of the index you wish to remove.
"temp" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "temp",
"creation_date" : "1611180802266",
"number_of_replicas" : "1",
"uuid" : "c7dOH6MQQUmHM2MKJ73ekw",
"version" : {
"created" : "7100299"
}
}
}
},
"temp_1" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "temp_1",
"creation_date" : "1611180811874",
"number_of_replicas" : "1",
"uuid" : "pq1UUR2XTZS3xfs6Hxr4gg",
"version" : {
"created" : "7100299"
}
}
}
},
"temp_2" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "temp_2",
"creation_date" : "1611180815041",
"number_of_replicas" : "1",
"uuid" : "8NdXWPuBTLe6r4eZ407W9Q",
"version" : {
"created" : "7100299"
}
}
}
}
}
Another way is to add the ignore_unavailable parameter to the request. For example:
For cURL users:
[cc lang="text" width="100%" height="100%" escaped="true" theme="blackboard" nowrap="0"]
curl -XDELETE “http://localhost:9200/ignore_me?ignore_unavailable=true”
How to Delete an Index?
Once you have the index you wish to remove from Elasticsearch, use the DELETE request followed by the index name.
The general syntax is:
The index name can be a specific index or a wildcard that selects a group of indices. Ensure to use wildcards correctly; otherwise, you might remove the wrong indices.
NOTE: Deleting Elasticsearch indices using aliases is disallowed.
Consider the example request below that removes the temp_1 index:
For cURL command:
Executing this command should respond with a JSON object, indicating the successful removal of the index.
“acknowledged”: true
}
Elasticsearch is smart enough to know that you can remove indices accidentally. Therefore, you can set what types of wildcard expressions are allowed.
These type of wildcards expressions include:
- All: Includes all indices, including open, closed, and hidden (starting with)
- Open: Includes open indices only
- Closed: Includes closed indices only
- None: No wildcard expressions allowed.
Conclusion
For this quick and simple guide, we discussed the process of using Elasticsearch to delete indices from a cluster. We also discussed simple ways you can implement to avoid errors for indices that do not exist.
Thank you for reading.
]]>This tutorial will walk you through the ins and outs of Elasticsearch index templates that allow you to define templates or blueprints for common indices. For example, if you are constantly logging data from external sources, you can define a blueprint for all logging indices.
NOTE: Before we begin, it is good to note that the tutorial focuses on the latest version of Elasticsearch—7.8 at the time of writing—and it may vary from other versions. We also assume that you have Elasticsearch running on a system somewhere.
Let us get started working with Elasticsearch index templates.
What is An Elasticsearch Index Template?
An Elasticsearch index template is a method used to instruct Elasticsearch to configure indices upon creation. For example, an index template used on a data stream configures the stream’s backing indices upon creation. An index template is created manually before index creation. When creating an index, the template applies the configuration settings for the index.
The latest version of Elasticsearch has two types of usable templates. One is the index template, and the other is component templates. As we have already established, index templates help create Elasticsearch indices.
Component templates are reusable modules or blocks used to configure settings, mapping, and aliases. Component templates do not get applied directly to the created indices but can help create index templates.
Some default index templates used by Elasticsearch include: metrics-*-*, logs-*-* .
How to Create an Index Template
To create new index templates or update existing ones, we use the PUT template API. Using the _index_template endpoint, we can send an HTTP request to add a template.
The general syntax for creating a template is:
It is good to note that the template name is a required parameter. Consider the request below that creates an index template as template_1
{
/* Define the index pattern */
"index_patterns" : ["te*"],
"priority" : 1,
/* Define settings for the indices*/
"template": {
"settings" : {
"number_of_shards" : 2
}
}
}
For cURL users, the command is:
Elasticsearch uses a wildcard pattern to match index names where the templates are applied. Changing or updating an index template does not affect already created indices only the ones which will be created after using that template.
From above, you can comment on your templates using the C-Language commenting method. You can add as many comments as you want, anywhere in the body except the curly braces’ opening.
In the body of an index template, you can include various definition such as:
- Template: The template property (object) defines which template to be applied; it can include aliases, mappings, and settings—this an optional parameter.
- Composed_of: This property defines a list of names for component templates. Once defined, component templates get compounded in their specification order. That means the last component template defined takes the highest precedence.
- Priority: The priority property defines the precedence of the index template when creating an index. If any precedence has the highest value, it gets higher precedence compared to lower values. The priority value is not required and is of type integer. 0 is the default value for non-specified templates.
- Version: The version parameter specifies the index template version, which helps to manage the templates.
There are other properties you can include in the index template body. Consider the documentation to learn more.
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/index-templates.html
Below is an example request to create a new template with version 1.0
{
"index_patterns" : ["remp*", "re*"],
"priority" : 1,
"template": {
"settings" : {
"number_of_shards" : 2,
"number_of_replicas": 0
}
},
"version": 1.0
}
You cannot have more than one index template with a matching pattern and the same priority. Hence, ensure to assign different priorities to match pattern templates.
How to Get Index Template
To view information about an index template, send a GET request to the _index_template API. For example, to view information about template_2, use the request:
The cURL command is:
This command should display information about template_2
"index_templates" : [
{
"name" : "template_2",
"index_template" : {
"index_patterns" : [
"remp*",
"re*"
],
"template" : {
"settings" : {
"index" : {
"number_of_shards" : "2",
"number_of_replicas" : "0"
}
}
},
"composed_of" : [ ],
"priority" : 1,
"version" : 1
}
}
]
}
You can also use wildcards to get matching templates. For example, consider the request below to view all templates in Elasticsearch.
The cURL command is.
This command should give you information about all templates in Elasticsearch
"index_templates" : [
{
"name" : "ilm-history",
"index_template" : {
"index_patterns" : [
"ilm-history-3*"
],
"template" : {
"settings" : {
"index" : {
"format" : "1",
"lifecycle" : {
"name" : "ilm-history-ilm-policy",
"rollover_alias" : "ilm-history-3"
},
"hidden" : "true",
"number_of_shards" : "1",
"auto_expand_replicas" : "0-1",
"number_of_replicas" : "0"
}
},
"mappings" : {
"dynamic" : false,
"properties" : {
"index_age" : {
"type" : "long"
},
"@timestamp" : {
"format" : "epoch_millis",
"type" : "date"
},
"error_details" : {
"type" : "text"
},
"success": {
"type" : "boolean"
},
"index" : {
"type" : "keyword"
},
"state" : {
"dynamic" : true,
"type" : "object",
--------------------------OUTPUT TRUNCATED-----------------------------------
How to Delete Templates
Deleting a template is just as simple as the GET template but using DELETE request as:
You can use the cURL command:
This command automatically deletes the specified template.
Conclusion
This tutorial covered what Elasticsearch index templates are, how they work, and how to create, view, and delete index templates. This basic information should help you get started on using Elasticsearch index templates.
]]>To help safeguard against data loss, Elasticsearch has various features that allow you to ensure data availability, even in data failure instances.
Some of the ways that Elasticsearch uses to provide you with data availability include:
- Cross-cluster replications, a feature that allows you to replicate data to a set of follower clusters; a follower cluster is a standby cluster used in case of failure from the master cluster.
- Another method that Elasticsearch uses to prevent data using backups—also called cluster snapshots. If the need arises, you can use these snapshots to restore data on a completely new cluster.
This tutorial shows you how to create cluster snapshots, which will help you be ready should an irreversible data failure event occur.
Let’s get started.
What is An Elasticsearch Snapshot?
As mentioned, an elastic snapshot is a backup copy of a running Elasticsearch cluster. This snapshot can be of an entire cluster or specific indices and data streams within a particular cluster.
As you will soon learn, a repository plugin manages Elasticsearch snapshots. These snapshots are storable in various storage locations defined by the plugin. These include local systems and remote systems such as GCP Storage, Amazon EC2, Microsoft Azure, and many more.
How to Create An Elasticsearch Snapshot Repository
Before we dive into creating Elasticsearch snapshots, we need to create a snapshot repository because many of Elasticsearch’s services use the Snapshot API to perform these tasks.
Some of the tasks handled by the Snapshot API are:
- Put snapshot repository
- Verify snapshot repository
- Get snapshot repository
- Delete snapshot repository
- Clean up snapshot repository
- Create snapshot
- Clone snapshot
- Get snapshot
- Get snapshot status
- Restore snapshot
- Delete snapshot
To create a snapshot repository, we use the _snapshot API endpoint followed by the name we want to assign to the snapshot repository. Consider the request below that creates a repository called backup_repo
{
"type": "fs",
"settings": {
"location": "/home/root/backups",
"compress": true
}
}
Here’s a cURL command for the above request:
To pass the snapshot repository path, you must first add the system’s path or the parent directory to the path.repo entry in elasticsearch.yml
The path.repo entry should look similar to:
You can find the Elasticsearch configuration file located in /etc/elasticsearch/elasticsearch.yml
NOTE: After adding the path.repo, you may need to restart Elasticsearch clusters. Additionally, the values supported for path.repo may vary wildly depending on the platform running Elasticsearch.
How to View the Snapshot Repository
To confirm the successful creation of the snapshot repository, use the GET request with the _snapshot endpoint as:
You can also use the following cURL command:
This should display information about the backup repository, for example:
"backup_repo" : {
"type" : "fs",
"settings" : {
"compress" : "true",
"location" : """/home/root/backups"""
}
}
}
If you have more than one snapshot repositories and do not remember the name, you can omit the repo name and call the _snapshot endpoint to list all the existing repositories.
GET /_snapshot or cURL curl -XGET http://localhost:9200/_snapshot
How to Create an Elasticsearch Snapshot
Creating an Elasticsearch snapshot for a specific snapshot repository is handled by the create snapshot API. The API requires the snapshot repository name and the name of the snapshot.
NOTE: A single snapshot repository can have more than one snapshot of the same clusters as long as they have unique identities/names.
Consider the following request to add a snapshot called snapshot_2021 to the backup_repo repository.
To use cURL, use the command:
The command should return a response from Elasticsearch with 200 OK and accepted: true
"accepted" : true
}
Since it does not specify which data streams and indices you want to have backed up, calling the above request backups all the data and the cluster state. To specify which data streams and indices to back up, add that to the request body.
Consider the following request that backups the .kibana index (a system index) and specifies which user authorized the snapshot and the reason.
{
"indices": ".kibana",
"ignore_unavailable": true,
"include_global_state": true,
"metadata": {
"taken_by": "elasticadmin",
“taken_because”: “Daily Backup”
}
}
The cURL command for that is:
The ignore_unavailable sets a Boolean state that returns an error if any data streams or indices specified in the snapshot are missing or closed.
The include_global_state parameter saves the cluster’s current state if true. Some of the cluster information saved include:
- Persistent cluster settings
- Index templates
- Legacy index templates
- Ingest pipelines
- ILM lifecycle policies
NOTE: You can specify more than one indices separated by commas.
A common argument used with the _snapshot endpoint is wait_for_completion, a Boolean value defining whether (true) or not (false) the request should return immediately after snapshot initialization (default) or wait for a snapshot completion.
For example:
{
"indices": ".kibana",
"ignore_unavailable": true,
"include_global_state": false,
"metadata": {
"taken_by": "elasticadmin",
“taken_because”: “Weekly Backup”
}
}
The cURL command is:
When you have the wait_for_completion parameter set to true, you’ll give an output similar to the one shown below:
"snapshot" : {
"snapshot" : "snapshot_3",
"uuid" : "tQUHyofIRnGMMtw0AGBACQ",
"version_id" : 7100299,
"version" : "7.10.2",
"indices" : [
".kibana_1"
],
"data_streams" : [ ],
"include_global_state" : false,
"metadata" : {
"taken_by" : "elasticadmin",
“taken_because”: “Weekly Backup”
},
"state" : "SUCCESS",
"start_time" : "2021-01-19T13:36:59.615Z",
"start_time_in_millis" : 1611063419615,
"end_time" : "2021-01-19T13:37:00.433Z",
"end_time_in_millis" : 1611063420433,
"duration_in_millis" : 818,
"failures" : [ ],
"shards" : {
"total" : 1,
"failed" : 0,
"successful" : 1
}
}
}
How to View Snapshots
The GET snapshot API handles the view snapshots functionality.
All you need to pass in the request is the snapshot repository and the name of the snapshot you wish to view the details.
The snapshot should respond with details about a specified snapshot. These details include:
- Start and end time values
- The version of Elasticsearch that created the snapshot
- List of included indices
- The snapshot’s current state
- List of failures that occurred during the snapshot
For example, to view the details about the snapshot_3 created above, use the request shown below:
To use cURL, use the command below:
[cc lang="text" width="100%" height="100%" escaped="true" theme="blackboard" nowrap="0"]
curl -XGET “http://localhost:9200/_snapshot/backup_repo/snapshot_3”
The request should return a response with the details of the snapshot as:
"snapshots" : [
{
"snapshot" : "snapshot_3",
"uuid" : "tQUHyofIRnGMMtw0AGBACQ",
"version_id" : 7100299,
"version" : "7.10.2",
"indices" : [
".kibana_1"
],
"data_streams" : [ ],
"include_global_state" : false,
"metadata" : {
"taken_by" : "elasticadmin",
“taken_because”: “Weekly Backup”
},
"state" : "SUCCESS",
"start_time" : "2021-01-19T13:36:59.615Z",
"start_time_in_millis" : 1611063419615,
"end_time" : "2021-01-19T13:37:00.433Z",
"end_time_in_millis" : 1611063420433,
"duration_in_millis" : 818,
"failures" : [ ],
"shards" : {
"total" : 1,
"failed" : 0,
"successful" : 1
}
}
]
}
You can also customize the request body to get specific details about a snapshot. However, we will not look into that for now.
Let us say you want to view information about all snapshots in a specific snapshot repository; in that case, you can pass an asterisk wildcard in the request as:
The cURL command for that is:
The response is a detailed dump of all the snapshots in that repository as:
"snapshots" : [
{
"snapshot" : "snapshot_2021",
"uuid" : "7CFigHzvRtyZW07c60d2iw",
"version_id" : 7100299,
"version" : "7.10.2",
"indices" : [
"my_index",
"single_index_with_body",
"my_index_2",
"single_index",
".kibana_1",
“test”
],
"data_streams" : [ ],
"include_global_state" : true,
"state" : "SUCCESS",
"start_time" : "2021-01-19T13:28:48.172Z",
"start_time_in_millis" : 1611062928172,
"end_time" : "2021-01-19T13:28:50.831Z",
"end_time_in_millis" : 1611062930831,
"duration_in_millis" : 2659,
"failures" : [ ],
"shards" : {
"total" : 7,
"failed" : 0,
"successful" : 7
}
},
{
"snapshot" : "snapshot_2",
"uuid" : "w58IrYmORAub8VC7cg04Wg",
"version_id" : 7100299,
"version" : "7.10.2",
"indices" : [
".kibana_1"
],
"data_streams" : [ ],
"include_global_state" : false,
"metadata" : {
"taken_by" : "elasticadmin",
"taken_because" : "Daily Backup"
},
"state" : "SUCCESS",
"start_time" : "2021-01-19T13:33:34.482Z",
"start_time_in_millis" : 1611063214482,
"end_time" : "2021-01-19T13:33:35.921Z",
"end_time_in_millis" : 1611063215921,
"duration_in_millis" : 1439,
"failures" : [ ],
"shards" : {
"total" : 1,
"failed" : 0,
"successful" : 1
}
},
{
"snapshot" : "snapshot_3",
"uuid" : "tQUHyofIRnGMMtw0AGBACQ",
"version_id" : 7100299,
"version" : "7.10.2",
"indices" : [
".kibana_1"
],
"data_streams" : [ ],
"include_global_state" : false,
"metadata" : {
"taken_by" : "elasticadmin",
“taken_because”: “Weekly Backup”
},
"state" : "SUCCESS",
"start_time" : "2021-01-19T13:36:59.615Z",
"start_time_in_millis" : 1611063419615,
"end_time" : "2021-01-19T13:37:00.433Z",
"end_time_in_millis" : 1611063420433,
"duration_in_millis" : 818,
"failures" : [ ],
"shards" : {
"total" : 1,
"failed" : 0,
"successful" : 1
}
}
]
}
Wildcards are very useful for filtering specific information about the snapshots.
Deleting a snapshot is very simple: all you have to do is use the DELETE request as:
The cURL command is:
The response should be acknowledged:true
“acknowledged”: true
}
If the snapshot does not exist, you will get a 404 status code and snapshot missing error as:
"error" : {
"root_cause" : [
{
"type" : "snapshot_missing_exception",
"reason" : "[backup_repo:snapshot_2021] is missing"
}
],
"type" : "snapshot_missing_exception",
"reason" : "[backup_repo:snapshot_2021] is missing"
},
"status" : 404
}
Conclusion
In this guide, we have discussed how to create Elasticsearch snapshots using the Snapshot API. What you’ve learned should be enough to allow you to create a snapshot repository, view the snapshot repositories, create, view, and delete snapshots. Although there’re customizations you can make with the API, the knowledge in this guide should be enough to get you started.
Thank you for reading.
]]>In this quick tutorial, we will look at Elasticsearch, specifically how to create indices in the Elasticsearch engine. Although you do not need any comprehensive knowledge about ELK stack to follow this tutorial, having a basic understanding of the following topics might be advantageous:
- Using the terminal, specifically, cURL
- Basic knowledge of APIs and JSON
- Making HTTP Request
NOTE: This tutorial also assumes that you have Elasticsearch installed and running on your system.
What Are Elasticsearch Indices?
Without oversimplifying or overcomplicating things, an Elasticsearch index is a collection of related JSON documents.
As mentioned in a previous post, Elasticsearch indices are JSON objects—considered the base unit of storage in Elasticsearch. These related JSON documents are stored in a single unit that makes up an index. Think of Elasticsearch documents as tables in a relational database.
Let’s relate an Elasticsearch index as a database in the SQL world.
- MySQL => Databases => Tables => Columns/Rows
- Elasticsearch => Indices => Types => JSON Documents with Properties
How to Create an Elasticsearch Index
Elasticsearch uses a powerful and intuitive REST API to expose its services. This functionality allows you to use HTTP requests to perform operations on the Elasticsearch cluster. Therefore, we will use the create index API to create a new index.
For this guide, we will use cURL to send the requests and preserve integrity and usability for all users. However, if you encounter errors with cURL, consider using Kibana Console.
The syntax for creating a new index in Elasticsearch cluster is:
To create an index, all you have to do is pass the index name without other parameters, which creates an index using default settings.
You can also specify various features of the index, such as in the index body:
- The settings for the index
- Index aliases
- Mappings for index fields
The index name is a required parameter; otherwise, you will get an error for the URIL (/)
{"error":"Incorrect HTTP method for uri [/] and method [PUT], allowed: [DELETE, HEAD, GET]","status":405}
To create a new index with the name single_index, we pass the request:
For cURL, use the command:
This command should result in HTTP Status 200 OK and a message with acknowledged: true as:
“acknowledged”: true,
"shards_acknowledged" : true,
"index" : "single_index"
}
The request above creates an index single_index with default settings as we did not specify any configurations.
Index Naming Rules
When creating names for Elasticsearch indices, you must adhere to the following naming standards:
- The index name must be in lower case only.
- The index names cannot start with a dash (-), an underscore (_), or an addition sign (+)
- The names cannot be . or ..
- Index names cannot include special characters such as: \, /, *, ?, “, <, >, |, ` ` (space character), ,, #
- The length of index names must be less than 255 bytes. Multi-byte characters will count in the total length of the index name. For example, if a single character is 8 bytes in length, the total remaining length of the name is 255 – 8
- In the latest version of Elasticsearch, names that start with a . are reserved for hidden indices and internal indices used by Elasticsearch plugins.
How to Create an Index Body
When using the PUT request to create an index, you can pass various arguments that define the settings for the index you want to have created. Values you can specify in the body include:
- Aliases: Specifies alias names for the index you want to have created; this parameter is optional.
- Settings: This defines the configuration options for the index you want to have created. If you fail to specify any parameters, the index gets created using default configurations.
- Mappings: This defines the mapping for fields in the index. The specifications you can include in mappings include:
- The field name
- The data type
- The mapping parameter
For an example of creating an index with body configurations, consider the request below:
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
},
“mappings”: {
"properties": {
"field1": { "type": "object" }
}
}
}
For a cURL equivalent request:
The above request creates a new index with the name single_index_with_body with 2 numbers of shards and 2 replicas. It also creates a mapping with a field of name field1 and type as a JSON object.
Once you send the request, you will get a response with the status of the request as:
“acknowledged”: true,
"shards_acknowledged" : true,
"index" : "single_index_with_body"
}
“Acknowledged” shows whether the index was successfully created in the cluster, while “shards_acknowledged” shows whether the required number of shard copies were started for every shard in the specified index before time out.
How to View Elasticsearch Index
To view the information about the index you created, use a similar request to that of creating an index, but use the HTTP method instead of PUT as:
For cURL,
This command will give you detailed information about the requested index as:
"single_index_with_body" : {
"aliases" : { },
"mappings" : {
"properties" : {
"field1" : {
"type" : "object"
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "2",
"provided_name" : "single_index_with_body",
"creation_date" : "1611045687208",
"number_of_replicas" : "2",
"uuid" : "3TRkO7xmQcSUOOGtb6pXVA",
"version" : {
"created" : "7100299"
}
}
}
}
}
Conclusion
This guide discussed how to work with Elasticsearch to create index API to create new indices. We also discussed how to create suitable names for the indices and configuration settings.
By using this guide, you can now create and view indices using the Elasticsearch API.
]]>What Is Elasticsearch?
Elasticsearch is a free and open-source search and analytic engine used to collect, manage, and analyze data.
Elasticsearch is a comprehensive tool that uses Apache Lucene to process text, numerical, structured, and unstructured geospatial data. Elasticsearch uses a simple and very powerful REST API that allows users to configure and manage it. When coupled with other tools such as Kibana and Logstash, it is one of the most popular real-time and Data Analysis Engines.
Once data is collected from sources like system logs, metrics, application data, etc., it gets added to Elasticsearch and indexed, allowing you to perform complex data queries and create summaries and informative dashboards using visualization tools like Kibana.
What Is Elasticsearch Index?
Having ironed out what Elasticsearch is, let’s talk about one of the most important things about Elastic: an index.
In Elasticsearch, an index refers to a collection of closely related documents in the form of JSON data. The JSON data correlates the keys with corresponding values to their keys.
Here’s an example of a JSON document:
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "json_doc"
}
}
Elasticsearch indexes are in the form of an inverted index, which Elasticsearch search using full-texts. An inverted index works by listing all the unique words in any Elasticsearch document and accurately matches the document in which the word transpires.
The Inverted indexing feature provided by Elasticsearch also allows for real-time search and can be updated using the Elasticsearch indexing API.
How To Create An Index Alias
Elasticsearch exposes its services and functionality using a very Powerful REST API. Using this API, we can create an alias for an Elasticsearch Index.
What is an Index alias?
An Elastisearch index alias is a secondary name or identifier we can use to reference one or more indices.
Once you create an index alias, you can reference the index or indices in Elasticsearch APIs.
An example of an appropriate index would be indices that store system logs for apache. If you regularly query apache logs, you can create an alias for apache_logs, and query and update that specific index.
To create an alias for a particular index, we use the PUT request followed by the index’s path and the alias to create.
In REST, we use a PUT method to request the passed entity or value to get stored at the request URL. Simply put, an HTTP PUT method allows you to update information about a resource or create a new entry if none exists.
For this tutorial, I am assuming you have Elasticsearch installed, and you have an API client or a tool to send HTTP requests such as cURL.
Let us start by creating a simple index with no alias or parameters.
For simplicity, we will use cURL as we assume you have only installed Elasticsearch without Kibana. However, if you have Kibana installed or encounter errors when using curl, consider using the Kibana Console because it’s better suited for Elasticsearch API requests.
This command creates a simple index using default settings and returns the following.
“acknowledged”: true,
“shards_acknowledged”: true,
"index": "my_index"
}
Now that we have an index in Elasticsearch, we can create an alias using the same PUT request as:
We start by specifying the method, in this case, a PUT followed by the URL of the index to which we want to add an alias. The next is the API we want to use, in this case, the Index Alias API (_alias) followed by the name of the alias we want to assign to the index.
Here’s the cURL command for that:
This command should respond with 200 OK status and “acknowledged”:
“acknowledged”: true
}
You may also come across a method to add an alias to an index as:
{
"actions" : [
{ "add" : { "index" : "my_index", "alias" : "my_alias_1" } }
]
}
Using Elasticsearch index alias API, you can add, update and remove index aliases as you see fit.
How to Get Index Alias Info
When you create sophisticated aliases such as those filtered to a specific user, you might want to get information about the index. You can view the information using the GET method as:
Here is the cURL command:
This command will display the information regarding the alias. Since we have not added any information, it will typically resemble.
"my_index": {
"aliases": {
"my_alias_1": {}
}
}
}
Ensure that the alias exist to avoid getting a 404 error as shown below:
The result will be an “alias does not exist or missing” as:
"error": "alias [does_not_exist] missing",
"status": 404
}
How to Delete An Index Alias
To remove an existing alias from an index, we use the method we’ve used to add an alias but with a DELETE request instead. For example:
The equivalent cURL command is:
Elasticsearch should respond with 200 OK and acknowledged: true
“acknowledged”: true
}
There are other ways to update and remove aliases from an index in Elasticsearch. However, for simplicity, we have stuck with a single request.
Conclusion
In this simple tutorial, we have looked at creating an Elasticsearch index and then an alias. We have also covered how to delete an alias.
It’s worth noting that this guide is not the most definitive in the world; its purpose was to serve as a starter guide for creating Elasticsearch, not a comprehensive guide.
If you wish to learn more about the Elastic Index API, consider the resources below.
We also recommend having a basic knowledge of working with Elasticsearch and API; it will be of great help when working with the ELK stack.
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-aliases.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-add-alias.html
]]>This tutorial will show you how to create a Docker image that integrates Elasticsearch, Kibana, and Logstash. You can then use the image to deploy the ELK stack on any Docker container.
Getting Started
For this guide, we will start by installing and setting up Docker on a system. Once we set up Docker, we will deploy a container running Elasticsearch, Kibana, and Logstash in the same system. In that Container, we can then tweak and customize Elastic Stack to our needs.
Once we have the appropriate ELK stack, we will export the Docker container to an image you can use to build other containers.
Step 1: Install Docker
The very first thing we need to do is install Docker on a system. For this tutorial, we are using Debian 10 as the base system.
The very first step is to update the apt packages using the following command:
Next, we need to install some packages that will allow us to use apt over HTTPS, which we can do using the following command:
The next step is to add the Docker repository GPG key using the command:
From there, we need to add the Docker repository to apt using the command:
Now we can update the package index and install Docker:
sudo apt-get install docker-ce docker-ce-cli containerd.io
Step 2: Pulling ELK Docker Image
Now that we have Docker up and running on the system, we need to pull a Docker container containing the ELK stack.
For this illustration, we will use the elk-docker image available in the Docker registry.
Use the command below to pull the Docker image.
Once the image has been pulled successfully from the docker registry, we can create a docker container using the command:
Once you create the Container, all the services (Elasticsearch, Kibana, and Logstash) will be started automatically and exposed to the above ports.
You can access the services with the addresses
- http://localhost:9200 – Elasticsearch
- http://localhost:5601 – Kibana web
- http://localhost:5044 – Logstash
Step 3: Modifying the Container
Once we have ELK up and running on the Container, we can add data, modify the settings, and customize it to meet our needs.
For the sake of simplicity, we will add sample data from Kibana Web to test it.
On the main Kibana home page, select Try sample data to import sample.
Choose the data to import and click on add data
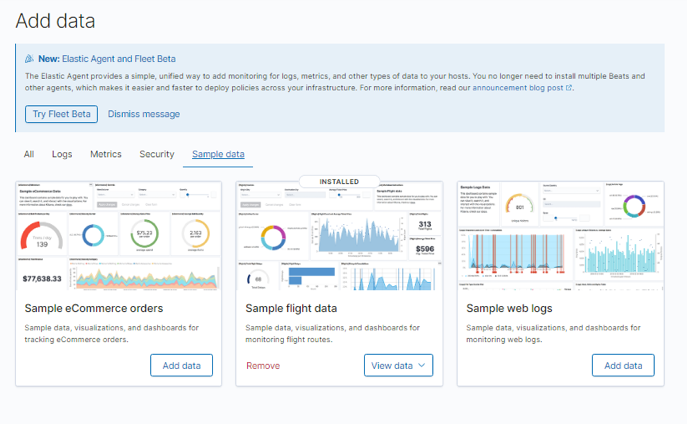
Now that we have imported and modified the Container, we can export it to create a custom Elk image that we can use for any Docker image.
Step 4: Create ELK Docker image from Container
With all the changes in the Elastic stack container, we can export the Container to an image using a single command as:
Using the above command, we created the image elkstack with the tag version2 to the docker repository myrepo. This saves all the changes we made from the Container, and you can use it to create other containers.
Conclusion
This quick and simple guide showed you how to create a custom ELK image for Docker with changes. For those experienced with Docker, you can use Dockerfiles to accomplish the same tasks but with more complexity.
]]>Monitoring and analyzing logs for various infrastructures in real-time can be a very tedious job. When dealing with services like web servers that constantly log data, the process can very be complex and nearly impossible.
As such, knowing how to use tools to monitor, visualize, and analyze logs in real-time can help you trace and troubleshoot problems and monitor suspicious system activities.
This tutorial will discuss how you can use one of the best real-time log collections and analyzing tools- ELK. Using ELK, commonly known as Elasticsearch, Logstash, and Kibana, you can collect, log, and analyze data from an apache web server in real-time.
What is ELK Stack?
ELK is an acronym used to refer to three main open-source tools: Elasticsearch, Logstash, and Kibana.
Elasticsearch is an open-source tool developed to find matches within a large collection of datasets using a selection of query languages and types. It is a lightweight and fast tool capable of handling terabytes of data with ease.
Logstash engine is a link between the server-side and Elasticsearch, allowing you to collect data from a selection of sources to Elasticsearch. It offers powerful APIs that are integrable with applications developed in various programming languages with ease.
Kibana is the final piece of the ELK stack. It is a data visualization tool that allows you to analyze the data visually and generate insightful reports. It also offers graphs and animations that can help you interact with your data.
ELK stack is very powerful and can do incredible data-analytics things.
Although the various concepts we’ll discuss in this tutorial will give you a good understanding of the ELK stack, consider the documentation for more information.
Elasticsearch: https://linkfy.to/Elasticsearch-Reference
Logstash: https://linkfy.to/LogstashReference
Kibana: https://linkfy.to/KibanaGuide
How to Install Apache?
Before we begin installing Apache and all dependencies, it’s good to note a few things.
We tested this tutorial on Debian 10.6, but it will also work with other Linux distributions.
Depending on your system configuration, you need sudo or root permissions.
ELK stack compatibility and usability may vary depending on versions.
The first step is to ensure you have your system fully updated:
sudo apt-get upgrade
The next command is to install the apache2 webserver. If you want a minimal apache installed, remove the documentation and utilities from the command below.
sudo service apache2 start
By now, you should have an Apache server running on your system.

How to Install Elasticsearch, Logstash, and Kibana?
We now need to install the ELK stack. We will be installing each tool individually.
Elasticsearch
Let us start by installing Elasticsearch. We are going to use apt to install it, but you can get a stable release from the official download page here:
https://www.elastic.co/downloads/elasticsearch
Elasticsearch requires Java to run. Luckily, the latest version comes bundled with an OpenJDK package, removing the hassle of installing it manually. If you need to do a manual installation, refer to the following resource:
https://www.elastic.co/guide/en/elasticsearch/reference/current/setup.html#jvm-version
In the next step, we need to download and install the official Elastic APT signing key using the command:
![]()
Before proceeding, you may require an apt-transport-https package (required for packages served over https) before proceeding with the installation.
Now, add the apt repo information to the sources.list.d file.
echo “deb https://artifacts.elastic.co/packages/7.x/apt stable main” | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Then update the packages list on your system.
Install Elasticsearch using the command below:
Having installed Elasticsearch, start and enable a start on boot with the systemctl commands:
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch
The service may take a while to start. Wait a few minutes and confirm that the service is up and running with the command:
Using cURL, test if the Elasticsearch API is available, as shown in the JSON output below:
{
"name" : "debian",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "VZHcuTUqSsKO1ryHqMDWsg",
"version" : {
"number" : "7.10.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "1c34507e66d7db1211f66f3513706fdf548736aa",
"build_date" : "2020-12-05T01:00:33.671820Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
“tagline”: “You Know, for Search”
}
How to install Logstash?
Install the logstash package using the command:
How to install Kibana?
Enter the command below to install kibana:
How to Configure Elasticsearch, Logstash, and Kibana?
Here’s how to configure the ELK stack:
How to Configure Elasticsearch?
In Elasticsearch, data gets ordered into indices. Each of these indexes has one or more shard. A shard is a self-contained search engine used to handle and manage indexes and queries for a subset in a cluster within Elasticsearch. A shard works as an instance of a Lucene index.
Default Elasticsearch installation creates five shards and one replica for every index. This is a good mechanism when in production. However, in this tutorial, we will work with one shard and no replicas.
Start by creating an index template in JSON format. In the file, we will set the number of shards to one and zero replicas for matching index names (development purposes).
In Elasticsearch, an index template refers to how you instruct Elasticsearch in setting up the index during the creation process.
Inside the json template file (index_template.json), enter the following instructions:
"template":"*",
"settings":{
"index":{
"number_of_shards":1,
"number_of_replicas":0
}
}
}
Using cURL, apply the json configuration to the template, which will be applied to all indices created.
{"acknowledged":true}
Once applied, Elasticsearch will respond with an acknowledged: true statement.
How to Configure Logstash?
For Logstash to gather logs from Apache, we must configure it to watch any changes in the logs by collecting, processing, then saving the logs to Elasticsearch. For that to happen, you need to set up the collect log path in Logstash.
Start by creating Logstash configuration in the file /etc/logstash/conf.d/apache.conf
file {
path => '/var/www/*/logs/access.log'
type => "apache"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch { }
}
Now ensure to enable and start logstash service.
sudo systemctl start logstash.service
How to enable and configure Kibana?
To enable Kibana, edit the main .yml config file located in /etc/kibana/kibana.yml. Locate the following entries and uncomment them. Once done, use systemctl to start the Kibana service.
server.host: "localhost"
sudo systemctl enable kibana.service && sudo systemctl start kibana.service
Kibana creates index patterns based on the data processed. Hence, you need to collect logs using Logstash and store them in Elasticsearch, which Kibana can use. Use curl to generate logs from Apache.
Once you have logs from Apache, launch Kibana in your browser using the address http://localhost:5601, which will launch the Kibana index page.
In the main, you need to configure the index pattern used by Kibana to search for logs and generate reports. By default, Kibana uses the logstash* index pattern, which matches all the default indices generated by Logstash.
If you do not have any configuration, click create to start viewing the logs.
How to View Kibana Logs?
As you continue to perform Apache requests, Logstash will collect the logs and add them to Elasticsearch. You can view these logs in Kibana by clicking on the Discover option on the left menu.
The discover tab allows you to view the logs as the server generates them. To view the details of a log, simply click the dropdown menu.
Read and understand the data from the Apache logs.
How to Search for Logs?
In the Kibana interface, you will find a search bar that allows you to search for data using query strings.
Example: status:active
Learn more about ELK query strings here:
Since we are dealing with Apache logs, one possible match is a status code. Hence, search:
This code will search for logs with the status code of 200 (OK) and display it to Kibana.
How to Visualize Logs?
You can create visual dashboards in Kibana by selecting the Visualize tab. Select the type of dashboard to create and select your search index. You can use the default for testing purposes.
Conclusion
In this guide, we discussed an overview of how to use the ELK stack to manage logs. However, there is more to these technologies that this article can cover. We recommend exploring on your own.
]]>Elasticsearch Best Practices
We will start working with Best Practices to follow with Elasticsearch and what problems it can create when we avoid these points. Let’s get started.
Always define ES Mappings
One thing ES can surely do is, working without mappings. So, when you start feeding JSON data to your ES index, it will iterate over the fields of data and create a suitable mapping. This seems direct and easy as ES is selecting the data-type itself. Based on your data, you might need a field to be of specific data-type.
For example, suppose you index the following document:
"id" : 1,
"title" : "Install ElasticSearch on Ubuntu",
"link" : "https://linuxhint.com/install-elasticsearch-ubuntu/",
"date" : "2018-03-25"
}
This way, Elasticsearch will mark the “date” field as “date” type. But when you index the following document:
"id" : 1,
"title" : "ES Best Practices and Performance",
"date" : "Pending"
}
This time, the type of the date field has been changed and ES will throw an error and won’t allow your document to be indexed. To make things easy, you can index a few documents, see what fields are indexed by ES and grab the mapping from this URL:
This way, you won’t have to construct the complete mapping as well.
Production Flags
The default cluster name that ES starts is called elasticsearch. When you have a lot of nodes in your cluster, it is a good idea to keep the naming flags as consistent as possible, like:
node.name: app_es_node_001
Apart from this, recovery settings for nodes matter a lot as well. Suppose some of the nodes in a cluster restart due to a failure and some nodes restart a little after other nodes. To keep the data consistent between all these nodes, we will have to run consistency program that will keep all clusters in a consistent state.
It is also helpful when you tell the cluster in advance how many nodes will be present in the cluster and how much recovery time will these need:
gateway.recover_after_time: 7m
With the correct config, a recovery which would have taken hours can take as little as a minute and can save a lot of money to any company.
Capacity Provisioning
It is important to know how much space your data will take and the rate at which it flows into Elasticsearch, because that will decide the amount of RAM you will need on each of the node of the cluster and the master node as well.
Of course, there are no specific guidelines to achieve the numbers needed but we can take some steps which provide us with a good idea. One of the steps will be to simulate the use-case. Make an ES cluster and feed it with almost the same rate of data as you would expect with your production setup. The concept of start big and scale down can also help you be consistent about how much space is needed.
Large Templates
When you define indexed large templates, you will always face issues related to syncing the template across your various nodes of the cluster. Always note that the template will have to be re-defined whenever a data model change occurs. It is a much better idea to keep the templates as dynamic. Dynamic Templates automatically update field mappings based on the mappings we defined earlier and the new fields. Note that there is no substitute to keeping the templates as small as possible.
2Using mlockall on Ubuntu Servers
Linux makes use of Swapping process when it needs memory for new pages. Swapping make things slow as disks are slower than the memory. The mlockall property in ES configuration tells ES to not swap its pages out of the memory even if they aren’t required for now. This property can be set in the YAML file:
In the ES v5.x+ versions, this property has changed to:
If you’re using this property, just make sure that you provide ES with big enough heap-memory using the -DXmx option or ES_HEAP_SIZE.
Minimize Mapping Updates
The performance of a cluster is slightly affected whenever you make mapping update requests on your ES cluster. If you can’t control this and still want to make updates to mappings, you can use a property in ES YAML config file:
When the model update request is in pending queue for the master node and it sends data with the old mapping to the nodes, it also has to send an update request later to all the nodes. This can make things slow. When we set the above property to false, this makes master sense that an update has been made to the mapping and it won’t send the update request to the nodes. Note that this is only helpful if you make a lot of changes to your mappings regularly.
Optimized Thread-pool
ES nodes have many thread pools in order to improve how threads are managed within a node. But there are limitations on how much data each thread can take care of. To keep track of this value, we can use an ES property:
This informs ES the number of requests in a shard which can be queued for execution in the node when there is no thread available to process the request. If the number of tasks goes higher than this value, you will get a RemoteTransportException. The higher this value, the higher the amount of heap-space will be needed on your node machine and the JVM heap will be consumed as well. Also, you should keep your code ready in case this exception is thrown.
Conclusion
In this lesson, we looked at how we can improve Elasticsearch performance by avoiding common and not-so-common mistakes people make. Read more Elasticsearch articles on LinuxHint. ]]>
What are Mapping Types?
In Elasticsearch, each document belongs to an Index and a Type. An Index can be considered as a Database whereas a Type can be seen as a Table when compared to a Relational Database. A mapping Type was a logical partition of an object with other objects which belonged to other Mapping Types in the same Index.
Each Mapping Type has its own fields. For example, a type of user can have following fields:
"id" : 123,
"name" : "Shubham",
"website" : 1
}
Another Mapping Type in the same index website can have following fields which are completely different from the user type:
"id" : 1,
"title" : "LinuxHint",
"link" : "https://linuxhint.com/"
}
While searching for a document in an index, the search could have been limited to a single document by specifying a single field as:
{
"query": {
"match": {
"id": 1
}
}
}
The _type field of the documents was combined with its _id to generate a _uid field so documents with same _id could exist in a single index.
Read Elasticsearch Tutorial for Beginners for a deeper understanding of Elasticsearch Architecture and get started with it with Install ElasticSearch on Ubuntu.
Why are Mapping Types being removed?
Just like what we said above while explaining how Index and Types were similar to a Database and a Table in a Relational Database, Elasticsearch team thought the same but this wasn’t the case as Lucene Engine doesn’t follow the same analogy. This is because of the following reasons:
- In a Relational Database, tables are independent of each other and name of the columns, even if they are same have no relationship between them. This is not the case with fields in mapping types as in ES, fields with the same name are treated as same Lucene Engine field internally.
- In the example above, the field _id in user type and website type is stored in the same field and should have exactly the same type which can lead to frustration and confusion.
- Storing entities with no fields in common stops Lucene to compress documents effectively.
Alternatives to Mapping Types
Although the decision has been made, we still need to separate different types of data. Now, the first alternative is to separate documents in their own index which has two advantages:
- Now that data is common in every index, Lucene can very easily apply its own data compression techniques.
- Now that all documents in an index have same fields, full-text search abilities increase phenomenally as scoring of each document has increased.
Another alternative to separating the data is maintaining a custom _type field in each document we insert, like:
{
"type": "user",
"id": 123,
"name": "Shubham",
"website": 1
}
PUT db_name/doc/website
{
"type": "website",
"id": 1,
"title": "LinuxHint",
"link": "https://linuxhint.com/"
}
This is an excellent usage if you’re looking for a complete custom solution.
Schedual for removal of Mapping Types
As removing Mapping Types is a big change, ES team is doing the process slowly. Here is a schedule for the roll out extracted from elastic.co:
- Elasticsearch 7.x
- The type parameter in URLs are optional. For instance, indexing a document no longer requires a document type.
- The _default_ mapping type is removed.
- Elasticsearch 8.x
- The type parameter is no longer supported in URLs.
- The include_type_name parameter defaults to false.
- Elasticsearch 9.x
- The include_type_name parameter is removed.
Conclusion
In this lesson, we looked at why were Elasticsearch Mapping types removed and will be completely unsupported in coming versions.
]]>- Logstash: It is an Open Source tool which is used to collect, parse and store logs for an application or a system which can be used later for metrics of APIs, errors faced in a system and many more use-cases which are beyond the scope of this lesson
- Kibana: This is a dashboard interface on the web which is an excellent dashboard used to search and view the logs that Logstash has indexed into the Elasticsearch index
- Filebeat: This is installed on the client-server who want to send their logs to Logstash. Filebeat acts as a log shipping agent and communicates with Logstash.
Let us also visualise how things will work:
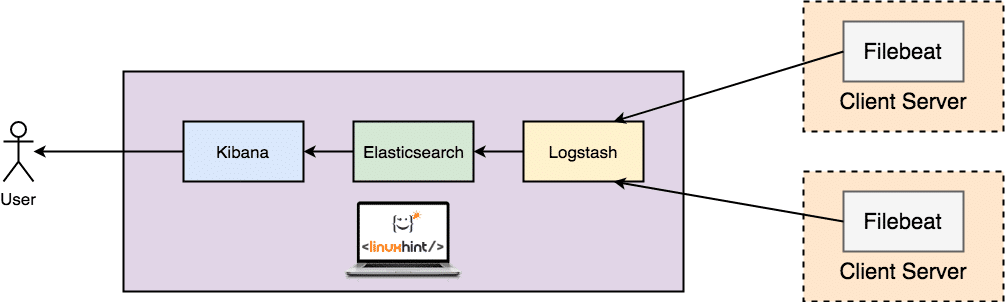
ELK Setup on Ubuntu
Prerequisites
For this lesson and all installations it needs, you should have root access to the machine. We will be using a machine with this configuration:
- Ubuntu 16.04
- RAM: 4 GB
- CPU: 2
Few application servers from where you want to gather data from would also be a good to have.
Install Java
To install Elasticsearch on Ubuntu, we must install Java first. Java might not be installed by default. We can verify it by using this command:
Checking Java version
Here is what we get back with this command:

Checking Java version
We will now install Java on our system. Use this command to do so:
Installing Java
sudo apt-get update
sudo apt-get install oracle-java8-installer
Once these commands are done running, we can again verify that Java is now installed by using the same version command.
Install Elasticsearch
Next step for the ELK Stack setup is installing Elasticsearch on Ubuntu Machine which will store the logs generated by systems and applications. Before we can install Elasticsearch, we need to import its public GPG keys to the rpm package manager:
GPG Keys
Now, insert the mentioned lines to the configuration file for the repository ‘elasticsearch.repo’:
Repository Config
name=Elasticsearch repository
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
Now, read the lesson Install ElasticSearch on Ubuntu for installation process. Once ES is up and running, make sure it responds normally to this curl command:
ES Status
The normal output will be:

Install Logstash
Installing Logstash is very easy using the apt package manager and is available with the same repository and public key as Elasticsearch, so we don’t have to do that again. Let’s create the source list to start:
Create Source list
Update the apt package list:
Updating Packages
Install Logstash with a single command:
Install Logstash
Logstash is installed but it is not configured yet. We will configure Logstash in coming sections.
Install Kibana
Kibana is very easy to install. We can start by creating the Kibana source list:
Create Kibana source list
Now, we will update the apt package list:
Updating Packages
We are ready to install Kibana now:
Install Kibana
Once Kibana is installed, we can run it:
Start Kibana Service
sudo service kibana start
Before we show you the Kibana Dashboard, we need to setup the Filebeat Log shipping agent as well.
Setup Filebeat
We are ready to install Filebeat now:
Install Filebeat
Before we can start the Filebeat service, we need to configure it for the input type and document type. Because we’re using system logs only as of now, let’s mention this in the configuration file in ‘/etc/filebeat/filebeat.yml’:
Configure Filebeat
input_type: log
document_type: syslog
...
We can also start filebeat now:
Start Filebeat Service
sudo service filebeat start
Once filebeat is up and running, we can check that it is OK by issuing the following curl command:
Testing Filebeat
We should receive a similar result as we got in the ES installation.
Connecting to Kibana
We are now ready to connect to Kibana. As we already started the Kibana service, its dashboard should be visible at:
Kibana Dashoboard URL
Once you’re up on Kibana, create an index on Kibana with name ‘filebeat-*’. Now based on the logs available, you can see the metrics and logs in your Kibana Dashboard:
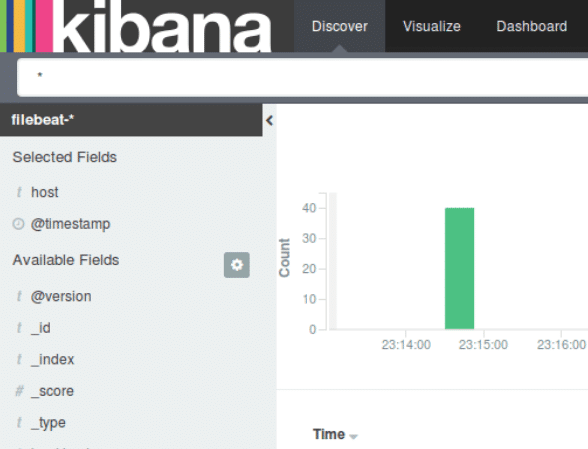
Conclusion
In this lesson, we looked at how we can install and start using the ELK Stack for log visualisation and support an excellent Dashboard for business teams.
]]>Elasticsearch Database
Elasticsearch is one of the most popular NoSQL databases which is used to store and search for text-based data. It is based on the Lucene indexing technology and allows for search retrieval in milliseconds based on data that is indexed.
Based on Elasticsearch website, here is the definition:
Elasticsearch is an open source distributed, RESTful search and analytics engine capable of solving a growing number of use cases.
Those were some high-level words about Elasticsearch. Let us understand the concepts in detail here.
- Distributed: Elasticsearch divides the data it contains into multiple nodes and uses master-slave algorithm internally
- RESTful: Elasticsearch supports database queries through REST APIs. This means that we can use simple HTTP calls and use HTTP methods like GET, POST, PUT, DELETE etc. to access data.
- Search and Analytics engine: ES supports highly analytical queries to run in the system which can consist of aggreagted queries and multiple types, like structured, unstructured and geo queries.
- Horizontally-scalable: This kind of scailing refers to adding more machines to an existing cluster. This means that ES is capable of accepting more nodes in its cluster and providing no down-time for required upgrades to the system. Look at the image below to understand the scaling concepts:
Vertical and Horizontal Scailing
Getting Started with Elasticsearch Database
To start using Elasticsearch, it must be installed on the machine. To do this, read Install ElasticSearch on Ubuntu.
Make sure you have an active ElasticSearch installation if you want to try examples we present later in the lesson.
Elasticsearch: Concepts & Components
In this section, we will see what components and concepts lies in the heart of Elasticsearch. Understanding about these concepts is important to understand how ES works:
- Cluster: A cluster is a collection of server machines (Nodes) which holds the data. The data is divided between multiple nodes so that it can be replicated and Single Point of Failure (SPoF) doesn’t happen with the ES Server. Default name of the cluster is elasticsearch. Each node in a cluster connects to the cluster with a URL and the cluster name so it is important to keep this name distinct and clear.
- Node: A Node machine is part of a server and is termed as a single machine. It stores the data and provides indexing and search capabilities, along with other Nodes to the cluster.
Due to the concept of Horizontal scaling, we can virtually add an infinite number of nodes in an ES cluster to give it a lot more strength and indexing capabilities.
- Index: An Index is a collection of document with somewhat similar characteristics. An Index is pretty much similar to a Database in a SQL-based environment.
- Type: A Type is used to separate data between the same index. For example, Customer Database/Index can have multiple types, like user, payment_type etc.
Note that Types are deprecated from ES v6.0.0 onwards. Read here why this was done.
- Document: A Document is the lowest level of unit which represents data. Imagine it like a JSON Object which contains your data. It is possible to index as many documents inside an Index.
Types of search in Elasticsearch
Elasticsearch is known for its near real-time searching capabilities and the flexibilities it provides with the type of data being indexed and searched. Let’s start studying how to use search with various types of data.
- Structured Search: This type of search is run on data which has a pre-defined format like Dates, times, and numbers. With pre-defined format comes the flexibility of running common operations like comparing values in a range of dates. Interestingly, textual data can be structured too. This can happen when a field has fixed number of values. For example, Name of Databases can be, MySQL, MongoDB, Elasticsearch, Neo4J etc. With structured search, the answer to the queries we run is either a yes or no.
- Full-Text Search: This type of search is dependent on two important factors, Relevance and Analysis. With Relevance, we determine how well some data matches to the query by defining a score to the resultant documents. This score is provided by ES itself. Analysis refers to breaking the text into normalized tokens to create an inverted index.
- Multifield Search: With the number of analytic queries ever increasing on the stored data in ES, we do not usually just face simple match queries. Requirements have grown to run queries which span across multiple fields and have a scored sorted list of data returned to us by the database itself. This way, data can be present to the end user in a much more efficient way.
- Proimity Matching: Queries today is much more than just identifying if some textual data contains another string or not. It is about establishing the relationship between data so that it can be scored and matched to the context in which data is being matched. For example:
- Ball hit John
- John hit the Ball
- John bought a new Ball which was hit Jaen garden
A match query will find all three documents when searched for Ball hit. A proximity search can tell us how far these two words appear in the same line or paragraph due to which they matched.
- Partial Matching: It is often we need to run partial-matchin queries. Partial Matching allows us to run queries which matches partially. To visualise this, let’s look at a similar SQL based queries:
SQL Queries: Partial Matching
WHERE name LIKE "%john%"
AND name LIKE "%red%"
AND name LIKE "%garden%"On some occasions, we only need to run partial match queries even when they can be considered like brute-force techniques.
Integration with Kibana
When it comes to an analytics engine, we usually need to run analysis queries in a Business-Intelligence (BI) domain. When it comes to Business Analysts or Data Analysts, it wouldn’t be fair to assume that people know a programming language when they want to visualise data present in ES Cluster. This problem is solved by Kibana. Kibana offers so many benefits to BI that people can actually visualise data with an excellent, customisable dashboard and see data inetractively. Let’s look at some of its benefits here.
Interactive Charts
At the core of Kibana is Interactive Charts like these:
Kibana comes supported with various type of charts like pie charts, sunbursts, histograms and much more which uses the complete aggregation capabilities of ES.
Mapping Support
Kibana also supports complete Geo-Aggregation which allows us to geo-map our data. Isn’t this cool?!
Pre-built Aggregations and Filters
With Pre-built Aggregations and Filters, it is possible to literally frag, drop and run highly optimized queries within the Kibana Dashboard. With just a few clicks, it is possible to run aggregated queries and present results in the form of Interactive Charts.
Easy Distribution of Dashboards
With Kibana, it is also very easy to share dashboards to a much wider audience without doing any changes to the dashboard with the help of Dashboard Only mode. We can easily insert dashboards into our internal wiki or webpages.
Feature images taken form Kibana Product page.
Using Elasticsearch
To see the instance details and the cluster information, run the following command:
Now, we can try inserting some data into ES using the following command:
Inserting Data
-X POST 'http://localhost:9200/linuxhint/hello/1' \
-H 'Content-Type: application /json' \
-d '{ "name" : "LinuxHint" }'\
Here is what we get back with this command:

Let’s try getting the data now:
Getting Data
When we run this command, we get the following output:

Conclusion
In this lesson, we looked at how we can start using ElasticSearch which is an excellent Analytics Engine and provides excellent support for near real-time free-text search as well.
]]>Elasticsearch Database
Elasticsearch is one of the most popular NoSQL databases which is used to store and search for text based based data.
Elasticsearch is based on the lucene indexing technology and allows for search retrieval in milliseconds based on data that is indexed. It supports database queries through REST APIs. This means that we can use simple HTTP calls and use HTTP methods like GET, POST, PUT, DELETE etc. to access data.
Installing Java
To install Elasticsearch on Ubuntu, we must install Java first. Java might not be installed by default. We can verify it by using this command:
When we run this command, we get the following output:
We will now install Java on our system. Use this command to do so:
sudo apt-get update
sudo apt-get install oracle-java8-installer
Once these commands are done running, we can again verify that Java is now installed by using the same command.
Installing Elasticsearch
Now, installing Elasticsearch is just a matter of few commands. To start, download the Elasticsearch package file from ES page:
When we run the above command, we will see the following output:

Next we can install the downloaded file the dpkg command:
When we run the above command, we will see the following output:
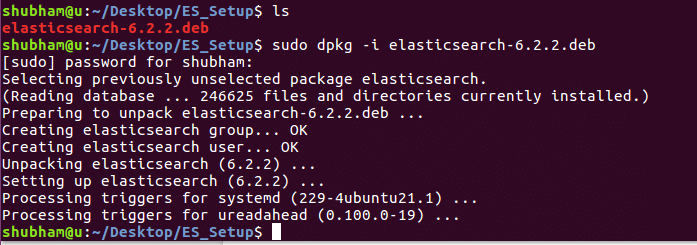
Make sure that you download the deb package only from the ES website.
The config files for Elasticsearch will be stored at /etc/elasticsearch. To make sure that Elasticsearch is started and stopped with the machine, run the following command:
Configuring Elasticsearch
We have an active installation for Elasticsearch now. To use Elasticsearch effectively, we can some important changes to the configuration. Run the following command to open the ES config file:
We first modify the node.name and cluster.name in elasticsearch.yml file. Remember to remove the # before each line you want to edit to unmark it as a comment.
Modify these properties:
Once you’re done with all the config changes, start the ES server first time:
When we run this command and check the service status, we get the following output:
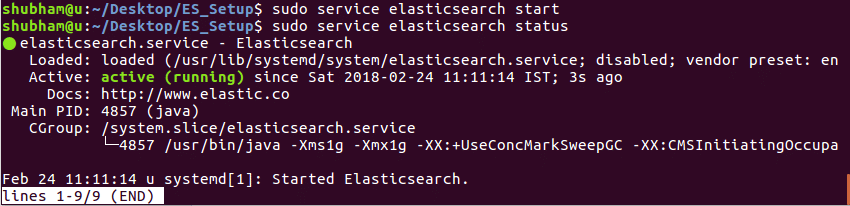
Using Elasticsearch
Now that Elasticsearch has started, we can start using it for our commands.
To see the instance details and the cluster information, run the following command:
You may have to install curl, do it so using this command:
When we run this command, we get the following output:
Now, we can try inserting some data into ES using the following command:
/json' -d '{ "name" : "LinuxHint" }'
When we run this command, we get the following output:
Let’s try getting the data now:
When we run this command, we get the following output:
Conclusion
In this quick post, we learned how we can install Elasticsearch and run basic queries on it.
]]>See release notes for Elasticsearch v5.2.0 and Kibana v5.2.0 for full details of release.

How to Install Elasticsearch 5.2.0 on CentOS 7, RHEL
- Elasticsearch requires Java 8 or later, so lets install latest Java
How to install Java 8 latest update on CentOS
- Download and install the Elasticsearch Public Signing Key
sudo rpm --import http://packages.elasticsearch.org/GPG-KEY-elasticsearch
- Next create a file called “elasticsearch.repo” in “/etc/yum.repos.d/” directory
sudo vi /etc/yum.repos.d/elasticsearch.repo
- Then add the following config into the repository created above
[elasticsearch-5.x] name=Elasticsearch repository for 5.x packages baseurl=https://artifacts.elastic.co/packages/5.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
- Now install Elasticsearch
sudo yum install elasticsearch
- Next edit the configuration > locate “network.host:” and update to “network.host: localhost”
sudo vi /etc/elasticsearch/elasticsearch.yml
- Start service and set it to auto run on boot up
/etc/init.d/elasticsearch status sudo chkconfig --levels 235 elasticsearch on
Install Kibana 5.2.0 on CentOS 7, RHEL
- Kibana also requires Java 8 or later, so I am assuming you had already done that when you installed Elasticsearch above
How to install Java 8 latest update on CentOS
- Download and install the Public Signing Key (Already done from above)
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
- Next create a file called “kibana.repo” in “/etc/yum.repos.d/” directory
sudo vi /etc/yum.repos.d/kibana.repo
- Then add the following config into the repository created above
[kibana-5.x] name=Kibana repository for 5.x packages baseurl=https://artifacts.elastic.co/packages/5.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
- Now install kibana
sudo yum install kibana
- Confirm you can Stop and Start Kibana
sudo -i service kibana stop sudo -i service kibana start
- Check if you are running Systemd or SysV init
ps -p 1
- Configure Kibana to start automatically when system reboots.
—– For SysV init —–
sudo chkconfig --add kibana sudo -i service kibana stop sudo -i service kibana start
—– For systemd —–
sudo /bin/systemctl daemon-reload sudo /bin/systemctl enable kibana.service sudo systemctl stop kibana.service sudo systemctl start kibana.service
- Now all you need to do is access your kibana page with following URL:
http://localhost:5601
]]>You can install nginx and configure it to act as a proxy server. This would enable you access kibana via port 80