As developers, we are no strangers to managing and saving various copies of code before joining it to the main code.
Let’s discuss a better and efficient way to manage various code versions and merge them with the main code after testing.
Let’s dive in:
Introduction To Version Control Systems
We have mentioned that Git is a version control system. What exactly is a version control system, and how does it work?
A version control system is a system that allows developers to track file changes. Version control systems work by creating collections of various versions of files and the changes made to each version. They allow you to switch between various versions of the files seamlessly.
A version control system stores a collection of file changes in a location called a repository.
In most use cases, version control systems help track changes in source code files as they contain raw text. However, version control systems are not limited to text files; they can track even changes in binary data.
Types of Version Control Systems
There are various types of version control systems. They include:
- Localized Version control systems: This type of version control system works by storing various versions of the files locally by creating copies of the file changes.
- Centralized version control system: Centralized version control system includes a central server with various file versions. However, the developer still retains a copy of the file on their local computer
- Distributed Version control system: Distributed version control system does not require a server. However, it involves each developer cloning a copy of the main repository, and you have access to changes of all the files. Popular distributed VC systems are Git, Bazaar, and Mercurial.
Let us get started with Git.
Introduction to Git
Git is a distributed version control system developed by Linus Torvalds, the creator of the Linux Kernel. Initially developed to assist in developing the Linux Kernel, Git is powerful and easy to use. It supports linear development, which allows more than one developer to work on the same project concomitantly.
Let discuss how to install Git and use it to manage repositories:
How to Install Git on Linux
Depending on the system you are using, you will have Git installed by default. However, some systems may not have it installed. If that’s your case, use the following commands to install it on your system.
Debian/Ubuntu
Arch Linux
Install Git on Arch:
Fedora/RedHat/CentOS
Install on RHEL family:
sudo dnf install git
How to Configure Git
Once you install Git, you will get access to all its commands that you can use to work with local and remote repositories.
However, you need to configure it for first-time use. We will use the git config to set various variables.
The first config we set is the username and email address. Use the git config command shown to set the username, email address, and the default text editor.
git config --global core.editor vim
You can view the git configurations by using the git config –list command as:
user.name=myusername
user.email=username@email.com
core.editor=vim
How to Set up Repositories
We cannot mention Git and fail to mention the term repo or repository.
A repository, commonly called a repo, collects files and directories with their respective changes tracked by the version control system.
Changes in a repository are managed or tracked by commits, which are simple snapshots of changes applied to a file or directory.
Commits allow you to apply the changes or revert to a specific change within the repository.
Let’s now discuss how to set up a Git repository.
Suppose you have a project directory you would like to use as a git repo and track changes. You can initialize it using the command:
Once you run the git init command, Git initializes the directory as a repository and creates a .git directory used to store all the configuration files.
To start tracking changes using Git, you have to add it using the Git add command. For example, to add the file, reboot.c
To add all the files in that directory and start tracking changes, use the command:
After adding files, the next step is to stage a commit. As mentioned earlier, commits help track the changes to files in a repository.
Using the git commit command, you can add the message indicating the changes to the files.
For example, a message for the initial commit would be similar to:
NOTE: Adding descriptive and meaningful git messages helps other users using the repository identify file changes.
gitignore
Suppose you have some files and directories you do not wish to include in the main repository. For example, you may have configuration files for the development you are using.
To accomplish this, you need to use the .gitignore file. In the .gitignore file, you can add all files and directories that Git should not track.
An example of the .gitignore file typically looks like this:
node_modules/
tmp/
*.log
*.zip
.idea/
yarn.lock package-lock.json
.tmp*
Git Remote Repositories
Git is a powerful system that extends outside the scope of local repositories. Services such as GitHub, Bitbucket, and Gitlab offer remote repositories where developers can host and collaborate on projects using git repos.
Although some remote git services are premium—there’re many free services available—, they offer great tools and functionalities such as pull requests and many others that ensure smooth development.
NOTE: You can also build a self-hosted git service. Check our Gogs tutorial to learn how to accomplish this.
Let us now look at various ways to work with remote repositories.
Cloning a remote repository
A popular way to work with remote repositories is copying all the files in a remote repo to a local repo; a process called cloning.
To do this, use the git clone command followed by the URL of the repository as:
In services such as Github, you can download the zipped repository under the Download option.
To view the status of the files in the repository, use the git status command:
This command will tell you if the files in the repository have changed.
Update local repo from remote
If you have a cloned repository, you can get all the changes from the remote repository and merge them to the local one with Git fetch command:
Creating a new remote repository
To create a remote repository from the command line, use the git remote add command as:
Pushing local repo to remote
To push all changes from a local repository to a remote repository, you can use the git push command followed by the remote repository’s URL or name. First, ensure you have added the files, added a commit message as:
git commit -m “Added new function to shutdown. “ git push origin https://github.com/linuxhint/code.git
Deleting a remote repository
If you want to delete a remote repository from the command line, use the git remote rm command as:
Conclusion
We have covered the basics of setting up a Git version control system and how to use it to work with local and remote repositories.
This beginner-friendly guide is by no means a full-fledged reference material. Consider the documentation as there are a lot of features not covered in this tutorial.
]]>Git, developed by Linus Torvalds, is the most popular distributed system for version control. Git is a very efficient platform for open-source projects. Using Git, you can collaborate with the other developers, upload the new changes, keep track of the changes, and many more.
Installing Git on Linux Mint
The Git is included in Linux Mint 20 standard repositories can be installed easily using the apt command.
As always, update and upgrade your Linux Mint 20 system before installing the Git package.
Type the below-given command to update the apt package listing:
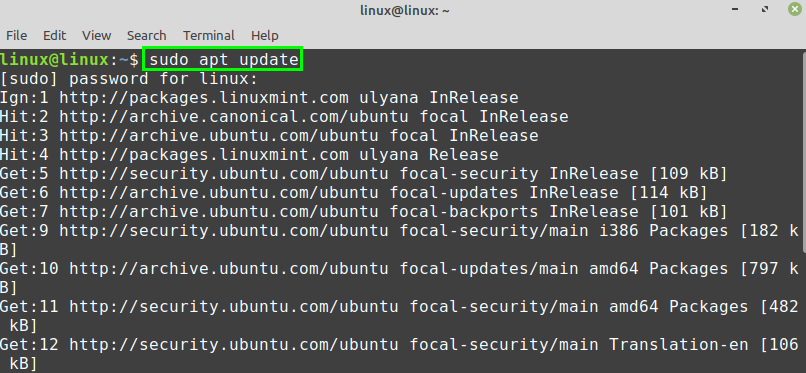
Next, upgrade the system with the command:
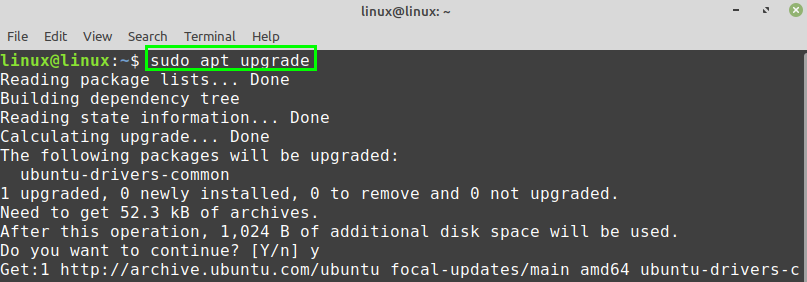
After successfully updating and upgrading the Linux Mint 20 system, install Git with the command:
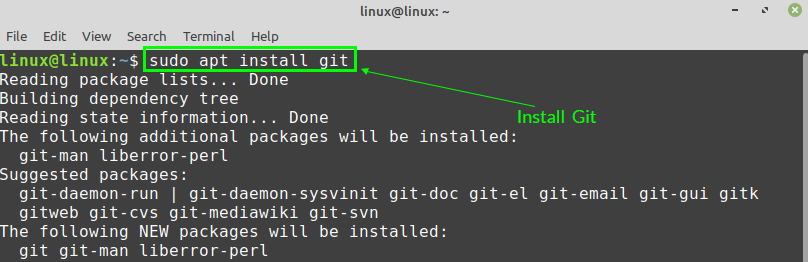
Press ‘y’ to continue installing Git.
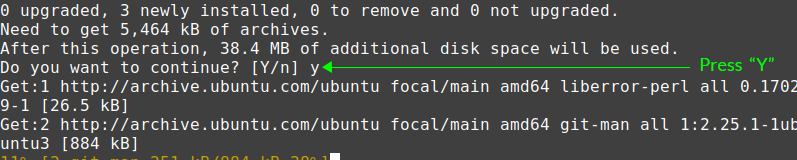
When the Git is successfully installed, verify the installation:
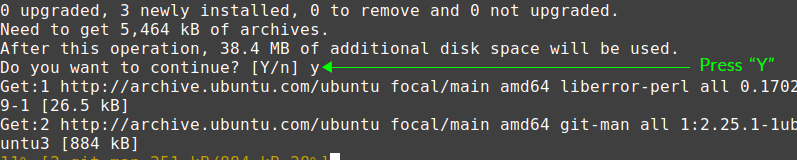
Git 2.25.1 is successfully installed on my Linux Mint 20.
Configuring the Git on Linux Mint 20
Next, we have to configure Git. The Git can be configured from the command line. Configuring Git refers to setting a name and email address. The name and email are used while committing changes on the Git repository.
Fire up the terminal and use the below-given command syntax to set a global commit name:

Type the below-given command to set the global commit email:

Finally, when the global commit name and email are set, run the below-given command to check and verify the changes:

The output shows that the global commit name and email are sent successfully.
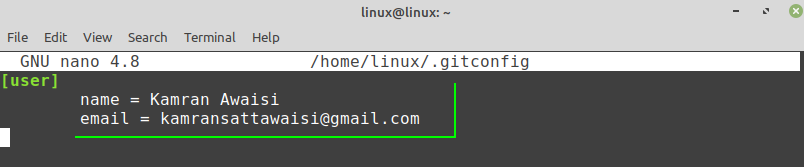
If the changes are not made correctly, or you want to change the global commit name and email any time, then you can edit the configuration settings any time by using the command:

The Git configuration file is opened in the nano editor. You can make any changes in the Git configuration file if you wish to.
Conclusion
Installing Git on Linux Mint 20 is very straightforward. Git is part of the Linux Mint 20 base repositories and can be downloaded and installed with apt command.
]]>GitScrum is a free, open-source task management tool that you can use to manage projects with ease. GitScrum uses the famous Git platform and Scrum software methodology to allow for more effective team management. This software helps users to track time consumed to perform various tasks and keep a record of projects that users are working on. Users can create multiple projects, keep a record of projects assigned to different users, and even chat in real-time. This article shows you how to install GitScrum in Debian 10.
Prerequisites
- Access to a Debian 10 server
- A valid domain name to point the server IP
- Root user privileges
Installing GitScrum in Debian 10
To install GitScrum in Debian 10, first, open the terminal window using the Ctrl+Alt+T shortcut. Then, update the system to the latest available version by issuing the following command:
![]()
After that, upgrade the apt package using the command given below:
![]()
Now that the system and apt package have been updated, we will begin the installation process.
Step 1: Install LAMP Server
First, you will need to install an Apache webserver, MariaDB server, and PHP, along with the extensions that are needed for the LAMP server. To install the LAMP server, enter the following command:

Step 2: Edit PHP File and Authenticate System
Once you have installed the server, open the php.ini file to make some edits:
![]()
In the file, change the following values:
upload_max_filesize = 100M
max_execution_time = 300
date.timezone = Asia/Kolkata
Save the modified file using the Ctrl+O shortcut.
Now, start the Apache and MariaDB service. Issue the following command in the terminal to start Apache:
![]()
If the system asks for authentication, simply enter the password and click the Authenticate button.
Now, start the MariaDB service using the following command:
![]()
Complete the authentication process.
Enable apache to start after system reboot using the command below:
![]()
Authenticate the system.
After that, an output will appear that is similar to this one:
Enable MariaDB to start after system reboot using the following command:
![]()
Then, authenticate the system.
Step 3: Configure MariaDB Database
The MariaDB root password is configured initially, so, you will be required to set a password. Log in to the MariaDB shell using the following command:
![]()
After you hit Enter, the output will appear as follows:
Set up the password using the following command:
![]()
Provide values for the root user and localhost, then enter the password you want to set.
After that, create the database and a user for GitScrum using the command provided below:

Next, create the GitScrum user using the following command:

The next step is to grant all the rights and privileges of the GitScrum database using the following:

Flush the privileges using the command given below:
![]()
And then, exit by issuing the following:

Step 4: Install Composer
Composer is the supporting manager for the PHP package that is a must-have for our project. Download the composer file using the following command:

To confirm the download and data integrity of the file, issue the command given below:

The phrase Installer Verified in the output shows that everything is running correctly.
To install the composer, run the following command:

After some time, you will see an output like this one:

Step 5: Install GitScrum
First, change the directory to your Apache root directory. Then, you can download GitScrum.
![]()
To download GitScrum, use the following command:

When you press Enter, the installation will begin. After some time, you will see an output like this:

Update and change the directory to the downloaded directory. Next, update GitScrum with the following command:
![]()
Once you are in the directory, enter:
![]()
To integrate GitScrum with Github, you will have to create an app in Github. Access this link, and you will see the following screen appear:
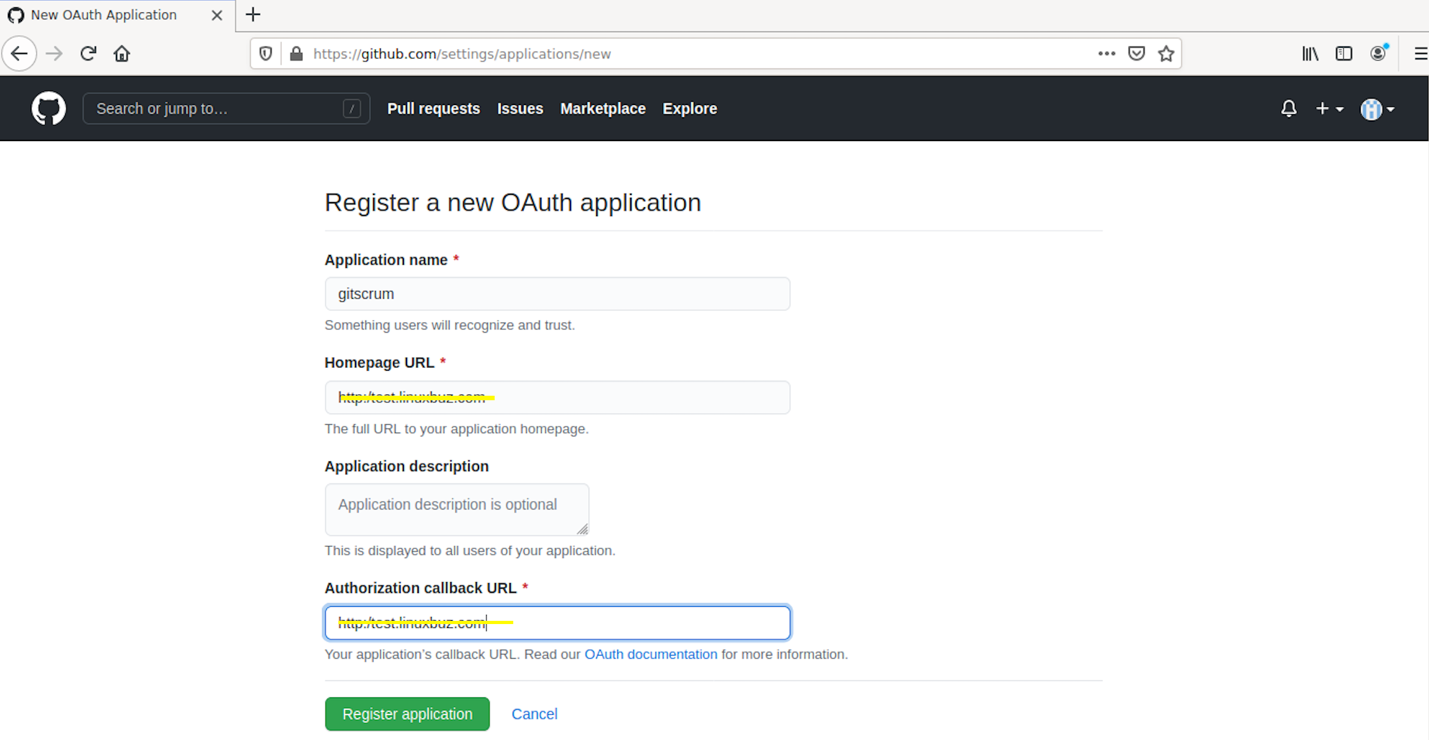
Log in to your account or sign up for a new one. Then, you will see the screen to Register a new OAuth application. Provide the Application name, Homepage URL (which must be running and responding to server requests), and Application callback URL.
Then, click Register Application. After that, you will see the following screen appear:
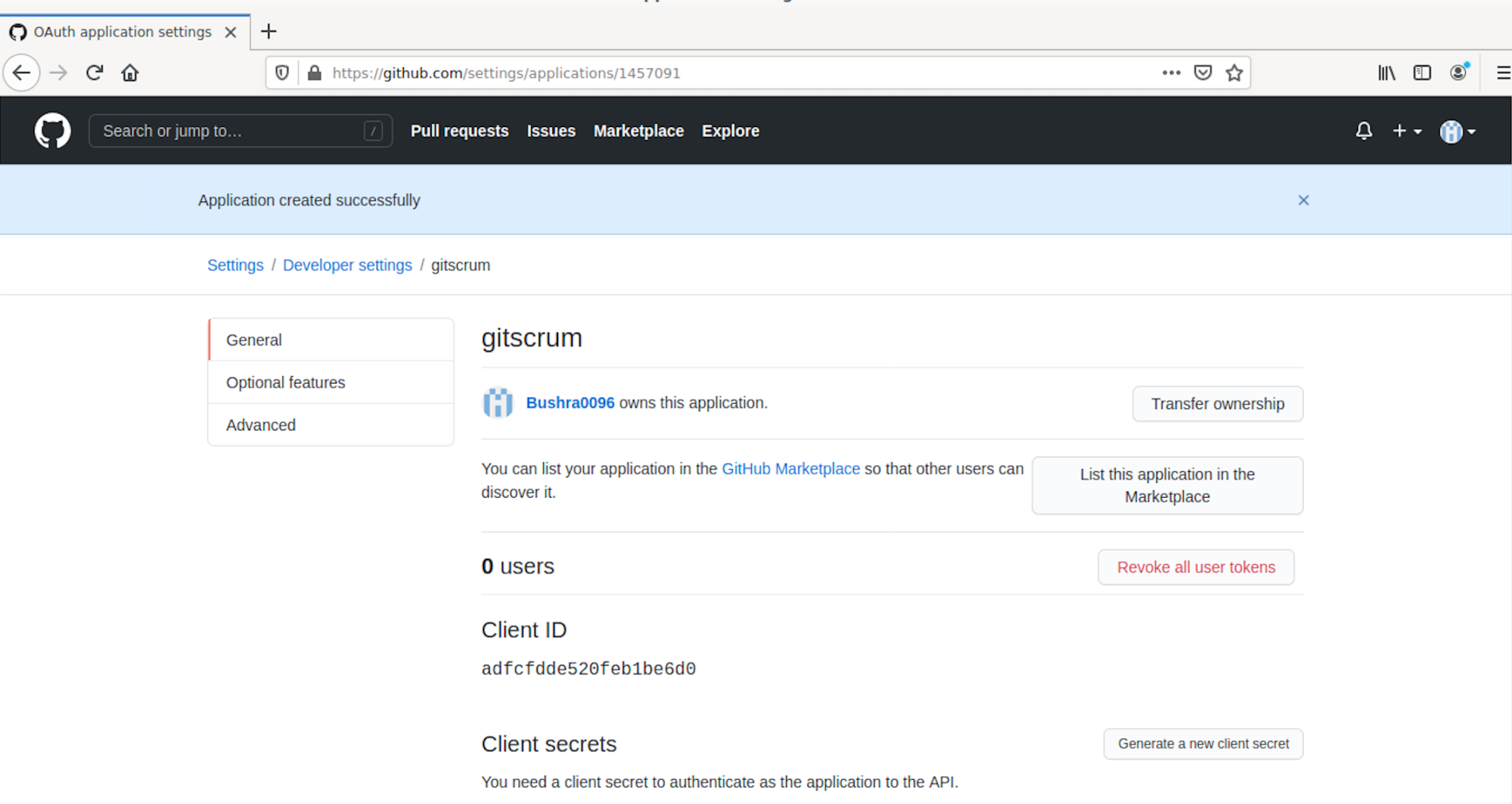
The next step is to use the Client ID and Client Secret from the application registration page and paste them into the .env file. Access the file using the following command:
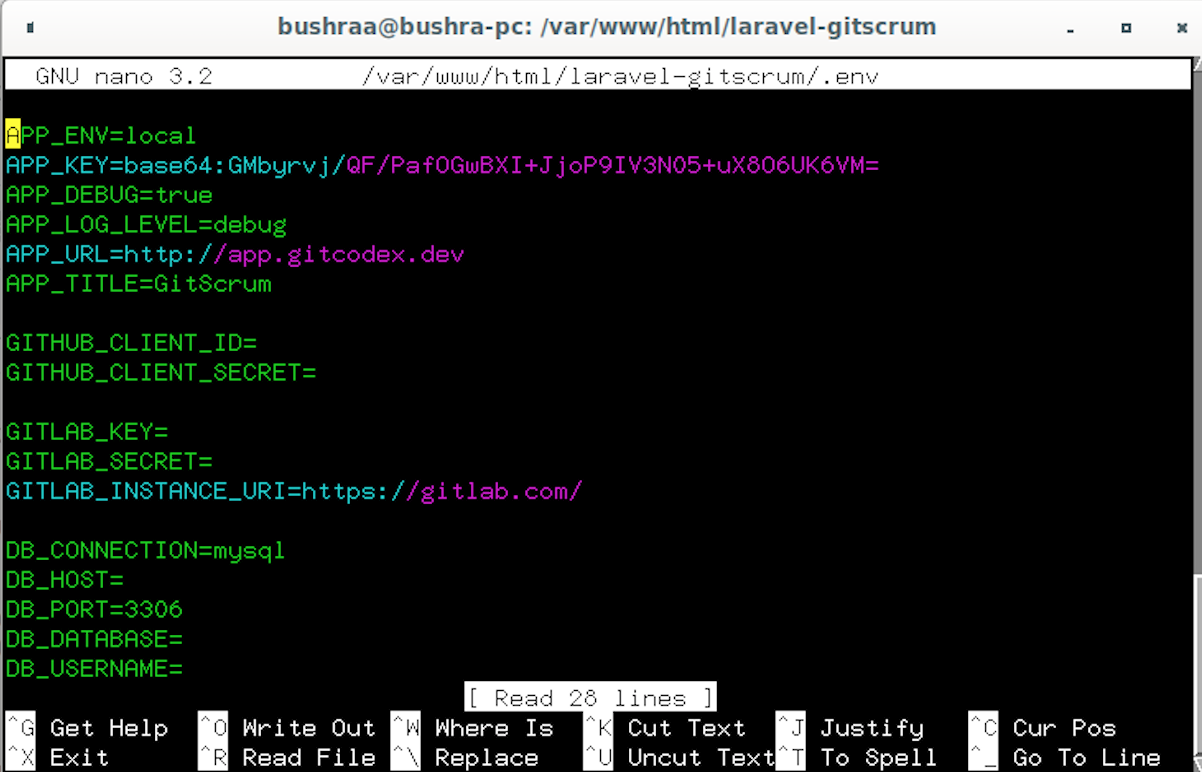
Here, provide the Client ID and Client Secret, then close the file using the Ctrl+O shortcut.
Run the following command to migrate the database:
![]()
Then, enter the following command:
![]()
After that, change the permissions using the command given below:
The permissions will begin to change; once they are done, update the other set of permissions using the following command:

Configuring Apache for GitScrum
To configure the Apache virtual host for GitScrum, access the file using the following command:

Add the following lines of code to the file. Replace ServerAdmin and ServerName with the server you want to configure it with.
ServerAdmin [email protected]
# Admin Server address
DocumentRoot /var/www/html/laravel-gitscrum/public
# Path to the document root directory
ServerName test.website.com
# Name or URL of the the server
<Directory /var/www/html/laravel-gitscrum/public>
Options FollowSymlinks Allow
# Path or directory and the permissions
Override All Require all granted </Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
# Calling the error logs if any
CustomLog ${APACHE_LOG_DIR}/access.log
# Calling the custom logs
combined </VirtualHost>
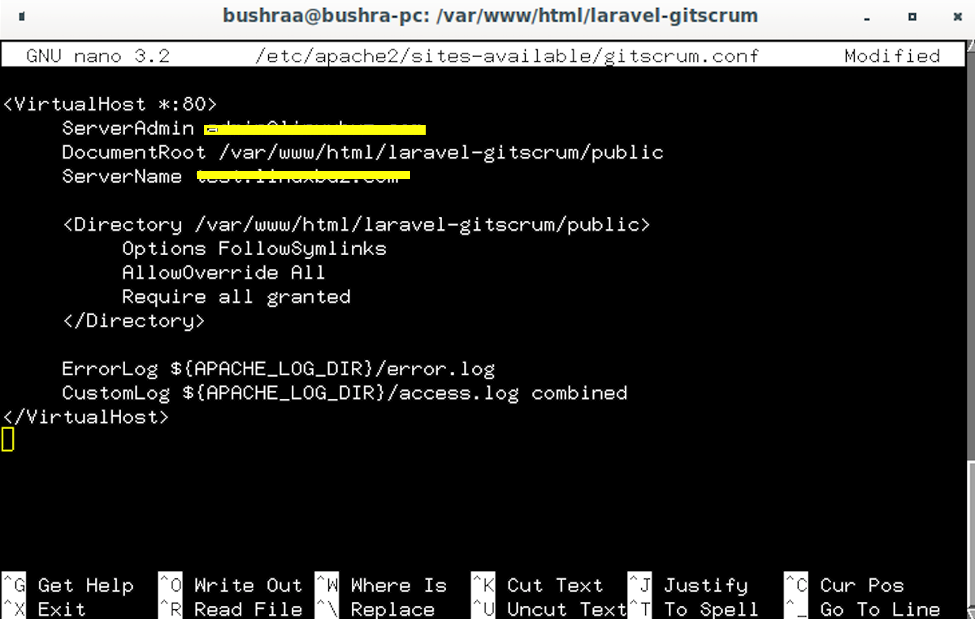
Save the file. To check the Apache configuration, use the following command:
![]()
The syntax OK means that the output is correct.

Enable the virtual host and Apache rewrite module using the command given below:
![]()
Now, rewrite the module using the following command:
![]()
Restart the Apache webserver/service to reflect these changes:
Here, provide the authentication to restart the service:
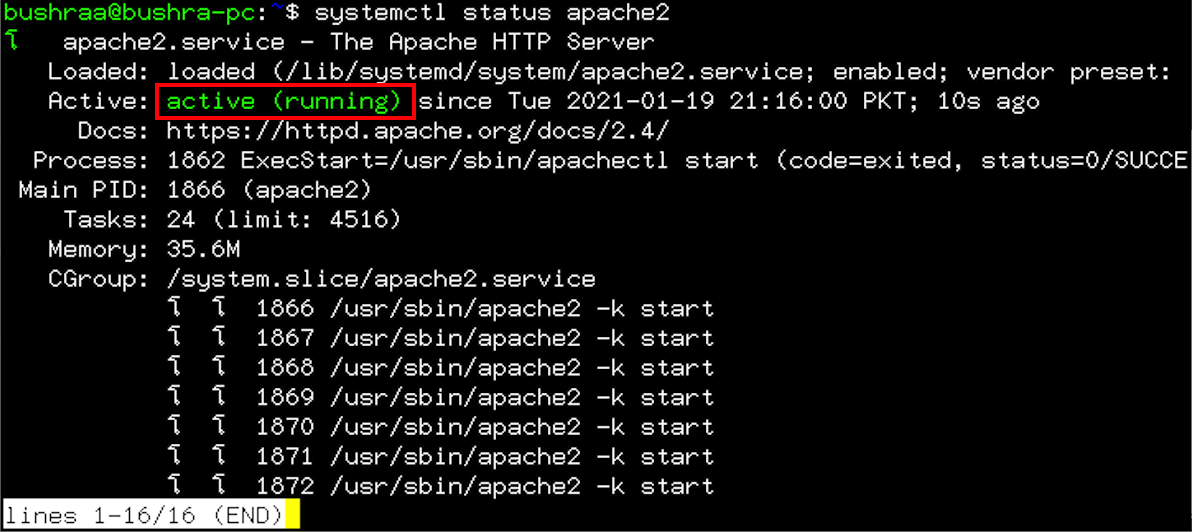
To check the status of the Apache service, use the following command:
![]()
The output shows that the server is running properly.
The last step is to access the GitScrum website based on the URL you used in the implementation process. Then, you will authorize your account to use GitScrum in Debian 10.

Conclusion
This article showed you how to install and configure GitScrum on a Debian 10 server. We began with the installation of the LAMP server, then installed Composer and GitScrum, and finally performed the necessary configurations. Feel free to use this method to install and configure GitScrum using Apache and other supporting packages on your Debian 10 server.
]]>This article will elaborate you how to Squash all commits in a single commit in git. We have implemented all steps on the CentOS 8 Linux distribution.
Squash Commits into one with git
You can implement the git squashing into the following steps:
Step 1: Choose Start commit
To determine how many commits you need to squash, the following command you will run on the terminal:
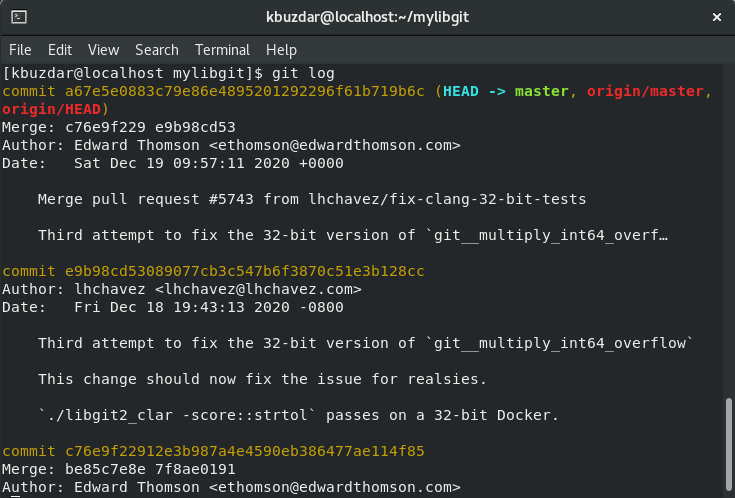
Now, you will invoke the git to start an interactive rebase session by using the following command:
In the above HEAD~N, the ‘N’ is the total number of commits you have determined from the ‘git log’ command. Let’s assume, the number of commits is 4. Now, the command will change into the following form:
The following commits list will display on the terminal where each commits staring with the word pick.
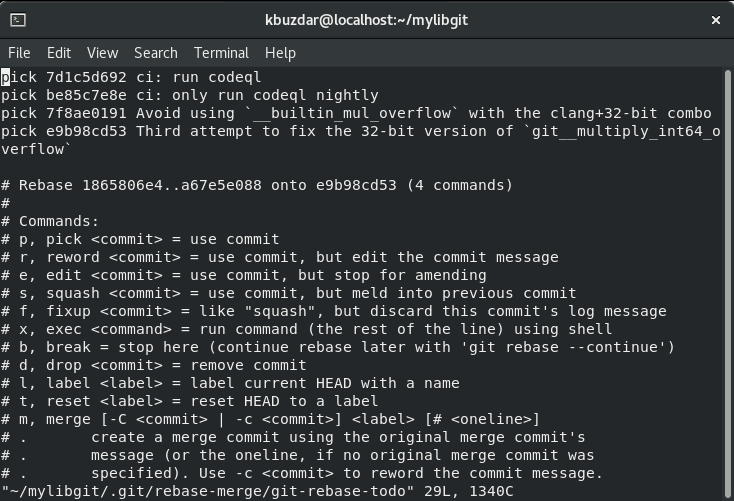
Step 2: Change Pick into Squash
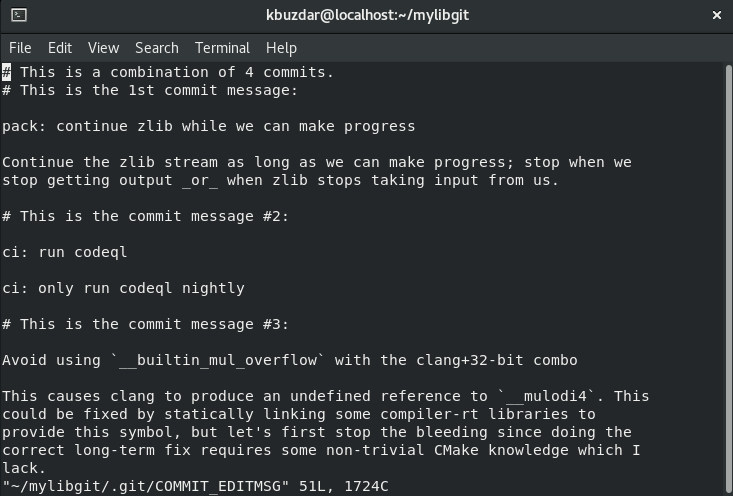
Here, we will mark all commits as squashable, leave the first commit that will be used as a starting point. So, change the vim editor into the insert mode by pressing ‘i’ and change the all pick commit into the squash except the first commit. Now, press ‘Esc’ to change the insert mode and press ‘:wq!’ to save all changes and quit. If you are using the simple text editor then, you can simply change the ‘pick’ word into the ‘squash’ and save changes. After that, you will see the following window on the terminal:
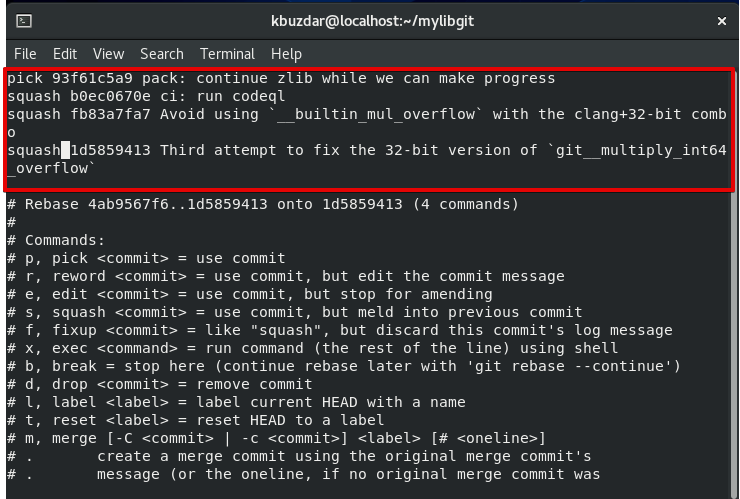
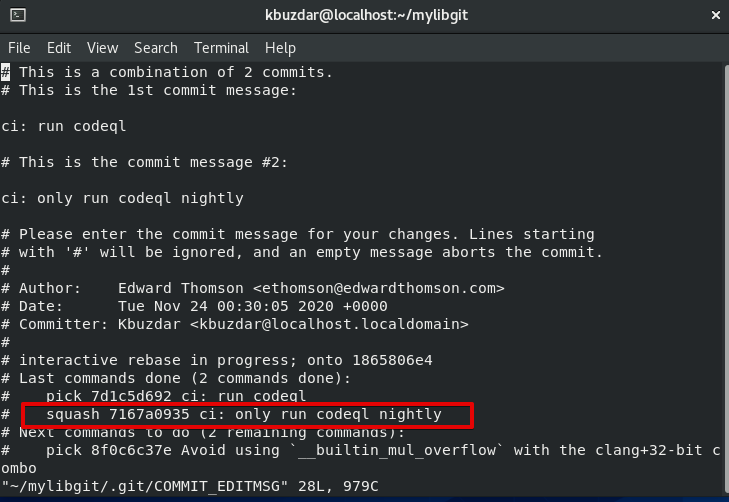
When you will leave this shell, you will see the following messages on the terminal window:
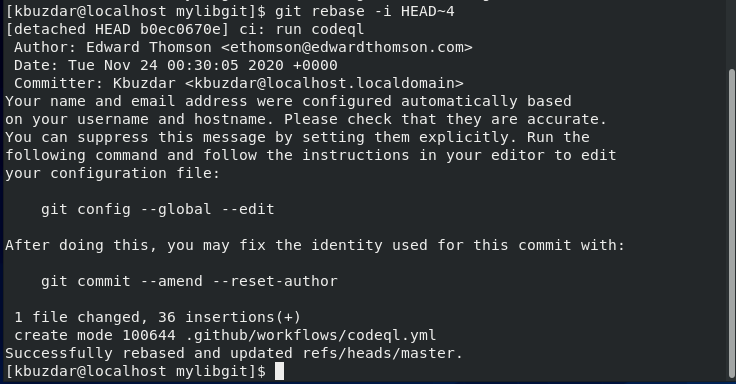
If you will squash all then, you will see all commits combined into a single commit statement that will display on the terminal:
Conclusion
By using the git squash, you can easily squash or compress many commits into a smaller single commit. You can use this technique to fix documentation spelling mistakes. We have implemented git squash in this article. We have also seen how we can make history clean using the git rebase and squash commands.
]]>Method of using the “.gitignore” File in Ubuntu 20.04
To use the .gitignore file in Ubuntu 20.04, we will walk you through the following nine steps:
Step 1: Acquire the Test Repository
Instead of creating our own project repository, we have used a sample repository available at GitHub. You need to acquire this repository by running the command mentioned below:

Once the specified repository has been cloned to your Ubuntu 20.04 system, it will display the following status on the terminal:

Step 2: Create a Sample File to be ignored
Now we need to create a sample file that we want to be ignored in our project directory. For that, we first need to go to our project directory by running this command:
Here, you need to provide the path where you have cloned the test repository.
![]()
Once you are within the test repository, you can create a sample file in it by running the following command:
![]()
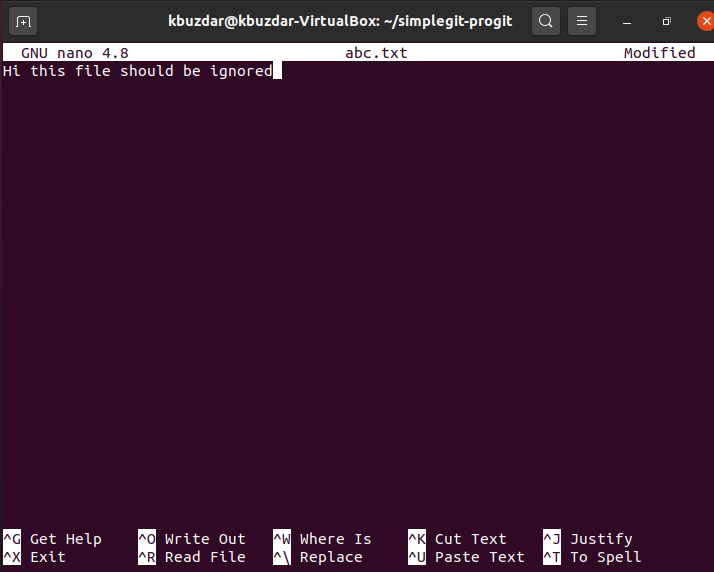
When this file opens up with the nano editor, you can write any random text in it, as shown in the image below, after which you can save this file.
Step 3: Create the .gitignore File
Once we have created a file that we want to ignore in our next commit, we will create the .gitignore file in our project repository by running the following command:
![]()
Step 4: Add the Files to be ignored in the .gitignore File
When the .gitignore file opens with the nano editor, you have to add the name of the file that you want to ignore to the .gitignore file. In our case, it is the abc.txt. After adding this file to the .gitignore file, we will simply save it. You can add as many files as you want to ignore in the .gitignore file in separate lines.

Step 5: Reinitialize Git
Once we have made the desired changes, we have to reinitialize Git by running the following command:
![]()
If this command manages to reinitialize Git successfully, then you will be able to see the message shown in the image below.

Step 6: Add the Newly Made Changes to your Repository
The next step is to add the newly made changes to our project repository by running the following command:
![]()
If the changes are successfully added to your project repository, then the system will not display any messages on the terminal, as shown in the image below.
![]()
Step 7: Check the Current Status of Git
Now before committing these changes to Git, we will check the current status of Git with the following command:
![]()
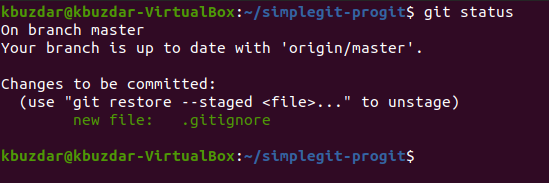
The current status of our Git project repository is shown in the image below.
Step 8: Commit all the Changes
Now we will commit these changes by running the following command:
Here, you can replace “Message to be Displayed” with any message of your choice that you want to be displayed with your recent commit.

The results of our recent commit are shown in the image below.

You can easily see from the image shown above that only the .gitignore file has been committed and not the abc.txt file since we wanted to ignore it in our commit. It means that Git has successfully managed to ignore the file that we mentioned in our .gitignore file while committing the changes.
Conclusion
By following today’s tutorial, you can easily add as many files as you want to ignore while doing a commit in your .gitignore files. In this way, you will not only save these files from getting messed up accidentally, but it will also save your resources that will be spent on committing irrelevant files.
]]>In this article, we will give you an idea about how to use Git submodules in an external Git repo in the Linux system.
Prerequisites
Make sure that Git is already installed on your system.
To verify the installation of Git, type the following command on your terminal:

We have implemented all commands related to Git submodules on CentOS 8 Linux distribution that we will discuss in detail in the below-mentioned steps:
When do Git Submodules should be used?
For strict version management of your project’s external dependencies, then you can use Git submodules features. The following are scenarios for where you can use git submodules:
- When a subproject or external component is changing rapidly, or upcoming changes may break the configured API, then, in this situation, lock the code for a particular commit for your project safety.
- When you have a specific project with a third party, and they want to integrate a new release inside your project.
Add new Git Submodule
The Git submodule add command is used to add a new submodule to an existing Git repository. Open the terminal from the left sidebar panel in the CentOS 8 system. Using the following example, we can explain better, in which we will create a new empty Git repository and then add Git submodules.
$ cd git-submodule-demo/
$ git init

In the above-mentioned commands, first, we have created a new directory with the name ‘git-submodule-demo’ and navigate in this directory. We have initialized this directory as a new Git repository.
Now, add a new Git submodule by using the ‘git submodule add’ command in which we have used URL as a parameter that refers to a particular Git repository. We have added a submodule ‘awesomelibrary’ in the above newly created repository.

Git will clone this submodule. Once the submodule process is completed, you can check the current status of your git repository by running the following command:
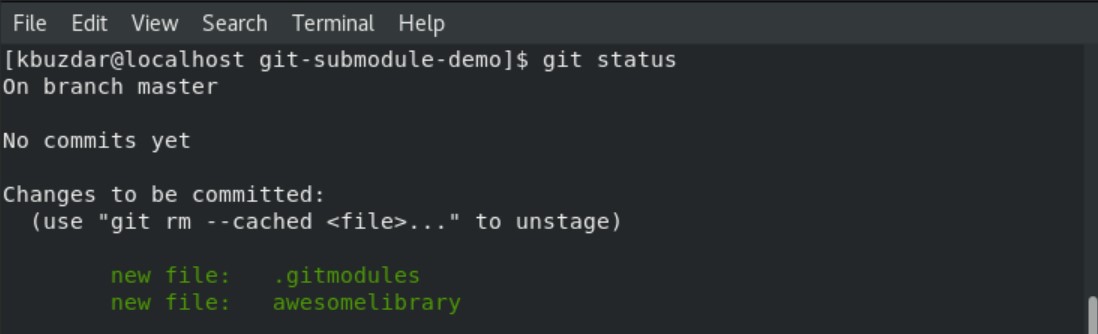
When you run the above-given command on the CentOS 8 terminal, you will notice two new files are in this repository. One is ‘.gitmodules’ and ‘awesomelibrary’. Now, you can commit these files into the original Git repository by executing the ‘git add’ and ‘git commit’ commands.

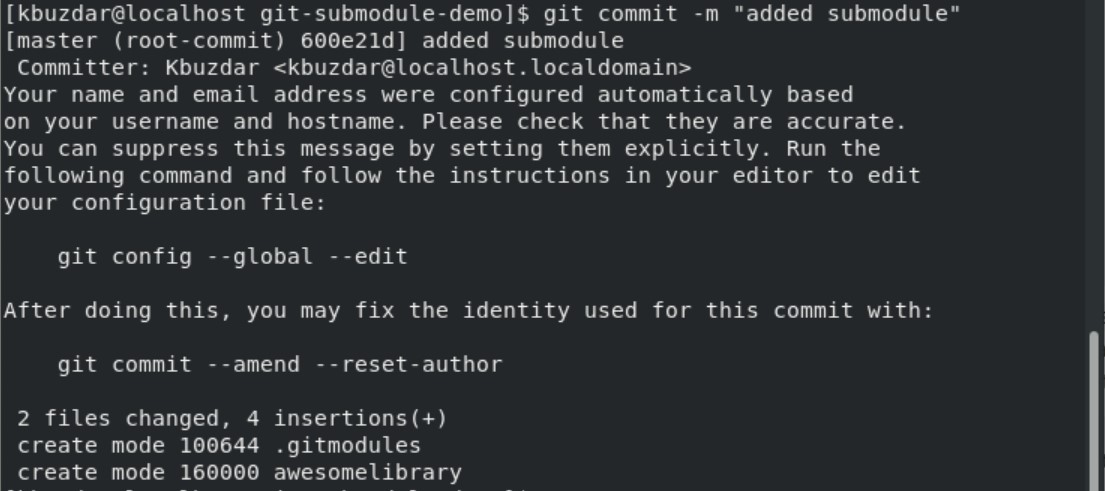
Clone Git Submodules
Clone the submodules using the Gsit clone command. The below command will create directories that contain submodules, but you can’t see the file inside them.

There are two additional commands used to create submodule files. One is the ‘.git submodule init’ that copies ‘.gitmodules’ mapping into the local ‘.git/config’ file. The ‘git submodule update’ command updates all data of the submodule project and verifies the changes into the parent project.
$ git submodule update

Now, we will navigate into the awesomelibrary submodule directory. We will create a text file with the name ‘new_awesome.txt’ by adding some content.
$ git checkout -b new_awesome
$ echo "new awesome file" > new_awesome.txt
$ git status

Here, we will add and commit changes to this new file to the submodule.
$ git commit -m "added new awesome text file"
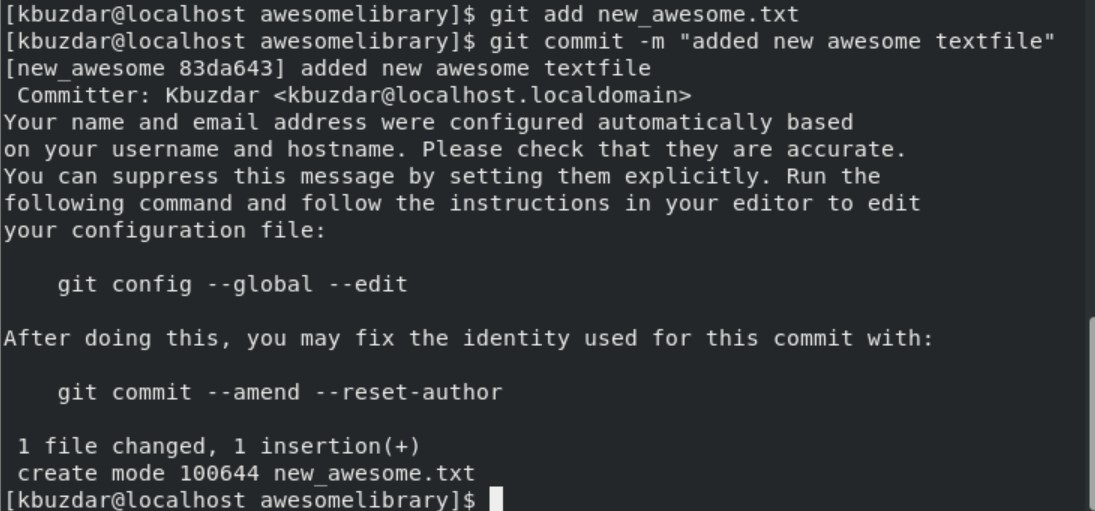
Now, navigate into the parent repository and review the status of the parent repository.
$ git status
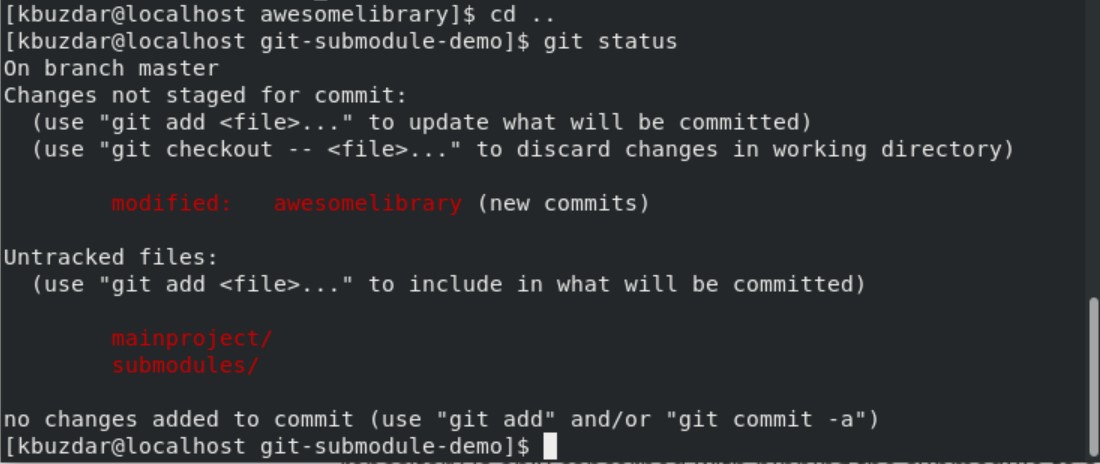
As you can see, ‘awesomelibrary’ has been modified.
Conclusion
We have seen in this article that by using the Git submodule, you can easily use the Git repo as an external dependency management tool. Go through with the uses and drawbacks of Git submodules before implementing this Git feature and then adopt it.
]]>Method of Reverting to a Previous Commit in Git in Ubuntu 20.04:
For explaining to you the method of reverting to a previous commit in Git in Ubuntu 20.04, we have designed an example scenario. In this scenario, we will first modify an already existing file named abc.txt. Also, we have two other files in our test project repository named Stash1.txt and Stash2.txt that we had not committed previously. So, we will be committing all of these changes at once. Then we will try to revert to a previous state i.e. a state in which neither the files Stash1.txt and Stash2.txt existed nor the file abc.txt was modified. To further elaborate on this scenario, we would like to walk you through the following steps:
Step # 1: Switch to your Git Project Directory:
First, we will go to the directory where our Git project repository resides in the manner shown below:
![]()
Once this command will execute, it will change the default path of your terminal as shown in the following image:

Step # 2: List down the Contents of your Git Project Directory:
Now we will list down the contents of our test project repository to see which files are already there. The contents of our Git project repository can be listed using the command stated below:
![]()
The contents of our Git project repository are shown in the following image:

Step # 3: Open and Modify any File within your Git Project Directory:
We have picked the file abc.txt from our Git project repository for modification. Now we will open this file with the nano editor in the manner shown below:
![]()
This file has some random text written in it as shown in the following image:
We will modify this text by adding a “not” in it as shown in the image below. After making this modification, we will simply exit from the nano editor while saving our file abc.txt.

Step # 4: Reinitialize your Git Project Repository:
After making all the desired changes, we need to reinitialize our Git project repository with the help of the following command:
![]()
After executing this command, Git will reinitialize while displaying the message shown in the image below on your terminal:

Step # 5: Add the Changes to your Git Project Repository:
Now we need to add the changes to our Git project repository by executing the following command:
![]()
The successful execution of this command will not display anything on our Ubuntu 20.04 terminal.
Step # 6: Commit the Newly Made Changes in your Git Project Repository:
After adding the changes to our Git project repository, we will commit these changes with the following command:
Here, you can change “Message to be Displayed” with the actual message that you want to be displayed while this command executes.
![]()
When this command will execute, you will notice that our two files that were uncommitted previously i.e. Stash1.txt and Stash2.txt will be committed.

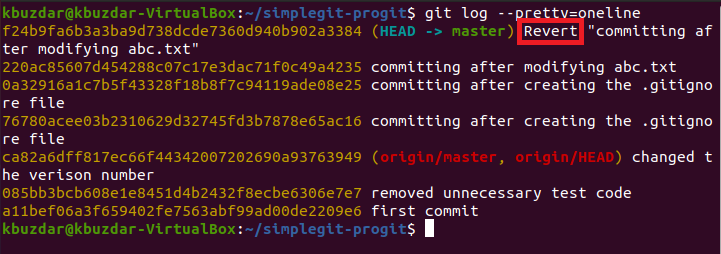
Step # 7: Check Git Commit History:
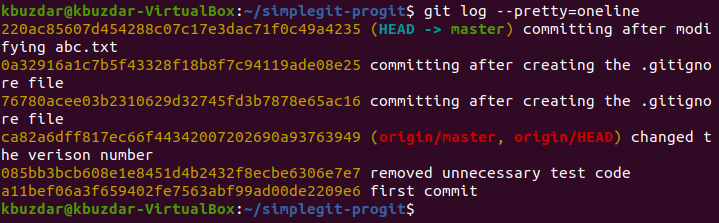
Now we will check the Git commit history to see whether our last commit has been logged or not. The Git commit history can be checked with the following command:
![]()
You can easily see from the Git commit history shown in the image below that the Head is pointing to our last commit i.e. the transaction in which we committed the files Stash1.txt, Stash2.txt, and abc.txt (after modification). Also, we will note the transaction ID of this commit from the commit history so that we can revert it in the next step while making use of this ID.
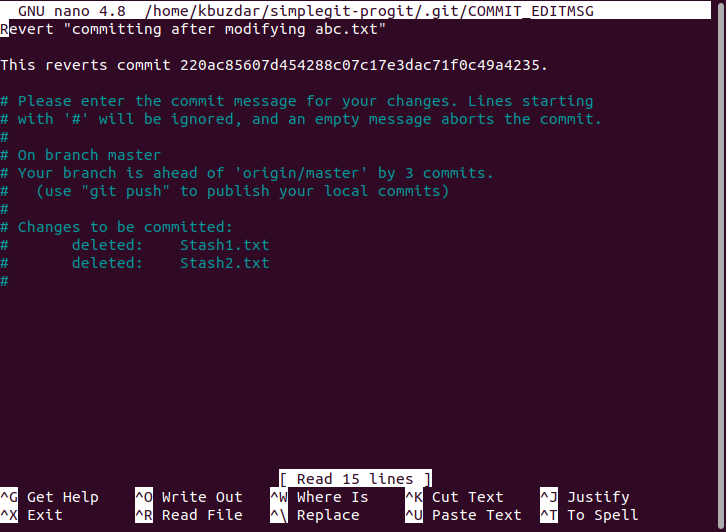
Step # 8: Perform the “git revert” Operation:
The first five characters of the transaction ID of our last transaction are 220ac. These characters will be used for referring to this commit. Now we will revert this commit with the help of the following command:
![]()
When this command will execute, it will display a message within nano editor that your transaction with the transaction ID 220ac will be reverted as shown in the image below:
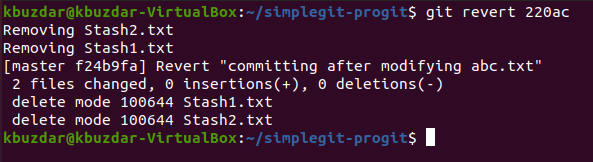
You need to press Ctrl+ X after seeing this message so that you can see the exact status on your terminal as shown in the following image. This status will tell us that the changes made earlier i.e. the modification of abc.txt and the addition of Stash1.txt and Stash2.txt have been reverted. It also means that now our file abc.txt will be back in the previous state i.e. it will represent its original content without modification. Moreover, the files Stash1.txt and Stash2.txt will have been deleted.
Step # 9: Check the Git Commit History once Again:
Now we will check our Git commit history once again to see the current situation. If the revert operation has been performed successfully, then the Head of our project will be pointing to this revert transaction as highlighted in the image shown below:
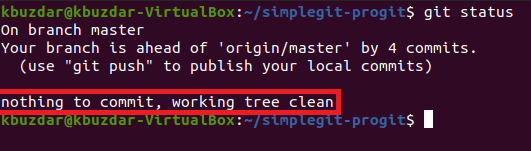
Step # 10: Verify if the “git revert” Command has worked successfully or not:
Although, we have already seen that our project Head is currently pointing to the revert transaction which is enough to indicate that the “git revert” command has functioned properly. However, we can still ensure it by checking the Git status. Here, we will be able to see that there will be no more files to be committed as the ones that were there previously i.e. Stash1 and Stash2 have already been deleted by the revert operation. Therefore, there will be no more new files to be committed as shown in the following image:
Also, we can try to list down the contents of our Git project repository to confirm the deletion of the files Stash1.txt and Stash2.txt as shown in the image below. A point to be noted over here is that the files Stash1.txt and Stash2.txt have been deleted by our revert operation solely because before committing the transaction having the transaction ID of 220ac, there was no existence of these two files. That is why, as a result of reverting this commit, these files will not exist anymore. However, if you will perform the revert operation once again on this revert transaction i.e. you will try to nullify the effect of the revert operation you have just performed, then you will be able to see these two files again.

Finally, we can also check our file abc.txt once again to see if it is back with its original content or not. We will simply open this file again with the nano editor and you will notice from the following image that the modification that we did earlier to this file has been reverted.
Conclusion:
By going through the detailed scenario presented to you in this article, you will hopefully be able to use the “git revert” command in Ubuntu 20.04 in a very effective manner. This command will cancel the effect of any previous transaction while maintaining its entry within the “git log” so that at any point in time, you can conveniently go back to that transaction. In other words, we can say that the “git revert” command commits a transaction that is an exact inverse of a command that was committed previously (without deleting the previous commit). That is exactly why it manages to cancel its effect.
]]>In most of the legacy version control systems such as CVS in which the difficulty of merging restricted it to advance users. The modern centralized version control system like subversion requires commits to be made on the central repository. When talking about Git, we have to create a new branch code to add a new feature or bug fix.
In this article, we will show you how to create a new branch, add commits to new features, and merge master with a new branch.
Let’s start the demo of merging two branches. We have executed all commands on CentOS 8 Linux distribution which are mentioned below in detail:
Git branch command
If you want to view the list of all existing branches in a particular repository, then using the ‘git branch’ command, you can easily do this task. An asterisk sign will have appeared on the currently active branch. Type the following command to show all branches list:
The above command will only list branches. Use the following command to create a new branch in a repository.

The ‘git branch new_branch’ will create a new branch in your current Git repository.
You should know that when git creates a new branch, it does not create a new commit set to represent this new branch. In Git a branch behaves like just a tag or a label that you can use to point to a particular commits string. Therefore, using the Git repo, you can create multiple sets of commits from a single base.
Git checkout command
We have created a new branch above by using ‘git branch new_branch’. But, the active branch is the ‘master branch’. To activate the ‘new_branch’, execute the following command on the terminal:
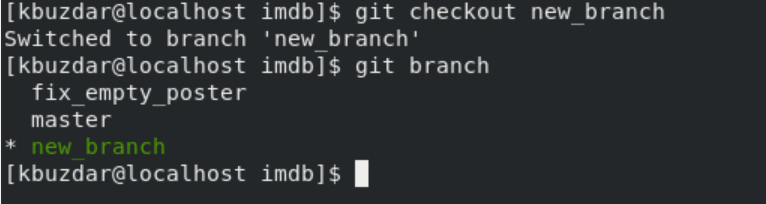
The above-given command will switch from master to the new_branch. Now, you can work on this newly created branch.
Now, you will add some commits or implement a new feature on the ‘new_branch’. In your case, you will add a function or code to a newly-created branch and merge it back into the master or main code branch.
$ git add –A
$ git commit –m "Some commit message for display."

Now, you will run the following command to activate the master branch.

Git merge command
Now, use the following command to merge the new feature master branch.
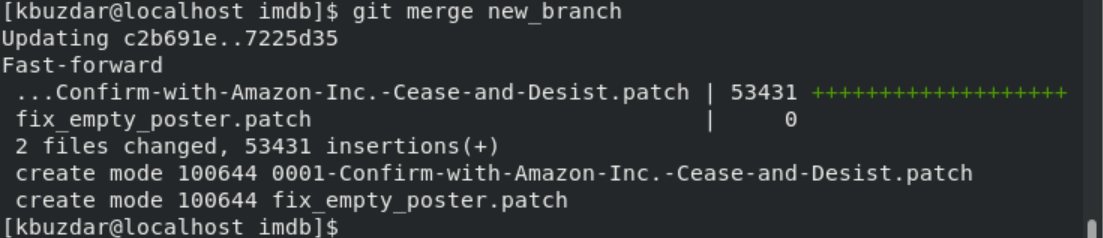
Using the ‘git merge new-branch’ command, you can merge the specified branch into the currently active master branch. The new feature now has been added with the master branch. Using the following command, you can check commits and details:

Conclusion
To summarize all the above details, we have created a new branch ‘new_branch’, activate it, and add some new commits or new features to it. Once you have done all changes, merge this ‘new_branch’ back into the master branch. We have learned how to merge one branch with another branch in Git in this article.
]]>Methods of Showing the Git Tree in Ubuntu 20.04 Terminal
The following sections cover several different methods for displaying a Git tree in your terminal. Before attempting these methods, we will first navigate to our test project repository by running the following command:
You can provide your own path with the “cd” command, i.e., the location in which your test project repository currently exists.
![]()
After running this command, the path in your terminal will instantly change, as shown in the image below:

Method 1: Using the graph Flag with the git log Command
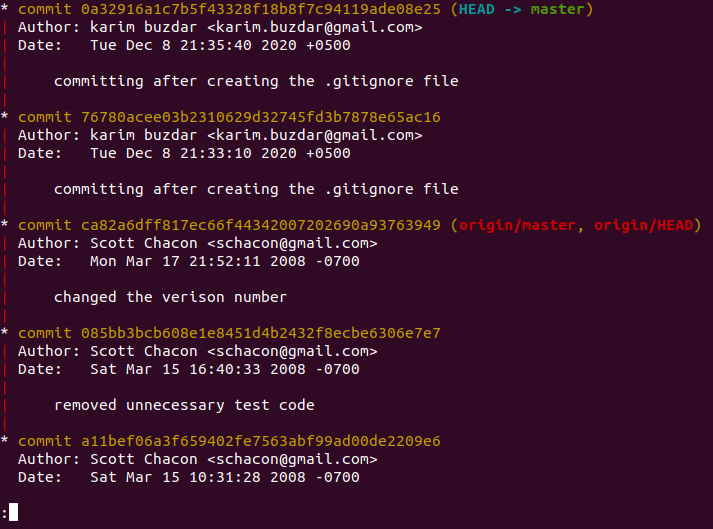
Once we have navigated to the test project repository, we will run the following command to show the Git tree in our Ubuntu 20.04 terminal:
![]()
Our Git project tree is shown in the image below:
Method 2: Using the oneline Flag with the git log Command
We can also create the Git tree in our terminal by running the following command:
![]()
Our Git project tree is shown in the image below:

Method 3: Using the pretty Flag with the git log Command
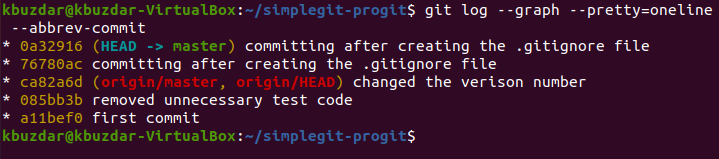
This is yet another method that to create the Git tree in your Ubuntu 20.04 terminal. You can create the Git tree using this method by running the following command:

Our Git project tree is shown in the image below:
Conclusion
This article showed you three different methods for creating a Git tree in your Ubuntu 20.04 terminal. A question that still might concern you is, “What is the difference between Method # 2 and Method # 3, because apparently both of them show the exact same output?” Well, this difference can only be seen if your Git log is rich enough, i.e., it contains a significant number of commits. If you perform both Method #2 and #3 on a Git project repository that contains enough commits, then you will see that the output of Method # 2 will be more technical, as it may contain some ASCII values; whereas, the output of Method # 3 will be more user-friendly, which would solely be due to using the “pretty” flag in that method.
]]>If you have the experience of working with Git very frequently, then you must know that you can have multiple branches within a single Git project repository. However, the head of your project repository always points to your recently committed branch. It means that you can only make changes to that branch where the head is pointing in your Git project repository. But at times it happens that you are working on one branch and you realize that you need to add something to a previously committed branch. Also, you do not want to commit the branch yet that you are currently working on as you still want to work on it.
So you start exploring the solutions through which you can switch your context for a while for which the data of your current working branch is also saved temporarily without being committed. The “git stash” command acts as a blessing in disguise in such situations. The sole purpose of using this command is to save the changes temporarily without committing them while you can work with some previously committed branch. After that, you can simply switch back to your current branch by restoring your stashed work. To explain to you the usage of the “git stash” command in Ubuntu 20.04, we have designed the following helpful yet simple tutorial through which you can easily grasp the working of “git stash”.
Method of Using “git stash” in Ubuntu 20.04
Stashing literally means keeping something stored or saved temporarily. For using the “git stash” command in Ubuntu 20.04, we have made use of a test repository named simplegit-progit. The exact sequence of steps is discussed below:
Step # 1: Navigate to your Git Project Repository
First, we have to navigate to the directory where our Git project resides. We can use the following command to do so:
![]()
Here, you can give any path from your Ubuntu 20.04 system where your respective Git project repository resides. You can easily see from the image shown below that the path of our terminal is now pointing towards our Git project repository:
![]()
Step # 2: Make some Random Changes to your Project Repository
Now for demonstrating the purpose and usage of the “git stash” command in Ubuntu 20.04, we will be doing some random changes in our Git project repository. First, we have created a new text file named Stash1.txt in this directory by issuing the following command:
![]()
After issuing this command, we will type some random text in our file, as shown in the image below after which we can save and close it.
Then we have created another text file in the very same project repository named Stash2.txt by issuing the following command:
![]()
After that, we have simply typed some random text in that file, as shown in the image below. Then we have saved and closed our text file.
Step # 3: Reinitialize your Git Project Repository
Now we have to reinitialize our Git project repository with the following command:
![]()
Once Git manages to reinitialize your project repository, it will display the message shown below on the terminal:

Step # 4: Add the Changes you have made to your Git Project Repository
Now we need to add the changes that we have just made, i.e. the two text files that we have created to our Git project repository with the help of the following command:
![]()
If your newly made changes are added successfully to your Git project repository, then your terminal will not display any error messages as shown in the image below:
![]()
Step # 5: Check the Current Status of Git
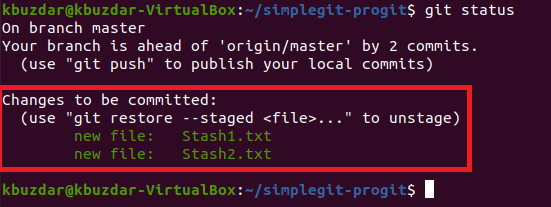
Now we need to check the status of Git. Ideally, in this status, we should be able to see all the changes to be committed, i.e. the names of the two text files that we have just created. Git status can be checked with the following command:
![]()
You can easily see from the highlighted section of the image shown below that the two newly created text files are in fact, the changes that are to be committed next.
Step # 6: Issue the “git stash” Command
Then comes the time of issuing the “git stash” command since instead of committing the new changes, we want to save them temporarily. The “git stash” command can be used in the following manner:
![]()
If this command works successfully, it will display a message on the terminal saying that your working directory has been saved as shown in the image below:

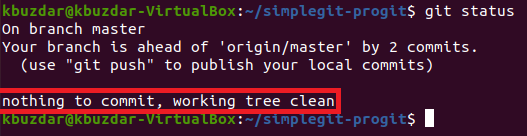
Step # 7: Check the Status of Git Again to find out if the “git stash” Command has worked properly or not
If our changes have been stashed successfully, then check the status of Git will reveal that there are no changes to be committed for now, as shown in the following image:
Step # 8: Restoring your Stashed Changes to Work with them again
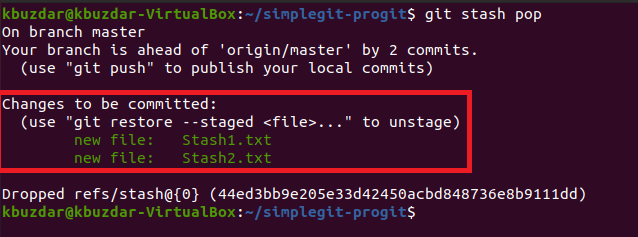
Now, whenever you feel like working with your stashed changes once again, for example, you may want to commit them, then you have to restore them first with the command stated below:
![]()
After executing this command, you will notice that the changes that you have previously made to your Git project repository, that was stashed before, are ready to be committed now as highlighted in the following image:
Conclusion
The “git stash” command is an extremely useful and frequently used command within the Git environment. It not only stores the current working branch temporarily but also allows you to work with any of your previously committed branches very conveniently. After performing all the desired operations on your previously committed branches, you can simply make use of the “git stash pop” command for getting back to your current working branch.
]]>In this article, we will discuss the concept of Git tags and how the git tag command does work. We will cover various kinds of tags, how to create new tags, tag listing, and deletion of a tag, and more in this article. A few commands we have executed on the Ubuntu 20.04 system, which we will elaborate on in the rest of the section.
Create a new Tag
There are following two different types of Git tags:
- Annotated tags
- Lightweight tags
Annotated tags
The annotated tags are saved as a full object in the database of Git. These types of tags store some extra metadata information such as the name of the tagger, tagger email id, and date. Annotated tags stores with a tagging message. It is best practice suggested in git is to store git tags in the form of annotated tags over lightweight. Using the annotated tags, you can store all the associated meta-data in the database.
To create an annotated tag, open the terminal application by pressing Ctrl+Alt+t and run the following command:

In the above command, we have tagged the current HEAD by using the git tag command. The user provides a tag name ‘Release_1_0’ with the -a option, and the tag message is provided with the –m option.
Lightweight tags
This type of tags is used for ‘bookmarks’ to a commit; Lightweight tags are just a name or a specific pointer to a commit. Lightweight tags are useful for quick link creation to relevant commits.
The following command is used to create lightweight tags:
Example:
In the following example, let’s suppose we have created a lightweight tag with the name ‘Release_1_0’.
These types of tags are stored in the current working .git project repository.
View Tags
Once you have created tags, you can show tag details by using the following command:
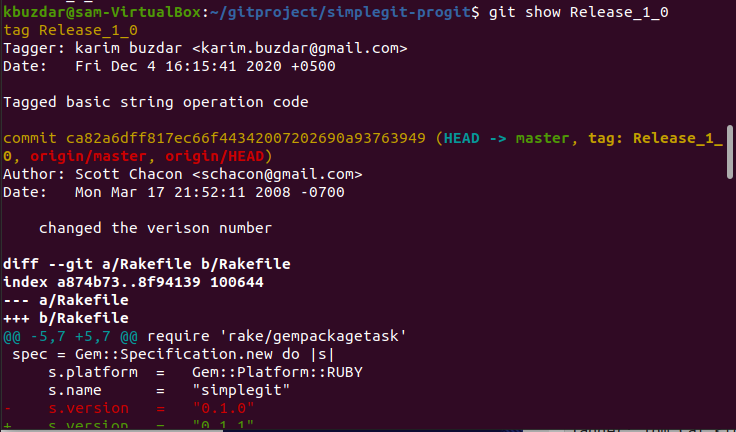
In the above command, we have printed the tag ‘Release_1_0’ details. In the following image, the tag details are displayed:
Listing Tags
You can also display all the tags names by using the following Git tag command with option –l:
![]()
Removing or Delete Tags
First, to list all store tags in a repository, run the below-given command:
Now, using the following command, you can remove or delete tags from the remote as well as the local repository.

Conclusion
We have learned how to use Git tags in this article. Tagging is a useful feature through which you can create a clone image of a Git repo. You can give a better, some meaningful name to a specific git project. According to your convenience, you can create two different types of tags, annotated or lightweight, which we have discussed above. I hope now you have a better understanding of the usage of Git tags in your Git project repo.
]]>This article will give you a demo on how to check or view Git logs using Ubuntu 20.04 system. All the below-given examples we have taken are from a simple Git project called ‘simplegit’. First, you need to get this project. Therefore, you have to open the ‘Terminal’ application by pressing ‘Ctrl + Alt + t’ and execute the following command to clone the ‘simplegit’ repository on your system:
Viewing Git Commits Logs
You can view the commit history in the Git log by using the following command:
As we have mentioned above, all most recently occurred commits will be displayed first.
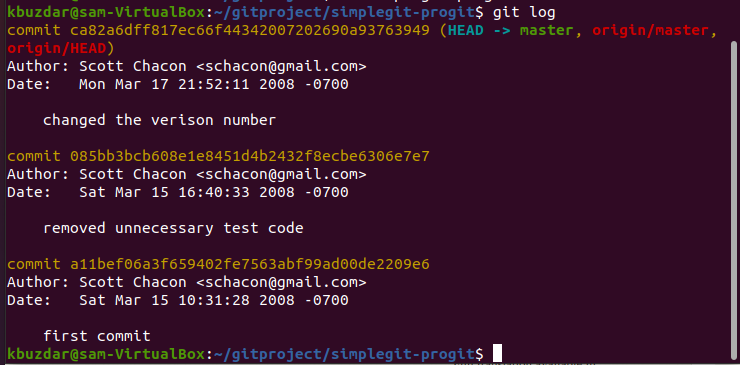
You can see in the above-displayed image the ‘git log’ command list commits with the author’s name along with the email address, date, and the commit message.
Git log command options
Several options are available, which you can use with the ‘git log’ command to display the same result that you are searching for. Below, we have mentioned some options that are most popular related to the git log command.
Display recent commits
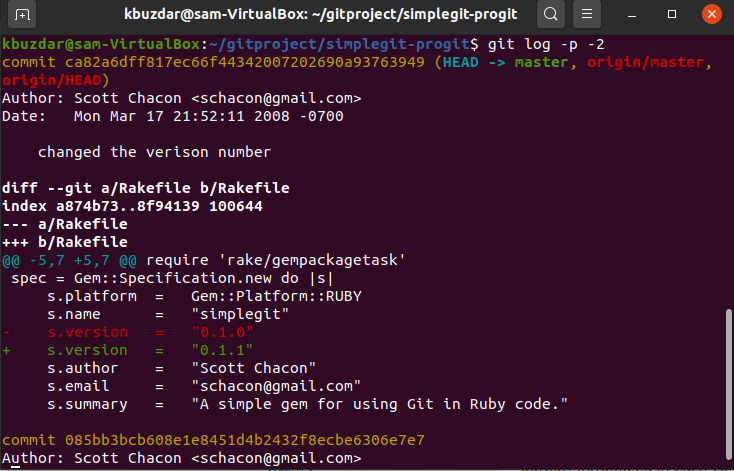
The best option -p that is available about committed logs is the patched output, which limits the displayed log to the specified number ‘n’. It will limit the output and display the number of commits that most recently occurred. For example, we want to display only 2 recent commits log entries. Therefore, you have to run the following command:
Display each commit log summary
You can also display the complete summary of each commit with the ‘git log’. For example, you want to display the stat of each commit, then you can use the ‘–stat’ option with the ‘git log’ command as follows:
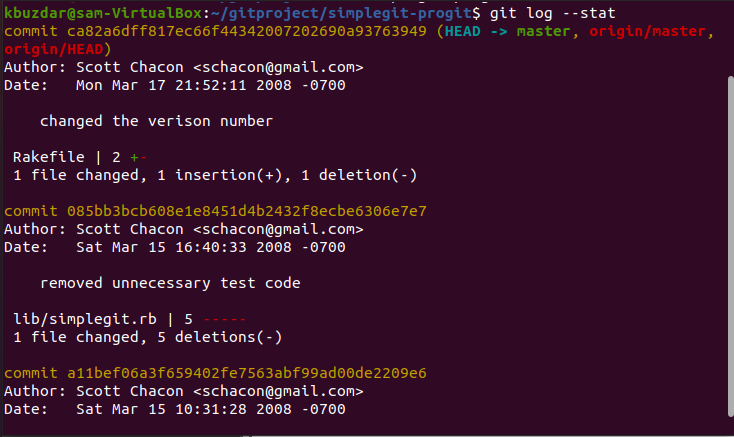
As you have noticed from the above output, the –stat option will also print the details about the modified files, the number of files added or removed, and display the files that have been changed after each commit entry. Moreover, a complete summary will be displayed at the end of the output.
Display each commit log in one line format
The –pretty option is useful for changing the output format. If you want to display each commit value in just one line, then by using the following command, you can print each commit log in a single line:

Display customized output of Git log
Using the format option, you can specify your output log format. This ‘format’ option is useful, especially when you want to create output for machine parsing. Using the following format specifiers, with format option, you can generate customize ‘git log’ output:

You can explore more options related to the ‘git log’. Here, we have mentioned the following options that will help you in the future:
| Options | Description |
|---|---|
| -p | It displays the patch introduced with each commit log. |
| –stat | It displays the complete summary of each commit. |
| –shortstat | It only shows you the inserted, deleted, and modified lines. |
| –nameonly | It shows a list of the names of files that have been updated after the commit detail. |
| –name-status | It shows the information of the affected files with added, updated, and deleted files details. |
| –prety | Shows output in the specified format |
| –oneline | Shows output in just a single line |
| –graph | Shows the ASCII graph of merge history and branch |
| –relative-date | Using this option, you can use the relative date like 3 weeks ago instead of specifying the full date format. |
You can get more help from the man pages of ‘git log’. Type the following command to display the man page:
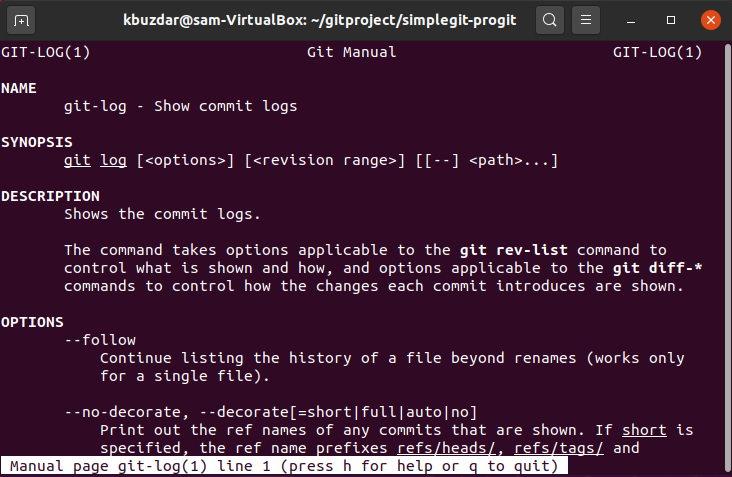
We have discussed how to view Git commits log on Ubuntu 20.04 system in this article. We have also listed and explained different options that you can use with the ‘git log’ command.
]]>Purpose of the “git merge –abort” Operation:
Before understanding the usage of the “git merge –abort” operation, we must realize why do we need such an operation in the first place. As you all know that Git maintains a history of all the different versions of a file or a code; therefore, the different versions that you create are known as Git commits. Also, there is a dedicated current commit, i.e., the version of the file that you are currently working on. At times, you might feel the need to merge a previously committed file with the one you are currently working on.
However, during this merging process, it can happen that any other colleague of yours is also working on the same file. He might discard the changes that you have kept or modify the lines that you have just added to the file. This scenario can lead to a merge conflict in Git. Once a merge conflict in Git arises, and you try to check the status of Git, it will display a message that a merge conflict has occurred. You will not be able to do anything with that particular file until you manage to fix that conflict.
This is where the “git merges –abort” operation comes into play. Basically, you want to go back to the old state where you can have your current version of the file unchanged, and you can start making the changes all over again. In this way, you will ensure that no such conflicts arise again in the future. So the “git merge –abort” operation essentially terminates the merger that you have just carried out and separated the two versions of your file, i.e., the current version and the older version.
In this way, the current version of your file will revert back to the same state as it was before you performed the merge operation, and hence you will be able to restore it without any potential difficulty. However, an important point to be noted here is that the “git merge –abort” operation only works if you have just merged your files and have not committed them yet. If you have already committed to this merger, then the “git merge –abort” operation will no longer serve the purpose; rather, you will have to look for other ways to undo the merger.
Conclusion:
By understanding the discussion that we did today, you will easily realize the purpose of the “git merge –abort” operation. This operation not only resolves the merge conflicts that arise before committing a merge but also helps in restoring your files to the same state in which they were before. In this way, your data is not lost, and you can conveniently start working on it all over again.
]]>Git is known to be the most popular version control system. The concept of version control becomes significant whenever we talk about teamwork and collaboration. For example, if multiple employees are working on a single project, then data consistency is a major issue that must be addressed. You cannot simply assume that a change made by one of the employees will automatically be notified to all other employees working on that project. Rather, there should be a proper mechanism through which data consistency can be ensured.
Now, if we talk about version control software or system, then as the name implies, its main job is to keep track of your version history. It means that all the changes made to any particular file will be considered as separate versions of that file. A version control software or system will essentially allow you to revert to an older version at any time you want as per your needs. Apart from this, a version control system like Git also ensures that the changes committed to any file have equal visibility to all the users who have access to that file so that they might not accidentally start working on an older version or a copy of that file.
Just like any other version control system, Git also allows us to perform certain operations on the files that we upload on it. Moreover, at any point in time, it also provides you with the ability to undo the changes that you have made to any particular file by resetting it. Today, we aim to unravel the difference between “git reset” and “git reset –hard” operations.
Understanding the difference between “git reset” and “git reset –hard”
Before understanding the difference between “git reset” and “git reset –hard” operations, we must be aware of some of the most important terminologies used with this version control system. A “Head” in Git is defined as a pointer, whose job is to point to the latest commit or change that you have made to a file. An “Index” is defined as a set of all the files that have been recently committed and are supposed to be committed next. Lastly, a “Working Directory” refers to the set of files from the whole file system on which you are working currently.
After learning about these terminologies, it will now be very easy for you to understand the difference between “git reset” and “git reset –hard” operations. As we already stated, there are multiple options that you can perform on a file that is uploaded on Git, similarly, “git reset” is defined as the default operation with which you can undo the last commit or change that you have made to the current file. Now, this operation comes with five different options, namely: hard, soft, merged, mixed, and keep.
Depending upon the option that you have selected or used with your “git reset” command, you are going to get a different “undo” level. The “git reset –hard” operation is considered the most effective operation if you wish to entirely get rid of your last commit. It means that when you perform this operation, the head of your file will change, i.e., it will no longer be pointing to your last commit. Not only this, but it will also clear out your last commit from your index and even change your current working directory.
On the other hand, if you use any other option with the “git reset” command such as “soft”, then doing this will only change the position of your head. Other than that, it will not bring about any changes to your index, nor will it change your current working directory. So, in short, we can say that “git reset” is a command, whereas “git reset –hard” is its variation that is used when you want to wipe out all the traces of your last commit.
Conclusion
By going through this detailed explanation on “git reset” and “git reset –hard” operations, you will easily be able to differentiate them from now on. Also, this article will guide you on which option you need to use with the “git reset” command depending upon your particular requirements.
]]>This article will explain the installation of the git environment and how to set up its variable on the Linux system. All steps we have performed on the Ubuntu 20.04 system in this article.
Prerequisites
You should have root account access, or you can run commands with ‘sudo’ privileges.
Installation of Git environment on Ubuntu 20.04
To install and Setup Git environment on your Ubuntu 20.04 system, you need to update the apt repository, that you can do by running the below-mentioned command:
The following command you will use to install the git-core package:
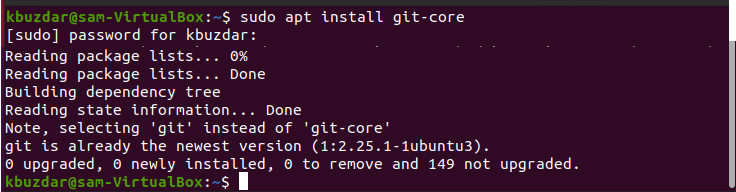
Once the installation of git is complete, now check the installed version by issuing the following command on the terminal:

As you can see in the above screenshot Git is installed on this system and working.
Customize Git Environment Variables
To set the Git environment variable, Git provides the git config tool. All the Git global configurations are stored in a .gitconfig file. This file you can easily locate in your system’s home directory. You need to set all configurations in global. Therefore, use the –global option, and if you do not use this option, then all configurations will set for the currently working Git repository. Users can also set up system-wide configurations. All the values in a Git store are in a file /etc/gitconfig that contains the complete configuration about every user and each repository on your system. If you want to configure or set these values, then you should have root privileges and use option –system with command.
SettingUser name
Setting the user.name and user.email information will show you in your commit messages. Set the user.name by using the following command:

Set User email
Similarly, you can your git email by running the below-given command:
![]()
Set other configurations
You can create some other configuration related to avoiding pull merge commits, color highlighting, etc.
To avoid merge commits pulling, you can set by using the following command:
![]()
To set the option related to color highlighting for Git console, use the below command:
$ git config --global color.status auto
$ git config --global color.branch auto

By using the gitconfig file, you can set the default editor for Git.
![]()
You can also set the default merge toll for Git as follows:
![]()
Now, use the following command to show the Git settings of the local repository:
The following result will show on your output screen:
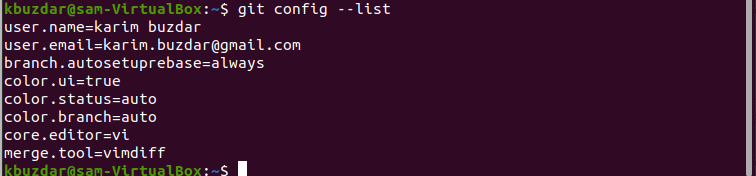
Conclusion
We have performed how to set up the Git environment and variables configurations of Git on Ubuntu 20.04 in this article. Git is a very useful software environment that offers many features to all developers and IT users. I hope now you can set up the Git environment on your Ubuntu system, and you can easily change or set its configurations on your system.
]]>The most commonly used Git command is the ‘Git Clone’. This is used to create a copy or clone of an existing target repository in a new directory. The original repository will be stored on the remote machine or the local file system with accessible supported protocols.
In this article, you will explore the use of the Git clone command in detail. A command-line utility of Git that is used to point an existing repository and creates a copy of that targeted directory. Here, we will examine the different Git clone command configuration options and their corresponding examples. We have implemented the Git clone examples on Ubuntu 20.04 Linux system.
Cloning Git Repository by Using Git Clone Command
If you want to make a clone of an existing Git repository, then you can easily do this using the Git clone command. For example, you would like to contribute to a project, then simply use the Git clone command. If you have used VCS systems before, like Subversion, then you will be familiar with commands ‘clone’ and not ‘checkout’. These systems only take the working copy. Here, the Git clone is the whole server repository instead of just a working copy. When you run a Git clone command on your system, every version of the file with the whole project is pulled down by default at your specified location. Let’s suppose if your server disk is corrupted due to any reason, then by using the clones of any client, you can set the server back to its state. You may lose server-side hooks but all file versions would be available there.
Git Clone command Syntax
Example
For example, we want to clone a library called ‘libgit2’. By using the Git link, which is shown below, you can create a copy of that library.
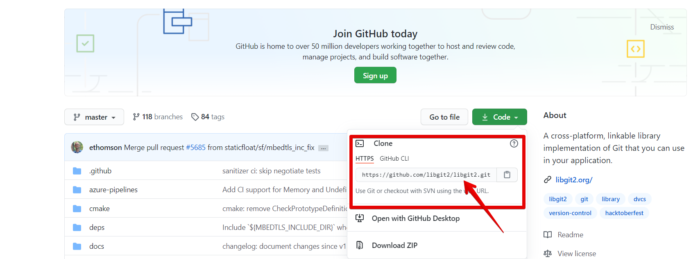
Now, by running the following Git clone command, create a clone of that repository:
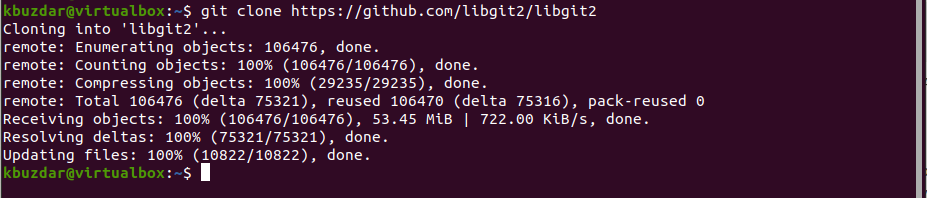
The above command creates a directory named ‘libgit2’ in which the .git directory initializes inside it, all data pull-down of the above repository, then checks out the latest version of the working copy. Now, you can navigate into the directory ‘libgit2’ that was already created. You will find all project files there, ready to be used now.
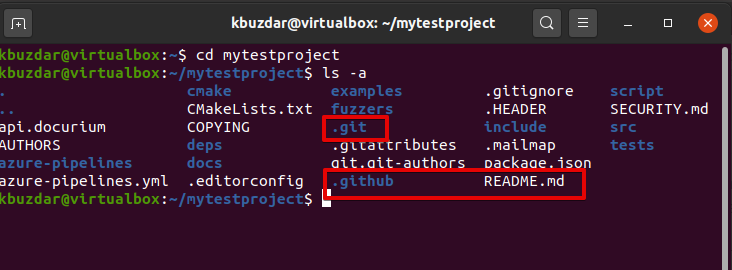
You can clone a repository into a renamed directory instead of libgit2, then you can specify an additional argument as the name of the directory.

The above command will do the same as the previous one, but now the name of the target directory is called ‘mytestproject’. Using the following command you can navigate into the above directory and list the files of the ‘mytestproject’ directory:
$ ls -a
Git Clone options
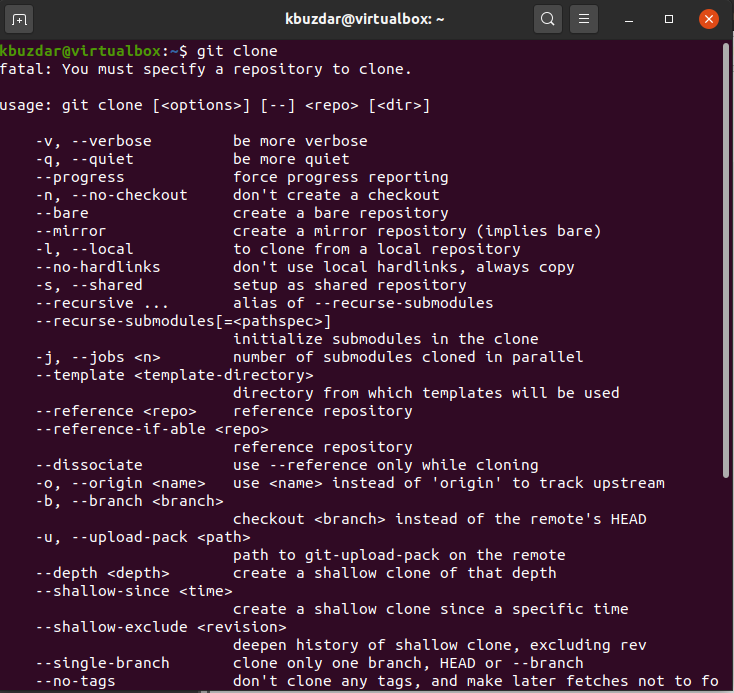
With the Git clone command, you can use many different options according to your requirements. To display all Git clone options, you will type the following command on the terminal:
You will observe the different options that you can easily use with the Git clone command.
Git URLs Protocol Examples
You can find Git URLs protocols in the following syntax :
SSH :
Git :
HTTP :
Conclusion
From the above information, we have discussed how to use the Git clone command on Ubuntu 20.04. Furthermore, we have seen how to clone a target repository. Git supports different URLs protocols including those we have mentioned in this article. For more information about the Git clone command, you can get help from the main page of the Git clone command.
]]>Gitlab is the code hosting platform like Github and Bitbucket. These three are the most popular solutions for hosting your own Git repositories. They have various features that allow individuals and teams to share code remotely with others. Gitlab is an open-source web-based hosting tool. It has a friendly web interface that’s simple and intuitive for just about every user if you want to build your server for code hosting so that you can share and host code and install and set up your server.
In this article, we will show you how to install and set up the GitLab server on Ubuntu 20.04 LTS system using the command line.
You can install gitlab using the following two different methods:
Method 1: Installation of Gitlab by using a simple script
Before starting the installation process, you must ensure that all system packages are updated. To do that, you need to open the terminal application. Therefore, access the terminal by clicking on Activities and type terminal in the application launcher. Or you can also access the terminal window using keyboard shortcut keys Ctrl + Alt + t. Issue the following command:
Now, using the following command, you will install the gitlab package dependencies.

Most of the developers prefer to add a gitlab repository using the simple script. Once you install the prerequisites dependencies, now for convenience add the gitlab repository to run the below-mentioned script on the system and download the gitlab using the following command:
| sudo bash
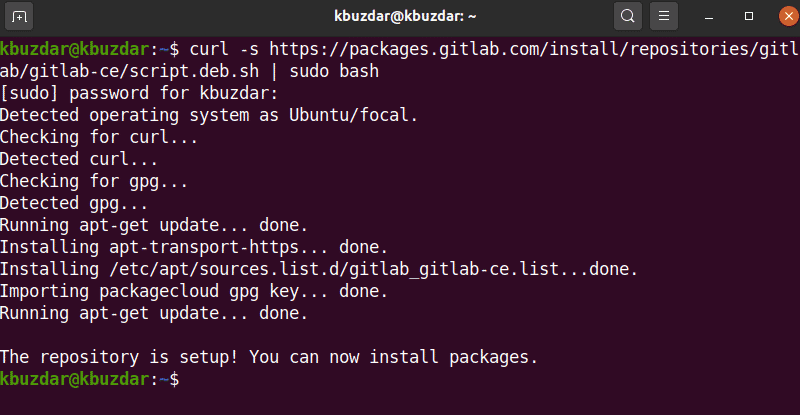
After successfully running the script, you can install the gitlab-ce package on Ubuntu 20.04 by using the following command:
Method 2: Install Gitlab to download from the internet
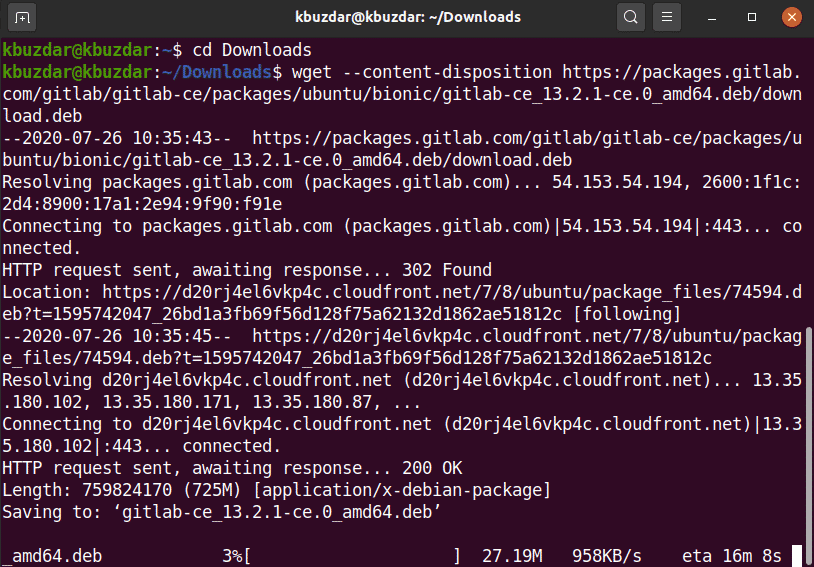
In case of any server problem or Ubuntu release official support issue related to the gitlab package then, you can download the gitlab package from another network server. You can download the gitlab package from this given URL https://packages.gitlab.com/gitlab/gitlab-ce. When you completely download the package, copy or move it to your server and then install the gitlab using the following commands:
Run the following wget command to download gitlab package:
bionic/gitlab-ce_13.2.1-ce.0_amd64.deb/download.deb
The following output will display on your system, and it will take time to download the gitlab package.
Once the download is complete, list the files using ls command.

Now, you will install the downloaded (.deb) package on Ubuntu 20.04 using the following command:

In a while, you will see the following output on your terminal window.
Once you installed the gitlab package, you can execute the required configuration utility. This file provides automatic configurations, and you can modify it according to your need. Run the following edit of the gitlab configuration file.
Now, edit the configuration file to change hostname using external_url variable so that, you can access them from other remote machine using the specified hostname and other parameters:
Run the following command to reconfigure the services of gitlab:

The above command will reconfigure all gitlab service. This process may take time to complete. So, be patient and wait for the completion of reconfiguration gitlab services.
Now, using the following command, you will start the gitlab services on your system.

The following output you will see on the terminal that will notify you all gitlab services started successfully.
You can also check the status of services either running on your system or not by executing the following command on the terminal.

Now, open the browser and enter localhost to access the GitLab web portal that will ask you to set the username and password of root.
The following window will display in your browser:
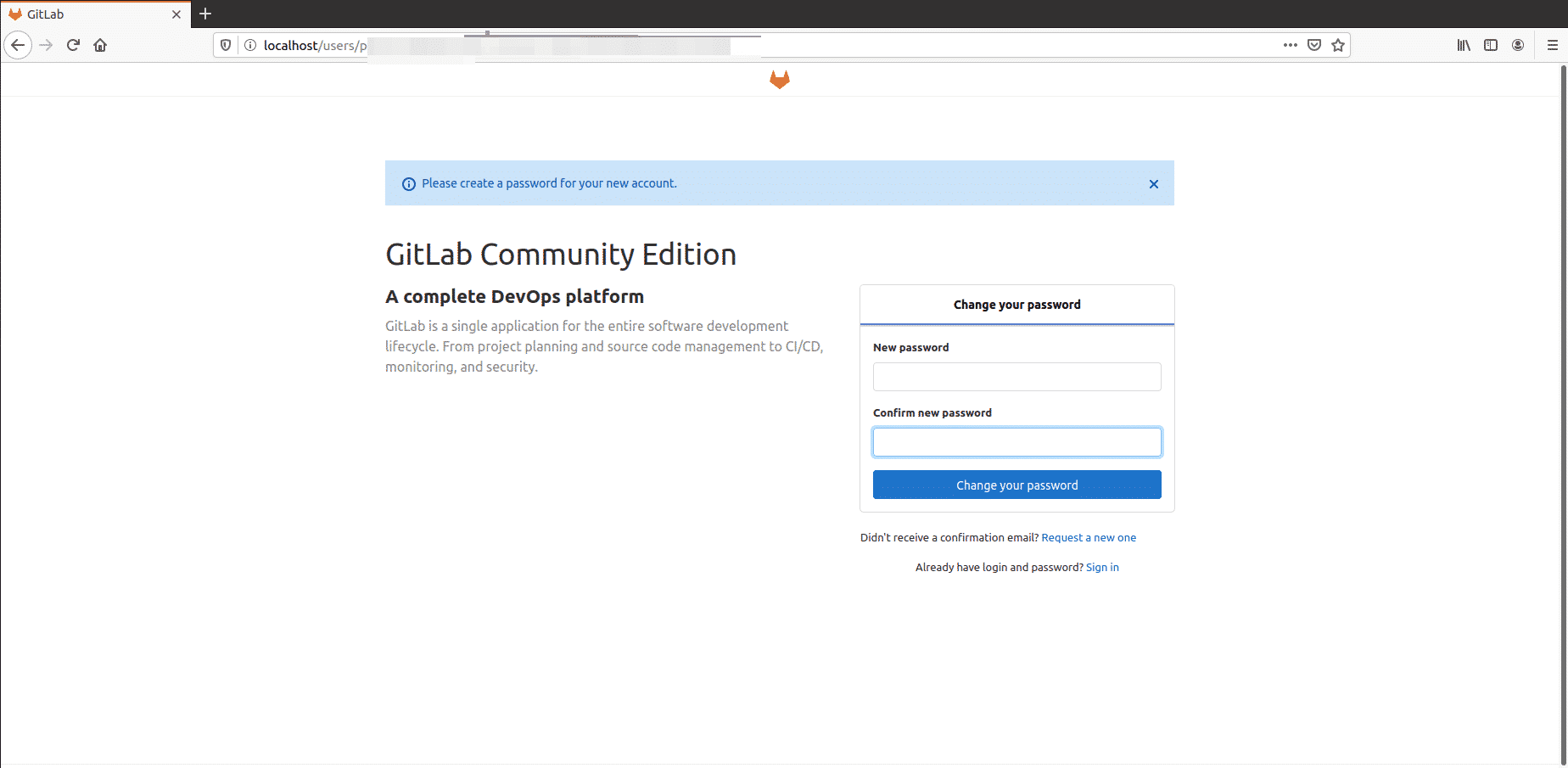
Enter the new root password. After verifying then, click the ‘Change your password’ option.
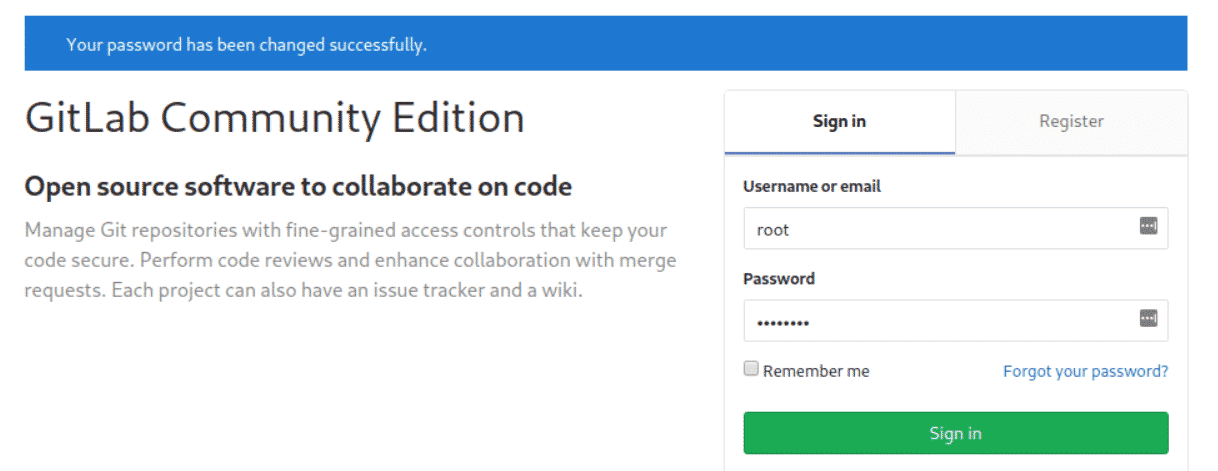
Now, login with the username as root and then provide the password. You will see the following gitlab dashboard screen on your system.

Conclusion
In this article, you have studied how to install and set up gitlab on Ubuntu 20.04 LTS system. Moreover, you also explored two different methods for the installation of gitlab. One is using the simple script method, and the other one is to download the gitlab deb file from the internet. I hope you will like this article.
]]>The standard Markdown
Markdown is a standard developed by John Gruber. The main goal with Markdown is to make the file possible to read even in pure text. If you want to look in a text-only editor, you should have an easy time reading it. This is very helpful for users of vim and similar. Note, and remember that this is a standard for changing text files. It is not replacing HTML. Instead, you use it to create HTML where it is useful. In the case of GitHub, they will format the Readme file on the site. As long as you follow the standard, you can feel certain it will look good.
Since GitHub has added just a few extensions, you should start by using a Markdown cheatsheet and go from there. Here is a list of the most common ones.
| Markdown | Extensions | Result |
| # (1 per level) | Headings | |
| * | Italics | |
| ** | Bold | |
| > | Blockquote | |
| 1. (etc.) | Ordered List | |
| – | Unordered list | |
| `code` | Your Code | |
| “` | Md-ext | Start and end a code block |
| — | Horizontal Rule | |
| [Description](https://www.example.com) | A name in square and URL in regular brackets | |
|  | Same, link to an image | |
| [1] | Md-ext | A footnote |
The lists can be nested by indenting any items you want to have nested.
Other extensions to regular Markdown, you have the code blocks extensions above. They are not always supported by services.
| Markdown | Extensions | Result |
| ### Heading {#custom-id} | Md-ext | A heading that you can address by its ID |
| term: definition | Md-ext | A list of terms with definitions |
| ~Mistaken Text~ | Md-ext | Strikethrough text |
| – [x] Task to do | Md-ext | A task list you can tick off |
The table is very simple, but you need several rows to show it: Table:
| ----------- | ---------- |
| Mats | 100 |
GitHub Extensions.
GitHub has added a few extensions to make it simpler to handle links to other people and projects. Some of those are the tables mentioned earlier. The one that will help you the most is the auto-link extension. It creates a link on its own when you use it on GitHub.
Others are tables and Task list items. These are convenient for keeping track of your tasks in projects. The last one to mention is the Disallowed Raw HTML extension. With the help of this extension, some tags are filtered when rendering for HTML. These tags can cause strange effects when rendering to GitHub.
Ways to explore GitHub Markdown
If you find it confusing, you can also go to the GitHub page and use the built-in editor. When you use it, it will auto-complete some functions. This only works for issues, but you can use it to figure out some things, the emojis comes out as a list when you type a colon (:).
You can also find a project on GitHub that has great looking README file and clone it to your local drive. From there, you can explore the file using any editor you wish. For the big editors, Emacs and Vim, there is support for markdown through extensions.
If you are using vim, you can put in a syntax highlighting extension from GitHub, vim-markdown. This extension shows you that you have done the code correctly. To help you see how it looks when done, you can also get the live mark extension. With this, you can have a web server running, showing the result live as you type.
With Emacs, you have impatient-mode, live down-mode and Realtime-preview. They all show your resulting page in a browser while you type. The first requires less libraries than the latter but needs an extra code-snippet to run.
Conclusion
Even though markdown is a small and deliberately simple specification, it can be a little confusing to get started with. The best way to learn is to use a cheat sheet and write your Markdown document. You can update your README.md on GitHub, and you can get a lot of support from your editors’ built-in functions. As a side note, GitHub also supports emojis which you can add to your document. You can use the cheat sheet to find which ones they are.
Download Markdown-CheatSheetHere ]]>

Installing Git from Ubuntu Software APT
It is a recommended method to install the Git system from the Ubuntu Software repository.
Step 1:
As always, first, update and upgrade your APT.


Step 2:
The Git utility package is, by default, included in ubuntu’s software repositories that can be installed via APT. Just enter the following command to download and install Git.

Git requires root/sudo privileges to be installed so, enter the password to continue the installation.
Step 3:
When Git gets installed, you can check its verification with the following command

Configuring Git
You can configure Git through the terminal/command-line window. It requires a global username that acts as a commit name and an email address.
Step 1:
Enter the following command to set a username, replace the content inside the “Younis said” with your name.

Step 2:
Enter the following command to set a global user email, replace the content inside the “[email protected]” with your user email.

Step 3:
Lastly, check for the changes you just made by using the following command. It lists out the changes made to the Git configuration file.

Step 4 (optional):
You can also edit these settings any time for that you have to change it via “git config command” in the terminal window.

Conclusion:
Git is very easy to install on Ubuntu, just needs 4 commands to install and configure it. You just need an APT command to download and install the stable version from the Ubuntu repository
]]>Tested on: Ubuntu 18.04 LTS and Ubuntu 20.04 LTS.
Setting Up Static IP Address:
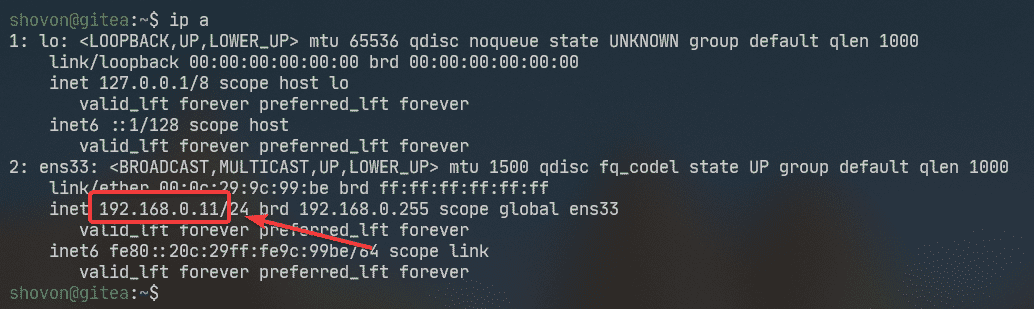
Before you get started, you should set up a static IP address on your Ubuntu 20.04 LTS machine. If you need any assistance on that, check my article Setting Up Static IP Address on Ubuntu 20.04 LTS.
I have set up a static IP address 192.168.0.11 on my Ubuntu machine where I am installing Gitea. So, make sure to replace it with yours from now on.
Updating APT Package Repository Cache:
Now, update the APT package repository cache with the following command:
Installing wget:
To download Gitea binary from the command line, you need either wget or curl. In this article, I will use wget.
You can install wget with the following command:
Installing Git:
You also need to have git installed on your computer for Gitea to work.
You can install git with the following command:

Installing and Configuring MySQL for Gitea:
Gitea can work with MySQL, PostgreSQL, SQLite3 and MSSQL databases. In this article, I will configure Gitea to use the MySQL database.
You can install MySQL on your Ubuntu 20.04 LTS machine with the following command:
![]()
MySQL should be installed.
Now, login to the MySQL console as root with the following command:
![]()
Now, type in your MySQL root password and press <Enter>.
By default, no password is set for the root user. So, if you’re following along, just press <Enter>.

You should be logged in to the MySQL console.

Now, create a new MySQL user gitea with the password secret with the following SQL statement:

Now, create a gitea database for Gitea with the following SQL statement:

Now, allow the gitea user full access to the gitea database with the following SQL statement:

For the changes to take effect, run the following SQL statement:

Now, exit out of the MySQL shell as follows:

Installing Gitea:
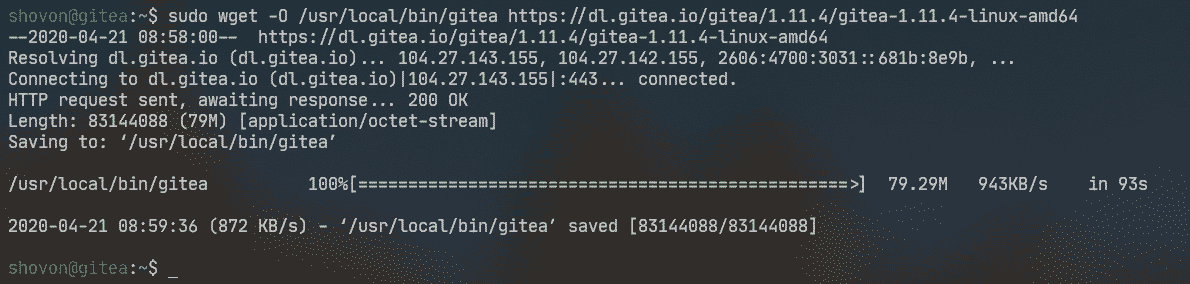
Now, download Gitea binary from the official website of Gitea with the following command:
gitea-1.11.4-linux-amd64
![]()
Gitea binary is being downloaded.

At this point, Gitea should be downloaded.
Now, give execute permission to the Gitea binary /usr/local/bin/gitea with the following command:
![]()
Now, you should be able to access Gitea as shown in the screenshot below.

Now, create a new user git for Gitea as follows:
--group --disabled-password --home /home/git git
![]()
Here, the git repositories will be stored in the HOME directory of the git user /home/git.
The user git should be created.

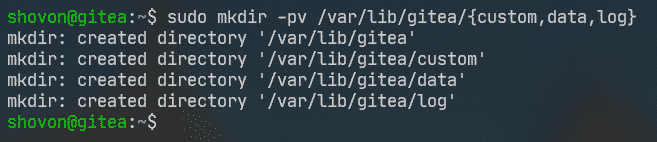
Now, create all the required directories for Gitea as follows:
Now, change the user and group of the directories you have just created to git as follows:

Now, set correct permissions to the /var/lib/gitea/ directory as follows:

Now, create a Gitea configuration directory /etc/gitea/ as follows:

Now, change the user to root and group to git of the Gitea configuration directory /etc/gitea/ as follows:

Now, set correct permissions to the /etc/gitea/ directory as follows:

Configuring Gitea Service:
Now, you have to create a systemd service file gitea.service for Gitea in the /etc/systemd/system/ directory.
To create a service file for Gitea, run the following command:
![]()
Now, type in the following lines in the gitea.service file.
Description=Gitea (Git with a cup of tea)
After=syslog.target
After=network.target
Requires=mysql.service
[Service]
LimitMEMLOCK=infinity
LimitNOFILE=65535
RestartSec=2s
Type=simple
User=git
Group=git
WorkingDirectory=/var/lib/gitea/
ExecStart=/usr/local/bin/gitea web --config /etc/gitea/app.ini
Restart=always
Environment=USER=git HOME=/home/git GITEA_WORK_DIR=/var/lib/gitea
CapabilityBoundingSet=CAP_NET_BIND_SERVICE
AmbientCapabilities=CAP_NET_BIND_SERVICE
[Install]
WantedBy=multi-user.target
Once you’re done, save the gitea.service file by pressing <Ctrl> + X followed by Y and <Enter>.

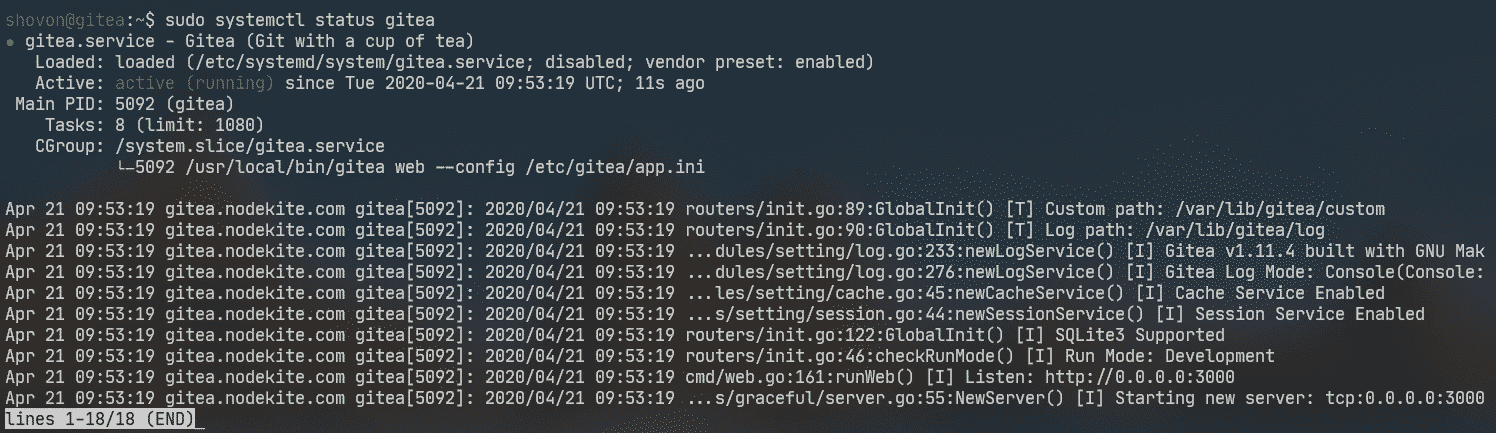
Now, start the gitea service with the following command:
![]()
As you can see, the gitea service is running.
Now, add gitea service to the system startup of your Ubuntu 20.04 LTS machine. So, it will automatically start on boot.

Initial Configuration of Gitea:
Now, you have to configure Gitea from the web browser.
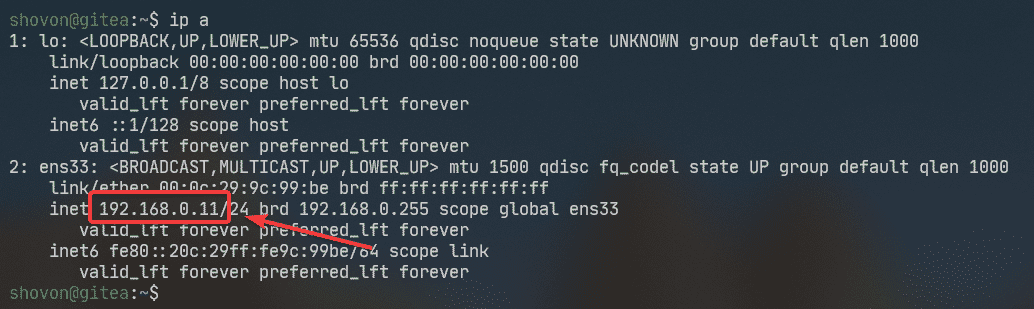
First, find the IP address of your Ubuntu 20.04 LTS machine as follows:
In my case, the IP address is 192.168.0.11. It will be different for you. So, replace it with yours from now on.
Now, open a web browser and visit http://192.168.0.11:3000. You should see the following page.
NOTE: Gitea runs on port 3000 by default.

Now, click on any of the Register or Sign In link.

Gitea initial configuration page should be displayed. You have to configure Gitea from here.

Type in your MySQL database information in the Database Settings section. Make sure that the database settings are correct before moving on.
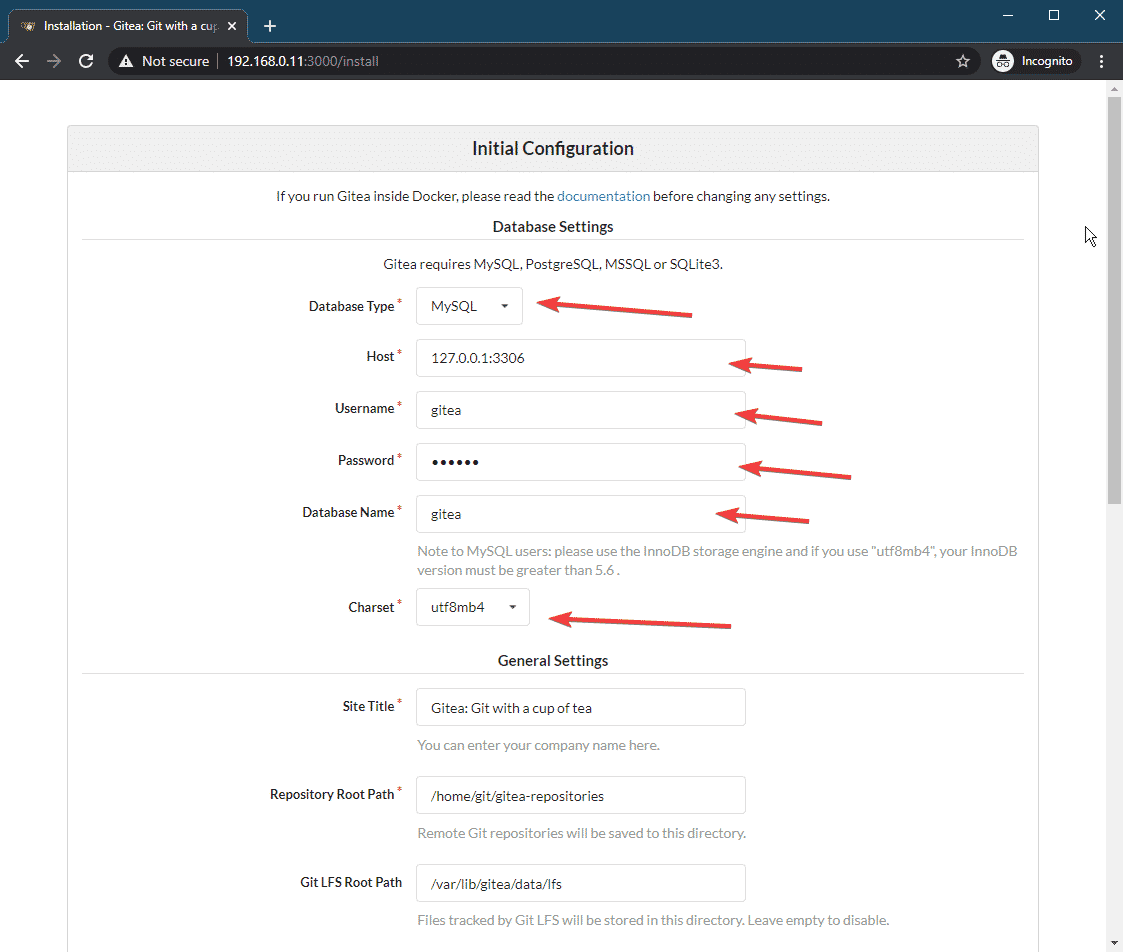
In the General Settings section, you can configure many things of Gitea.
You can change the default site title (Site Title), the directory where git repositories will be stored (Repository Root Path), the Git LFS Root Path, Gitea run user (Run As Username), Gitea Log Path, Gitea port (Gitea HTTP Listen Port), HTTP/HTTPS clone URL (Gitea Base URL), SSH clone URL (SSH Server Domain), and SSH clone port (SSH Server Port).
You can pretty much leave everything the default if you want. But, make sure to change the SSH Server Domain and Gitea Base URL to a Fully Qualified Domain Name (FQDN) or the IP address of your Ubuntu machine. Also, adjust the SSH Server Port if you have changed the SSH port on your Ubuntu machine.
I have changed the SSH Server Domain to 192.168.0.11, Gitea HTTP Listen Port to 80 and the Gitea Base URL to http://192.168.0.11/.
NOTE: If you set Gitea HTTP Listen Port to 80, then you don’t have to include port 80 in the Git Base URL section. You can just set http://192.168.0.11/ as your Git Base URL.
But if you use any port like 8080, then you should include it in the Git Base URL. i.e. http://192.168.0.11:8080/
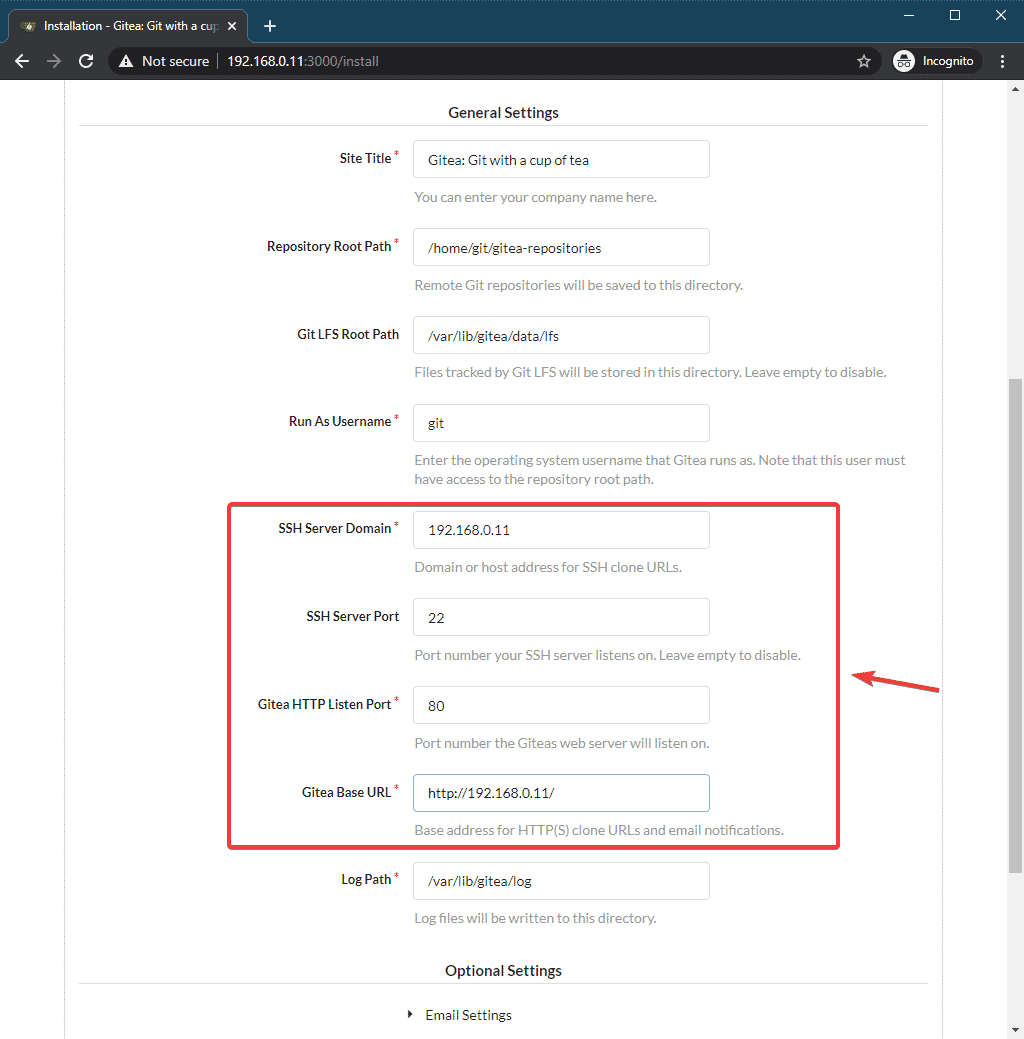
There are also optional Email Settings (if you want to send email from your Gitea server), Server and Third-Party Service Settings (for Third-part service integration with Gitea) and Administrator Account Settings (for creating a Gitea administrator account). Just click on the arrow to expand these if you want.
I am not going to configure these in this article.

Gitea Email Settings.
Gitea Server and Third-Party Service Settings.

Gitea Administrator Account Settings.
Once you’re done setting up Gitea, click on Install Gitea.

Gitea should be installed and your browser should redirect you to the Gitea homepage.
If you have changed the Gitea HTTP port (as I did), then you may see the following error message. It’s very easy to fix.

To fix that, all you have to do is to restart the gitea service with the following command:
![]()
Once you restart the gitea service, you should be able to access Gitea from the web browser as usual.
Using Gitea:
In this section, I am going to show you how to use Gitea.
First, click on Register.
Now, type in your personal information and click on Register Account to create a new Gitea account.
A new Gitea account should be created and you should be logged in to your account.
Now, click on the + button to create a new Git repository.
Type in a Repository Name and other repository information. Then, click on Create Repository.

A new Git repository (test in my case) should be created as you can see in the screenshot below.
Gitea should also instruct you on how you use this repository.
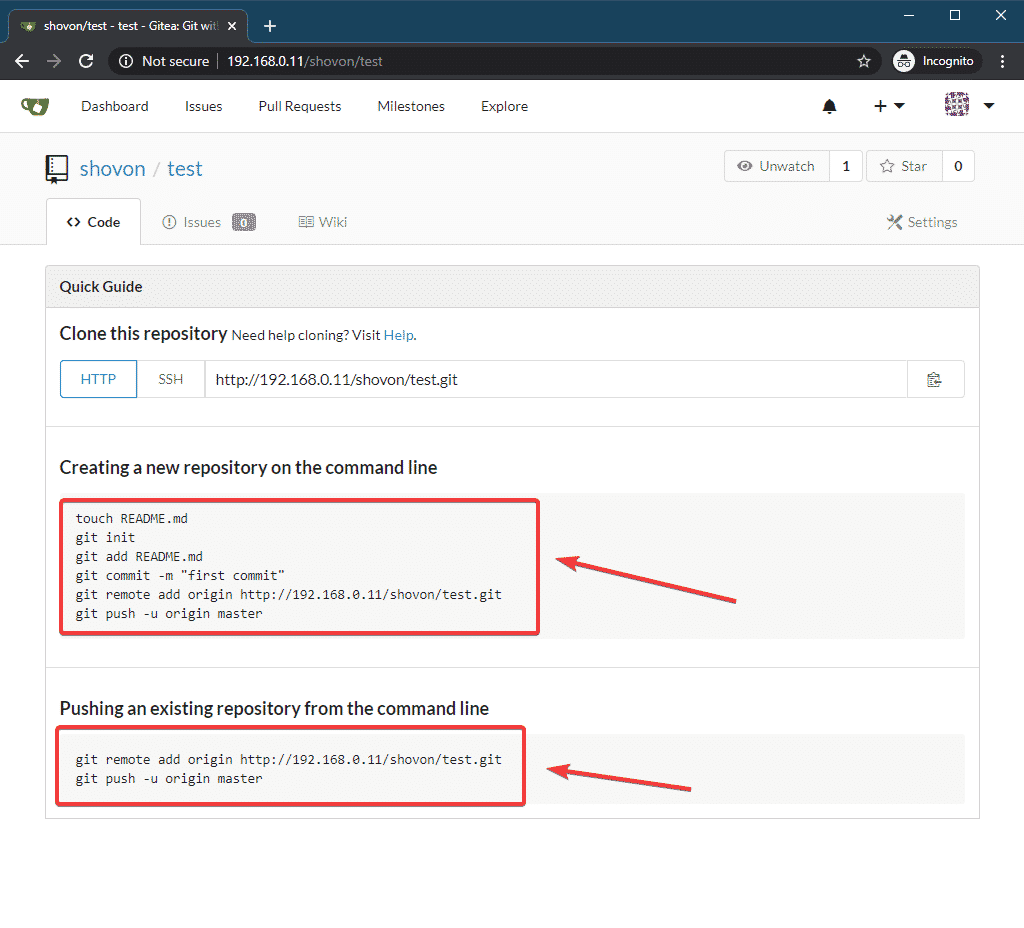
Now, create a directory test/ on your computer and navigate to that directory as follows:
$ cd test/

Now, create a new Git repository in the test/ directory as follows:

Now, create a simple README.md file as follows:

Now, make a commit as follows:
$ git commit -m 'initial commit'
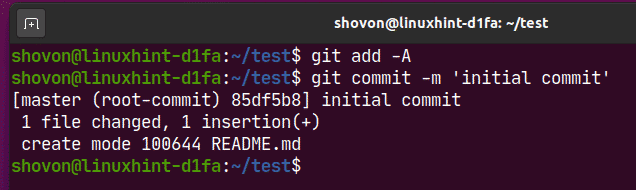
Now, add the Gitea repository (test in my case) you have just created as a remote repository as follows:

Now, push the changes to the remote Gitea repository as follows:

Now, type in your Gitea username and press <Enter>.

Now, type in your Gitea password and press <Enter>.

Your git repository should be uploaded to your Gitea server.
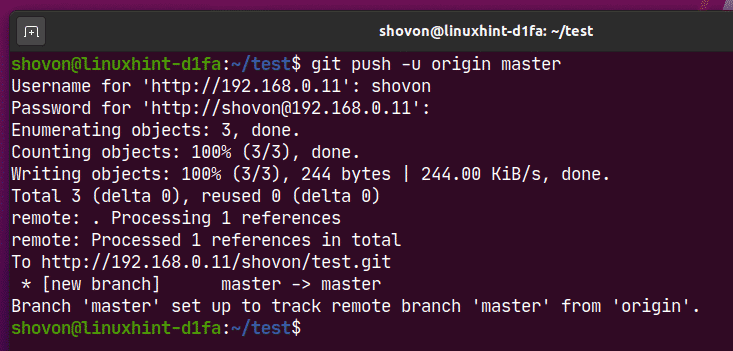
As you can see, the changes are applied to the test Git repository on my Gitea server.

So, that’s how you install and use Gitea on Ubuntu 20.04 LTS. Thanks for reading this article.
]]>Installing Git and Apache HTTP Server:
First, update the CentOS 8 package repository cache with the following command:
Now, install Git, Apache HTTP server and Apache tools with the following command:

Now, press Y and then press <Enter> to confirm the installation.
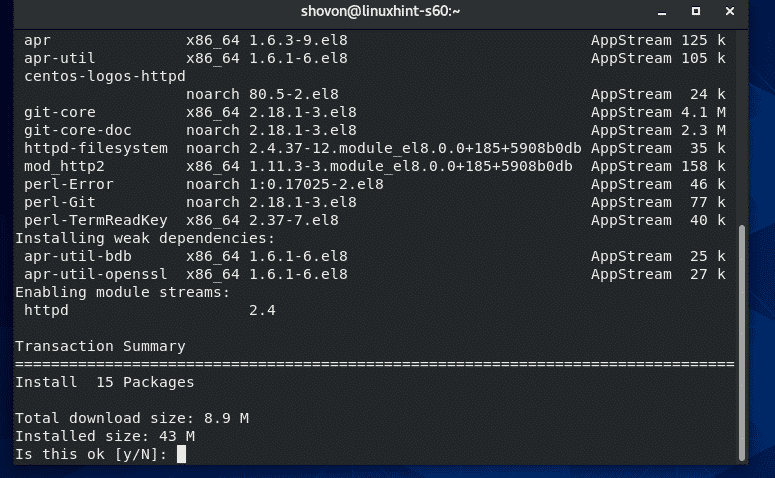
Git, Apache and required Apache tools should be installed.
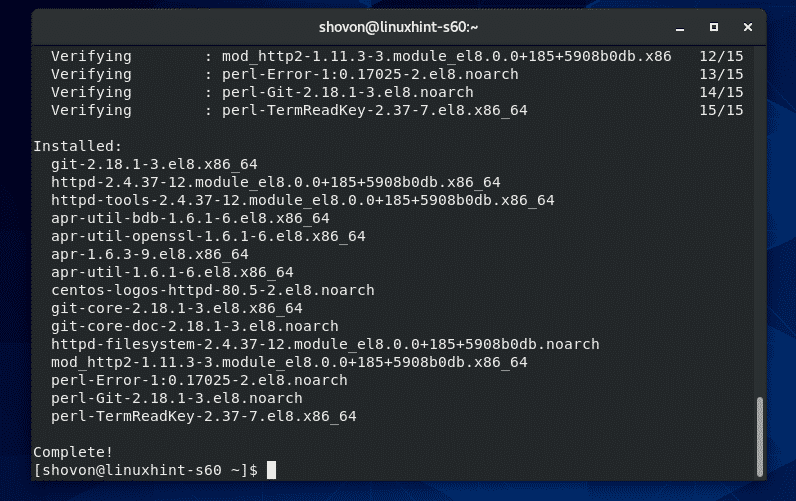
Configuring Apache HTTP Server:
In this section, I am going to show you how to configure Apache server for accessing Git repositories over HTTP protocol.
First, create a new configuration file /etc/httpd/conf.d/git.conf with the following command:

Now, add the following lines to the configuration file /etc/httpd/conf.d/git.conf:
SetEnv GIT_PROJECT_ROOT /var/www/git
SetEnv GIT_HTTP_EXPORT_ALL
DocumentRoot /var/www/git
ScriptAlias / /usr/libexec/git-core/git-http-backend/
<Directory "/usr/libexec/git-core">
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
AllowOverride None
Require all granted
</Directory>
<Directory "/var/www/git">
Dav On
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
</Directory>
</VirtualHost>
The final configuration file should look as follows. Now, save the configuration file.
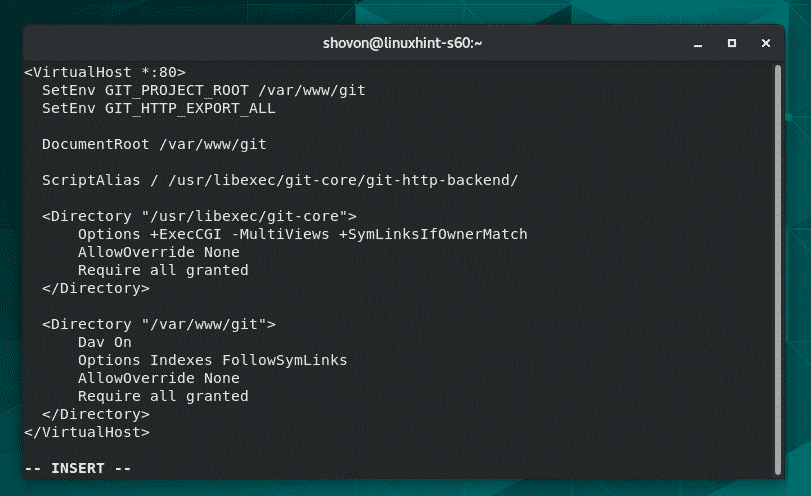
Now, create the GIT_PROJECT_ROOT directory /var/www/git with the following command:

Now, configure SELinux for the /var/www/git directory with the following command:
"/var/www/git(/.*)?"

For the SELinux changes to take effect, run the following command:

Now, restart the Apache HTTP server service with the following command:

Also, add the Apache HTTP server service to the CentOS 8 system startup with the following command:

Now, allow the HTTP port (80) through the filewall with the following command:

For the changes to take effect, reload the firewall as follows:
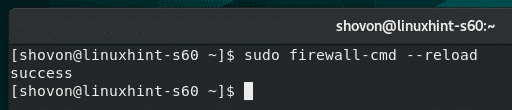
Writing a Script for Creating HTTP Accessible Git Repositories Easier:
To make creating HTTP accessible Git repositories easier, I’ve written a simple shell script which you can use to save a lot of your valuable time.
If you want to use my script, create a new file in the path /usr/sbin/git-crate-repo with the following command:

Then type in the following lines of codes in the newly created file /usr/sbin/git-crate-repo.
GIT_DIR="/var/www/git"
REPO_NAME=$1
mkdir -p "${GIT_DIR}/${REPO_NAME}.git"
cd "${GIT_DIR}/${REPO_NAME}.git"
git init --bare &> /dev/null
touch git-daemon-export-ok
cp hooks/post-update.sample hooks/post-update
git config http.receivepack true
git config http.uploadpack true
git update-server-info
chown -Rf apache:apache "${GIT_DIR}/${REPO_NAME}.git"
echo "Git repository '${REPO_NAME}' created in ${GIT_DIR}/${REPO_NAME}.git"
This is what the final shell script looks like. Once you’re done, save the file.
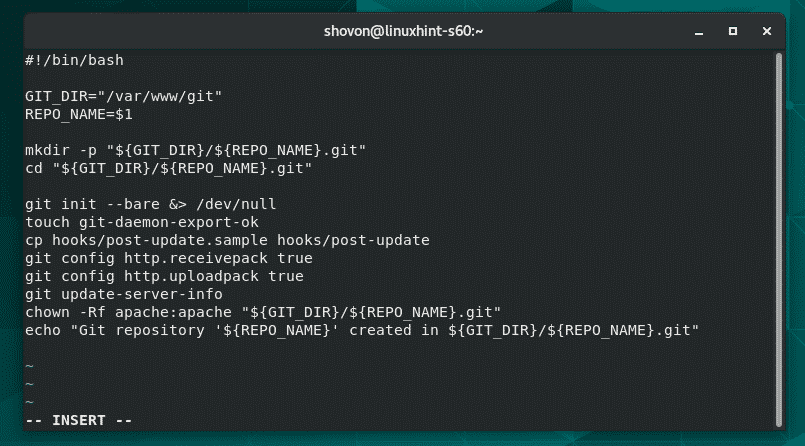
Now, add executable permission to the shell script /usr/sbin/git-create-repo with the following command:

Create HTTP Accessible Git Repositories:
Now, you can create a new HTTP accessible Git repository (let’s call it test) with the following command:

A new HTTP accessible Git repository test should be crated.
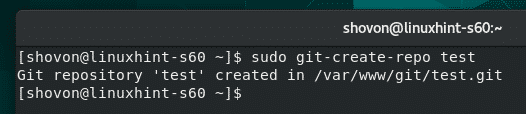
Accessing the Git Repositories from the Git server:
To access the Git repositories that you’ve created on your CentOS 8 Git server, you need is that IP address of the CentOS 8 Git server and the Git repository name.
The Git server administrator can find the IP address of the Git server with the following command:
In my case, the IP address is 192.168.20.129. It will be different for you. So, make sure to replace it with yours from now on.
Once the Git server administrator finds the IP address, he/she can send it to the users/developers who will be using Git repositories hosted on the Git server. Then the users/developers can access their desired Git repositories.
For example, if bob wants to clone the Git repository test from the Git server, he may do so as follows:

The Git repository test should be cloned from the Git server.

A new directory test/ should be created in the current working directory of bob.
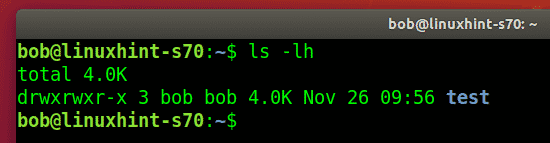
Now, bob can navigate to the test/ directory as follows:

Now, bob creates a new file message.txt in the Git repository.

Bob commits the changes.

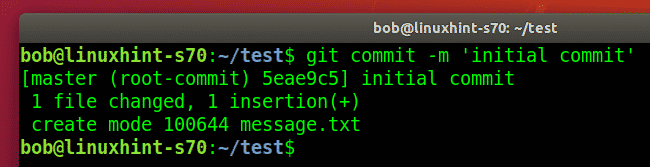
Bob confirms whether the changes were committed to the repository.
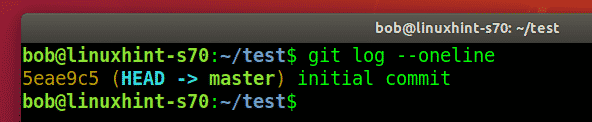
Now, bob uploads the changes to the Git server.
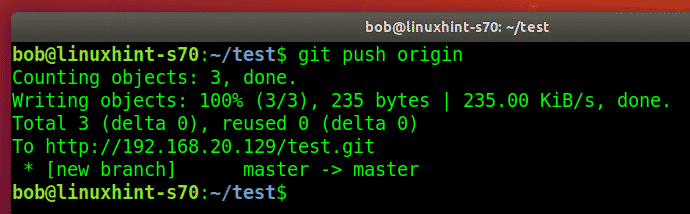
Another developer (let’s say shovon) who wants to contribute to the test Git repository can also clone the test repository from the Git server.
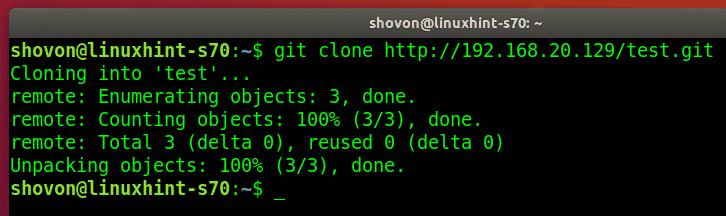
Shovon navigates to the test/ directory.

Shovon finds the commit that bob made.

Now, shovon changes the message.txt file.

Commits the changes.


Shovon confirms whether the changes were committed to the repository.
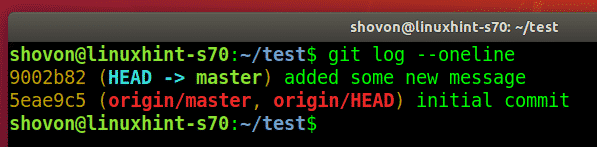
Shovon uploads the changes to the Git server.
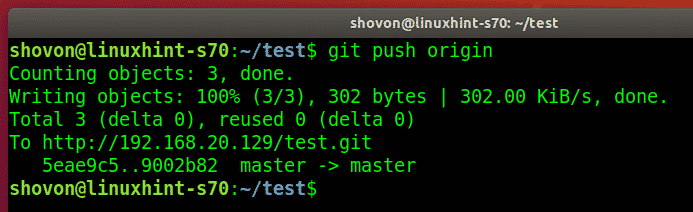
Now, bob pulls the changes from the Git server.
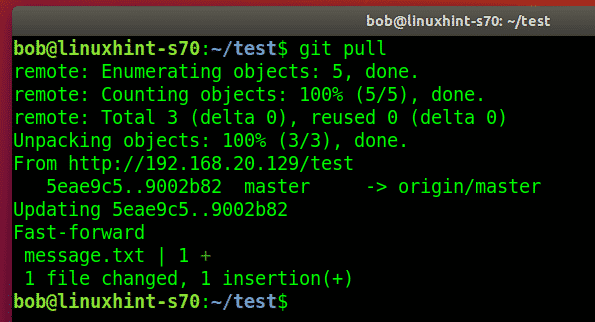
Bob finds the new commit.
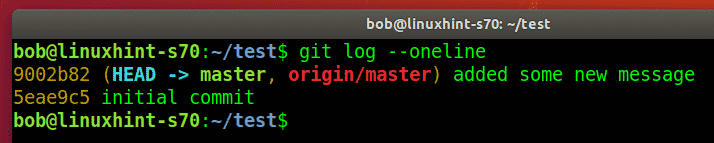
Bob finds the changes that Shovon made to the message.txt file.
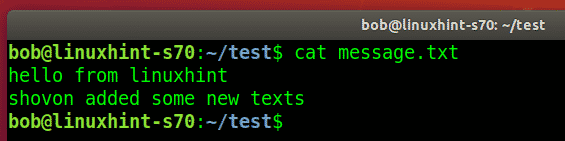
This is how you can use Git repositories from the Git HTTP server.
Adding User Authentication to Git Server:
If you want to add user authentication to server wide Git repositories or specific Git repositories, then check the article Configure Git Server with HTTP on Ubuntu.
So, that’s how you configure Git Smart HTTP Server on CentOS 8 and use Git repositories from the Git server. Thanks for reading this article.
]]>Configuring SSH for Git Server:
In order to set up a Git server to work over SSH, you have to make sure SSH is installed and is running correctly.
First, update the CentOS 8 package repository cache with the following command:
Now, install SSH server with the following command:

It should be installed. In my case, it was already installed.
Now, check whether the SSH service is running with the following command:

The SSH service should be running as shown in the screenshot below.
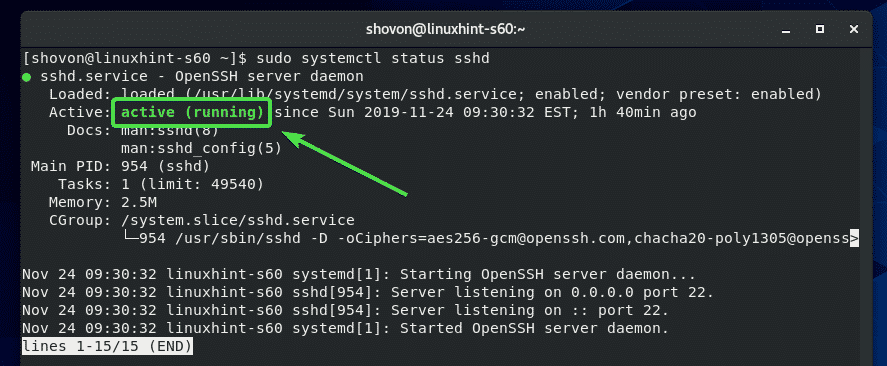
If for some reason, the SSH service is not running for you, you can start it with the following command:
Now, allow access to the SSH ports through the firewall with the following command:

Finally, run the following command for the firewall configuration changes to take effect:
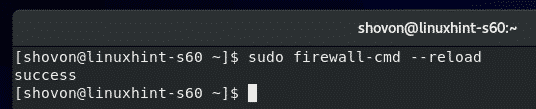
Installing Git:
Now, you can install Git with the following command:

To confirm the installation, press Y and then press <Enter>.
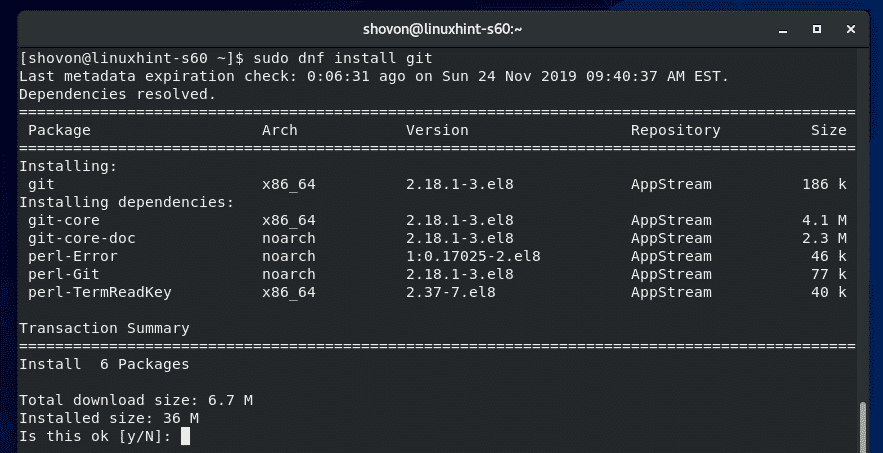
Git should be installed.
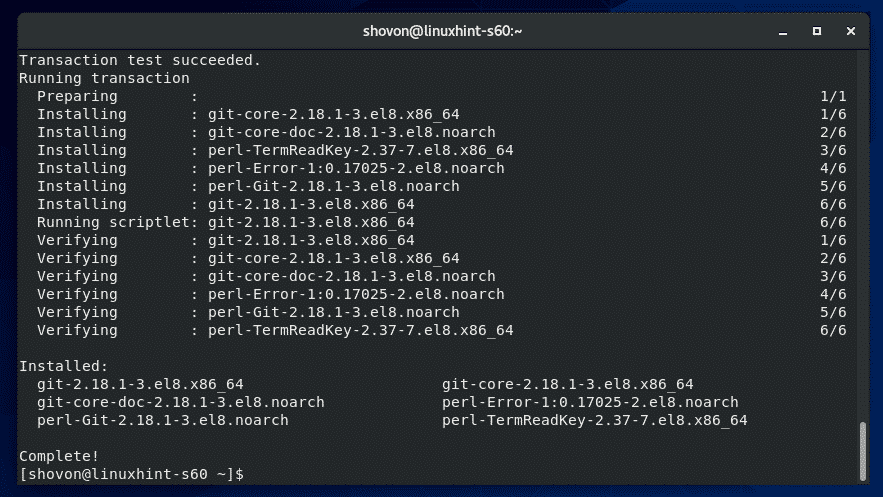
Creating a Dedicated User for Hosting Git Repositories:
Now, create a dedicated user git with the following command:

Now, login as the git user with the following command:

Now, create a new directory ~/.ssh as follows:

Only the git user should have read, write and execute permission to the ~/.ssh directory.
To do that, run the following command:

As you can see, now only the user git has read, write and execute permission to the directory.
Now, create a new file ~/.ssh/authorized_keys as follows:

Only the git user should have read and write permission to the ~/.ssh/authorized_keys file.
To do that, run the following command:

As you can see, now only the user git has read, and write permission to the ~/.ssh/authorized_keys file.

Adding Client public Key to the Git Server:
To access the git repositories on the Git server, the users of the repository must add their public keys to the Git server.
The users can generate their SSH keys with the following command:

Press <Enter>.

Press <Enter>.

Press <Enter>.
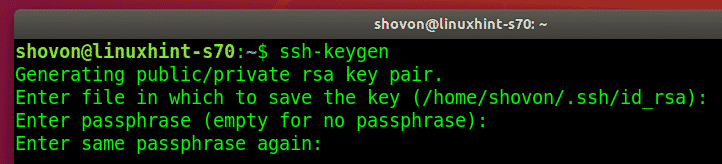
The SSH key should be generated.
Now, the users can find their public key in the ~/.ssh/id_rsa.pub file.
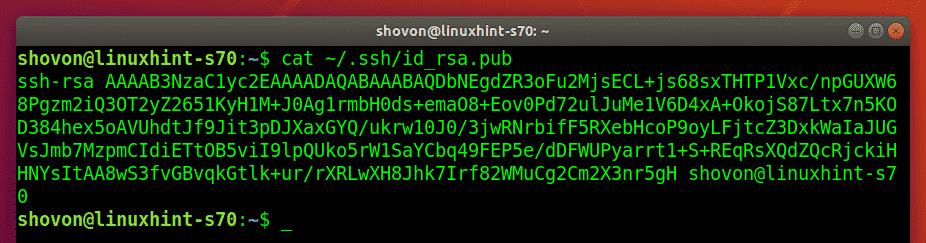
Now, the users should send their public keys to the Git server administrator and the server administrator can add these keys to the Git server.
Let’s say, the server administrator has uploaded the public key file to the Git server. The file is in the path /tmp/shovon-key.pub.
Now, the server administrator can add the contents of the public key to the ~/.ssh/authorized_keys file as follows:

The public key should be appended to the end of the ~/.ssh/authorized_keys file.
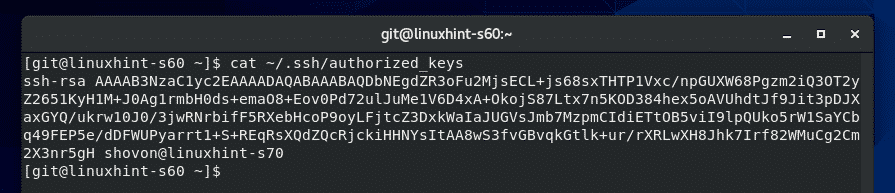
Creating an Empty Git Repository on the Git Server:
In the home directory of the git user, we will keep all our Git repositories that authorized people can access.
To create an empty Git repository test on the Git server, run the following command:
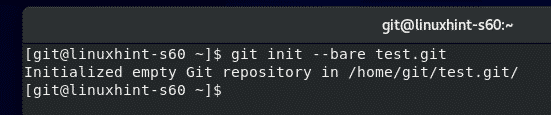
If an authorized user wants to access the Git repository from the Git server, all he needs is the name of the Git repository and the IP address of the Git server.
To find the IP address of the Git server, run the following command:
The IP address in my case is 192.168.20.129. It will be different for you. So, make sure to replace it from now on.
A new directory test.git should be created on the Git server.
Accessing Git Repositories from Git Server:
Now, an authorized user can access the test Git repository we’ve created earlier as follows:

If the user is connecting to the Git server for the first time, he/she will have to type in yes and press <Enter>.

The Git repository test should be cloned.
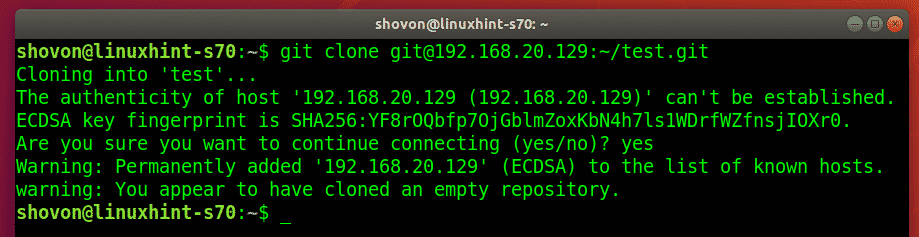
A new directory test/ should be created in the users current working directory.
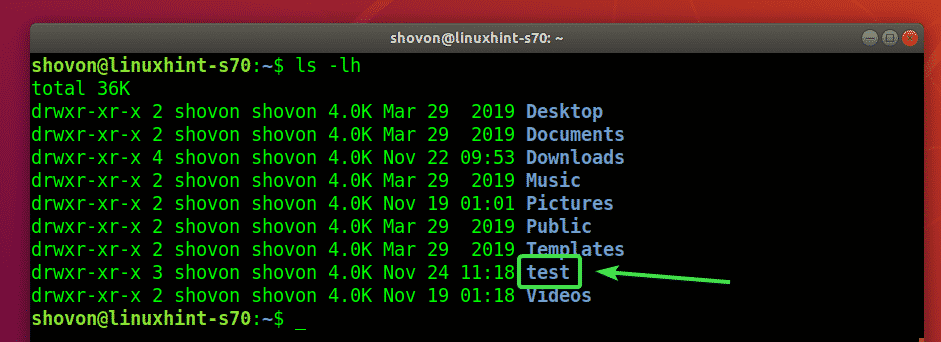
The user will have to navigate to the test/ directory as follows:

Let’s say, the user created a new file.

Committed the changes.

$ git commit -m ‘initial commit’
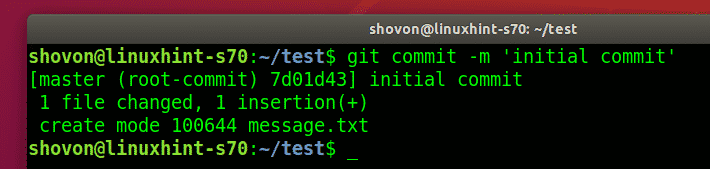

Then, the user pushed the changes to the Git server.
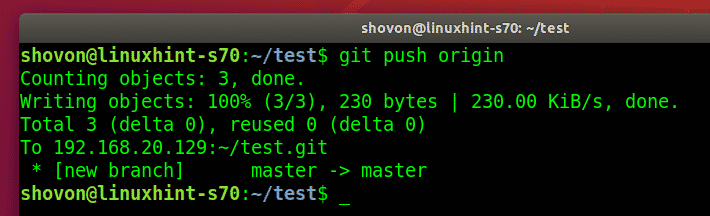
Adding Another Team Member:
If another user wants to access the Git repository test, he will have to generate an SSH key and send the public key to the Git server administrator. Once the Git server administrator adds his/her public key to the ~/.ssh/authorized_keys file, the user can access the Git repositories on the server as well.
Let’s say, bob also wants to work on the test Git repository.
He clones the test Git repository on his computer.

bob types in yes and presses <Enter>.
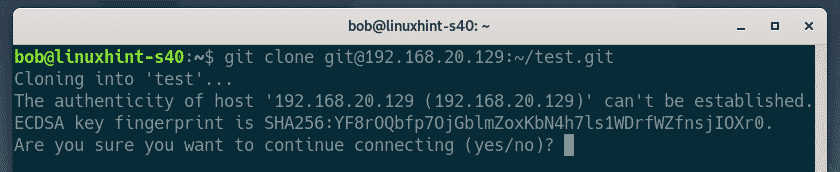
The test Git repository is cloned.
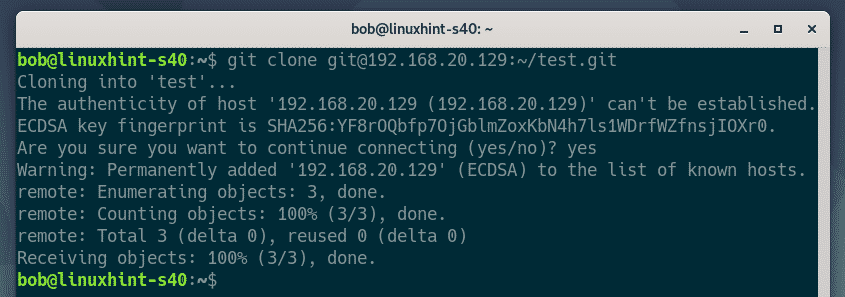
bob navigates to the test/ directory.

Finds the commit that the person working on this Git repository made.

He makes some changes to the project.

Commits the changes.

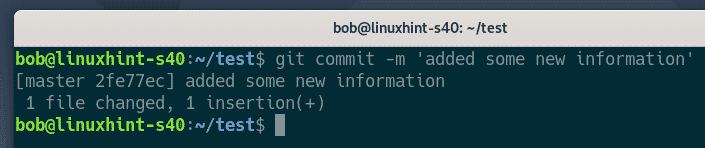
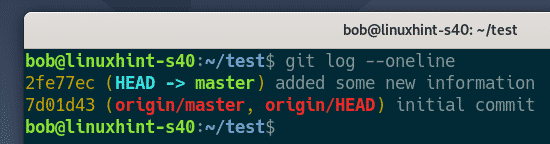
bob pushes the changes to the Git server.

Now, the other user shovon pulls the changes (if any) to Git repository from the Git server.
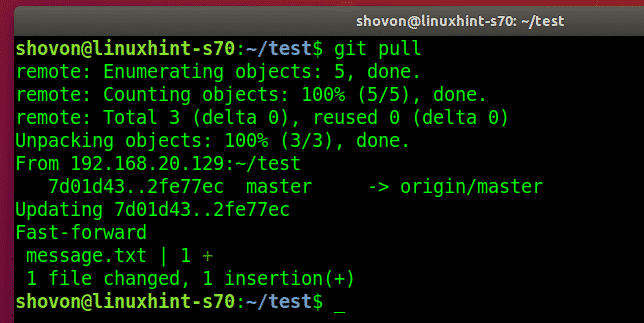
shovon finds the new commit that bob made.

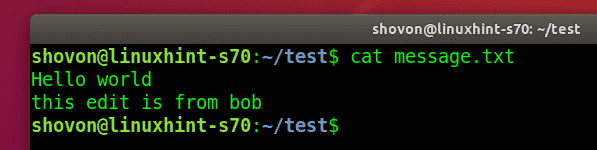
So, that’s how you configure a Git server with SSH on CentOS 8 and use it. Thanks for reading this article.
]]>Configuring Git Server:
In this section, I am going to show you how to configure an Ubuntu server as a SSH accessible Git server.
First, update the APT package repository cache with the following command:
![]()
The APT package repository cache should be updated.
Now, install OpenSSH server and Git with the following command:
![]()
Now, press Y and then press <Enter> to confirm the installation.
OpenSSH server and Git should be installed.
Now, create a new user git with the following command:
![]()
All the Git repositories will be saved in the home directory of the git user /home/git.
Now, login as the git user with the following command:
Now, create a new directory .ssh with the following command:
![]()
Now, allow only git user to have read, write, exec permissions on the directory .ssh/ as follows:
![]()
As you can see, the git user only has read (r), write (w), execute (x) permissions on the .ssh/ directory.

Now, create a new empty file .ssh/authorized_keys as follows:
![]()
Only allow read and write to the file from the git user as follows:
![]()
As you can see, only the git user has read (r) and write (w) permissions to the file .ssh/authorized_keys.

In the .ssh/authorized_keys file, you have to add the public key of the users whom you want to access the Git repositories on the Git server.
Adding Client Public Key to the Git Server:
To access the Git repositories on the Git server, the client must add his/her public key to the Git server.
The client can generate a public-private key pair as follows:

Press <Enter>.

Press <Enter>.
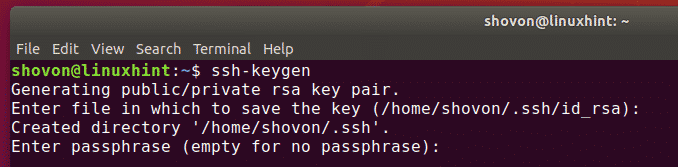
Press <Enter>.
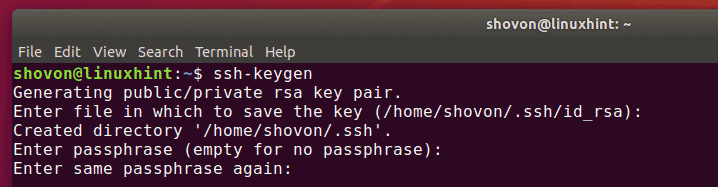
Press <Enter>.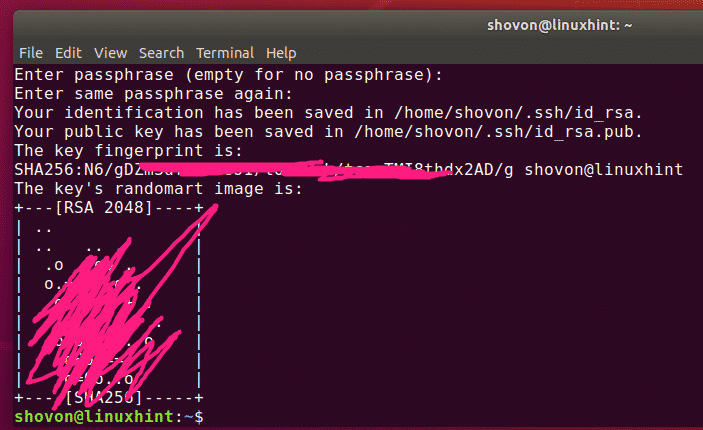
Now, the client can find his/her public key as follows:

Client’s public key should be printed. Now, the client can send this public key to the manager (who manages the Git server). The manager can then add the public key to the Git server. Then the client can access the Git server.

Let’s say, the client sent his/her public key to the Git server manager. The manager uploaded the public key to /tmp/shovon-key.pub file on the Git server.

Now, the Git server manager can add the public key of the client as follows:
![]()
Now, the .ssh/authorized_keys file should have the public key of the client.

Creating Git Repositories on the Server:
The clients can’t create new Git repositories on the server. The Git server manager must create a repository on the server. Then, the clients can clone, push/pull from the repository.
Now, create a new empty Git repository testrepo on the Git server as follows:

Now, the client only needs to know the IP address of the Git server in order to access the testrepo Git repository.
The Git server manager can find this information as follows:
As you can see, the IP address of the Git server is 192.168.21.185. Now, the server manager can tell it to the clients who will be working on the project.

Cloning Git Repository from the Server:
Once the client knows the IP address and the Git repository name, he/she can clone it to his/her computer as follows:

Now, type in yes and press <Enter>. You will need to do this once, only the first time.

The testrepo Git repository should be cloned from the server.
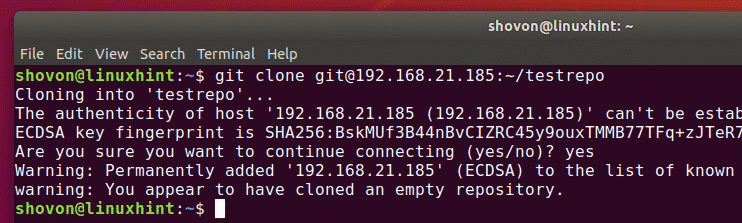
A new directory testrepo should be created.

Making Changes and Pushing Changes to Git Server:
Now, the client can add commits to the testrepo/ repository and push the changes to the Git server.



[/cc[
<a href="https://linuxhint.com/wp-content/uploads/2019/09/33-6.png"><img class="aligncenter size-full wp-image-47672" src="https://linuxhint.com/wp-content/uploads/2019/09/33-6.png" alt="" width="706" height="171" /></a>
[cc lang="bash"]
$ git push origin
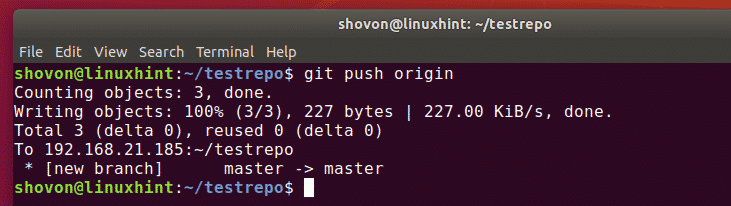
Adding a New Team Member:
Now, let’s say, bob wants to contribute to the testrepo Git repository.
All he has to do is generate a SSH key pair and send the public key to the Git server manager.
Once the Git server manager has the public key of bob, he can upload it to the Git server and add it to the .ssh/authorized_keys file as follows:
![]()
Now, bob can clone the testrepo Git repository from the server as follows:

testrepo should be cloned.
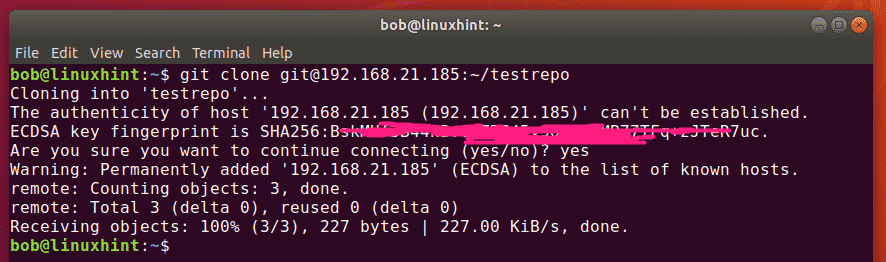
A new directory testrepo should be created in bob’s computer.
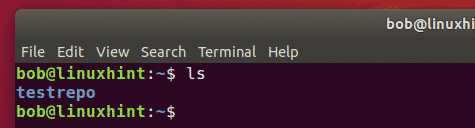
Now, bob can navigate to the Git repository as follows:

He should find some existing commits.
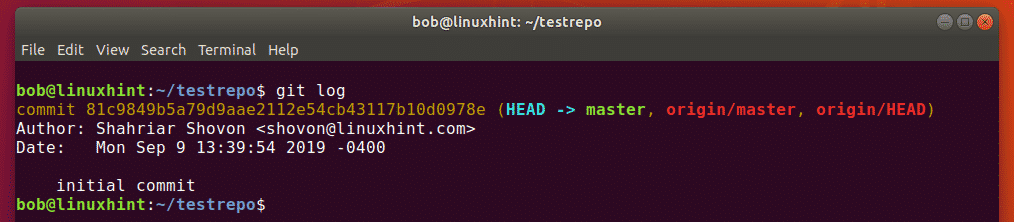
Now, bob can do his own work and commit it. Then, push the changes to the server.

$ git commit -m 'Changed message'
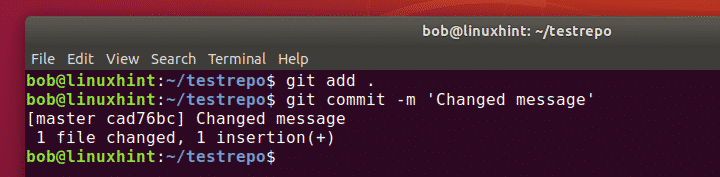
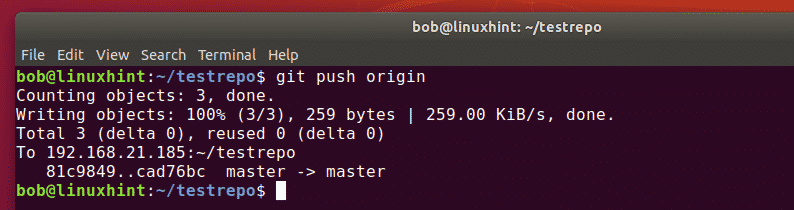
Now, other people working on the same repository can pull the changes as follows:
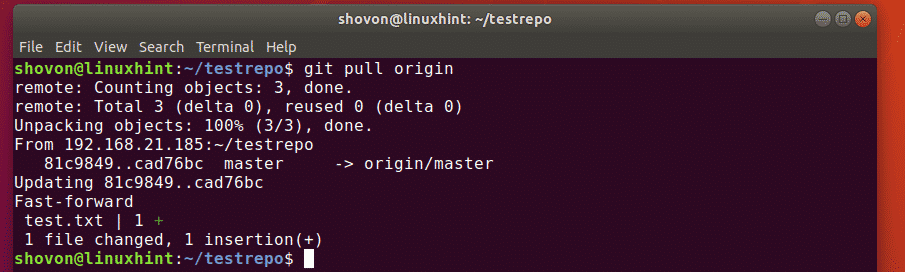
He/she should find the commits that bob made.
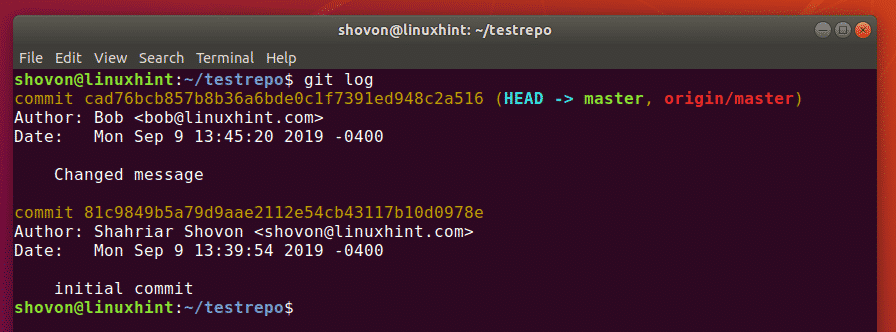
So, this is how you configure a Git Server with SSH on Ubuntu and use it. Thanks for reading this article.
]]>Installing Git and Apache HTTP Server:
Git and Apache packages are available in the official package repository of Ubuntu. So, you can easily install it with the APT package manager.
First, update the APT package repository cache with the following command:

The APT package repository cache should be updated.
Now, install Git and Apache with the following command:

Now, press Y and then press <Enter> to confirm the installation.
Git and Apache should be installed.
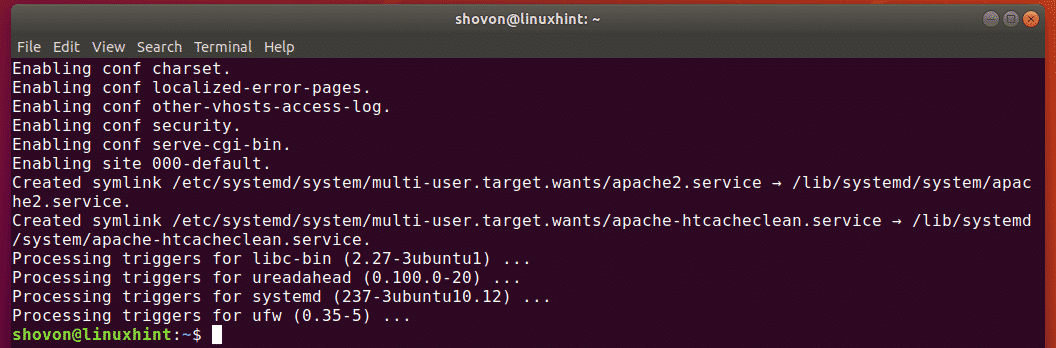
Configuring Apache HTTP Server for Git:
Now, enable Apache mod_env, mod_cgi, mod_alias and mod_rewrite modules with the following command:

The required Apache modules should be enabled.
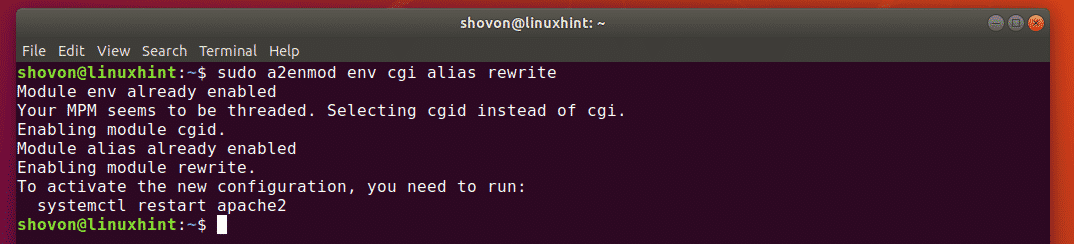
Now, create a new directory /var/www/git for keeping all the Git repositories with the following command:

Now, create a new Apache site configuration /etc/apache2/sites-available/git.conf for Git with the following command:

Now, type in the following lines in the configuration file:
ServerAdmin webmaster@localhost
SetEnv GIT_PROJECT_ROOT <strong>/var/www/git</strong>
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/lib/git-core/git-http-backend/
Alias /git /var/www/git
<Directory /usr/lib/git-core>
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
AllowOverride None
Require all granted
</Directory>
DocumentRoot /var/www/html
<Directory /var/www>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Require all granted
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
LogLevel warn
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
The final configuration file looks as follows. Now, save the configuration file by pressing <Ctrl> + X followed by Y and <Enter>.
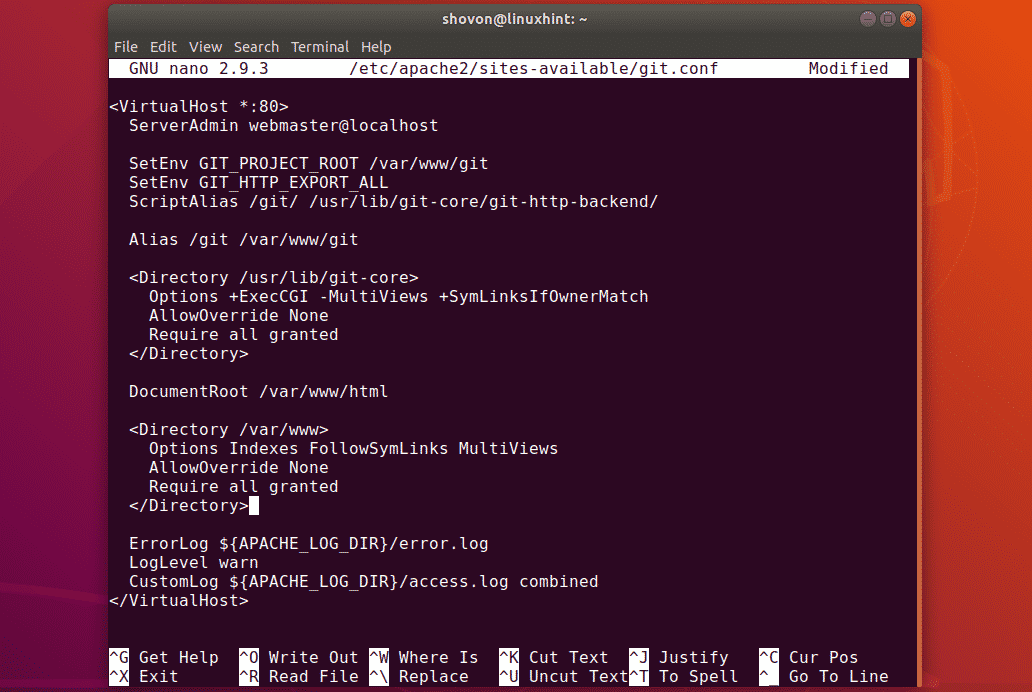
Now, disable the default Apache site configuration with the following command:

The default site configuration should be disabled.

Now, enable the Git site configuration with the following command:

The Git site configuration should be enabled.

Now, restart Apache HTTP server with the following command:

In order to bootstrap a new Git repository accessible over the Apache HTTP server, you will have to run a few commands. You don’t want to do the same thing over and over again just to create a new Git repository. So, I decided to write a shell script for that purpose.
First, create a new shell script /usr/local/bin/git-create-repo.sh with the following command:

Now, type in the following lines of codes in the shell script.
GIT_DIR="/var/www/git"
REPO_NAME=$1
mkdir -p "${GIT_DIR}/${REPO_NAME}.git"
cd "${GIT_DIR}/${REPO_NAME}.git"
git init --bare &> /dev/null
touch git-daemon-export-ok
cp hooks/post-update.sample hooks/post-update
git config http.receivepack true
git update-server-info
chown -Rf www-data:www-data "${GIT_DIR}/${REPO_NAME}.git"
echo "Git repository '${REPO_NAME}' created in ${GIT_DIR}/${REPO_NAME}.git"
Once you type in these lines, the shell script should look as follows. Now, save the file by pressing <Ctrl> + X followed by Y and <Enter>.
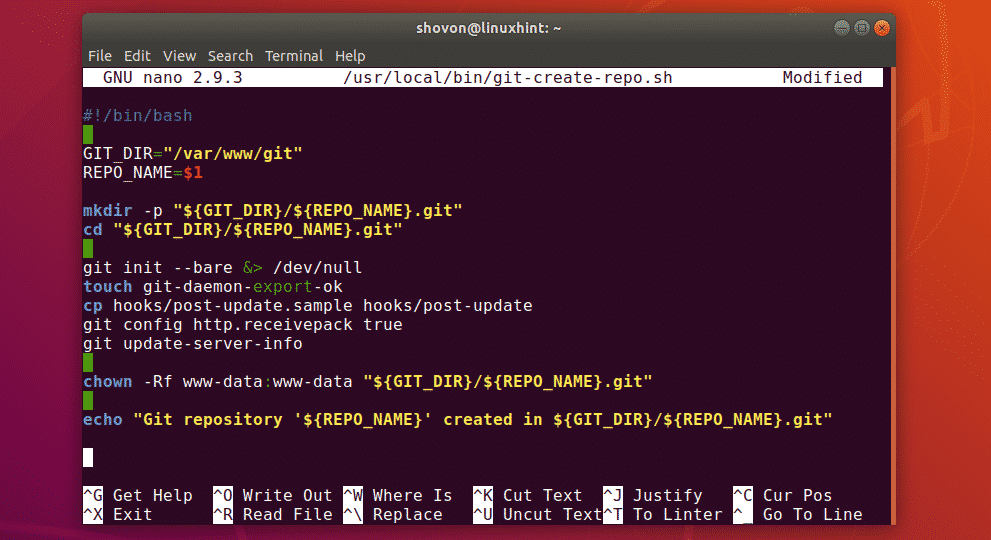
Now, add execute permission to the shell script with the following command:

Now, create a new Git repository test in the Git project root /var/www/git using the git-create-repo.sh shell script as follows:

The Git repository test should be created.

To access the Git repository, you need the IP address of the Git HTTP server.
As you can see, the IP address in my case is 192.168.21.208. It will be different for you. Replace it with yours from now on.
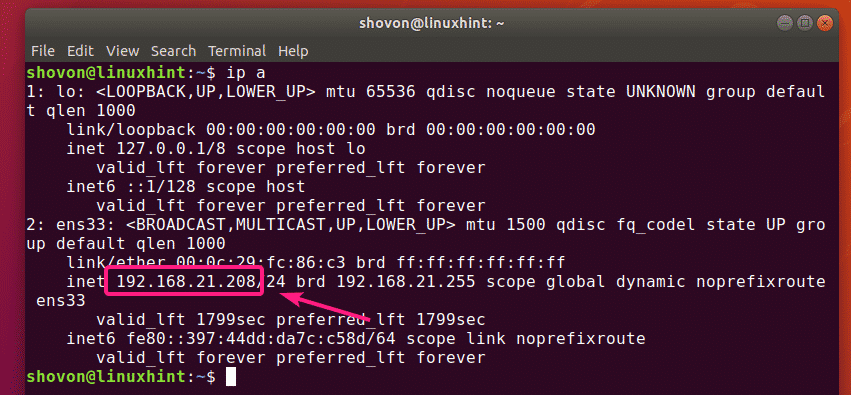
Now, you can clone the test Git repository as follows:

The Git repository test should be cloned.

Now, let’s add a new commit to the test Git repository.
$ echo "Hello World" > hello
$ git add .
$ git commit -m 'initial commit'
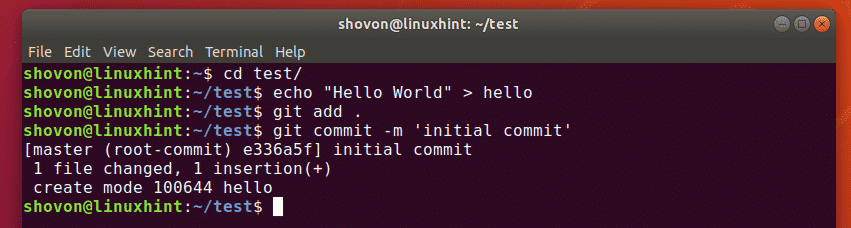
Now, upload the changes to the test Git repository on the server as follows:
As you can see, the changes are uploaded just fine.
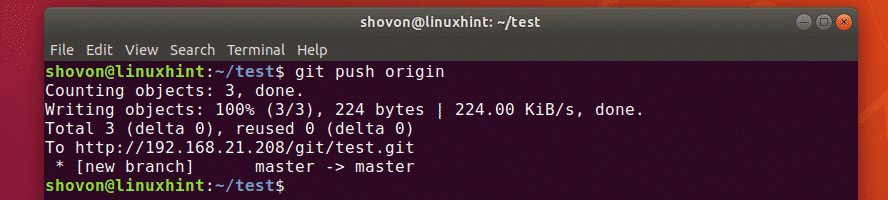
Configuring User Authentication:
In this section, I am going to show you how to configure user authentication on the Git repositories in the server.
First, edit the git.conf site configuration file as follows:

Now, add the following section in the configuration file.
AuthType Basic
AuthName "Git Verification"
AuthUserFile /etc/apache2/git.passwd
Require valid-user
</LocationMatch>
Here, /etc/apache2/git.passwd is the user database file.
The final configuration file should look as follows. Now, save the file by pressing <Ctrl> + X followed by Y and <Enter>.
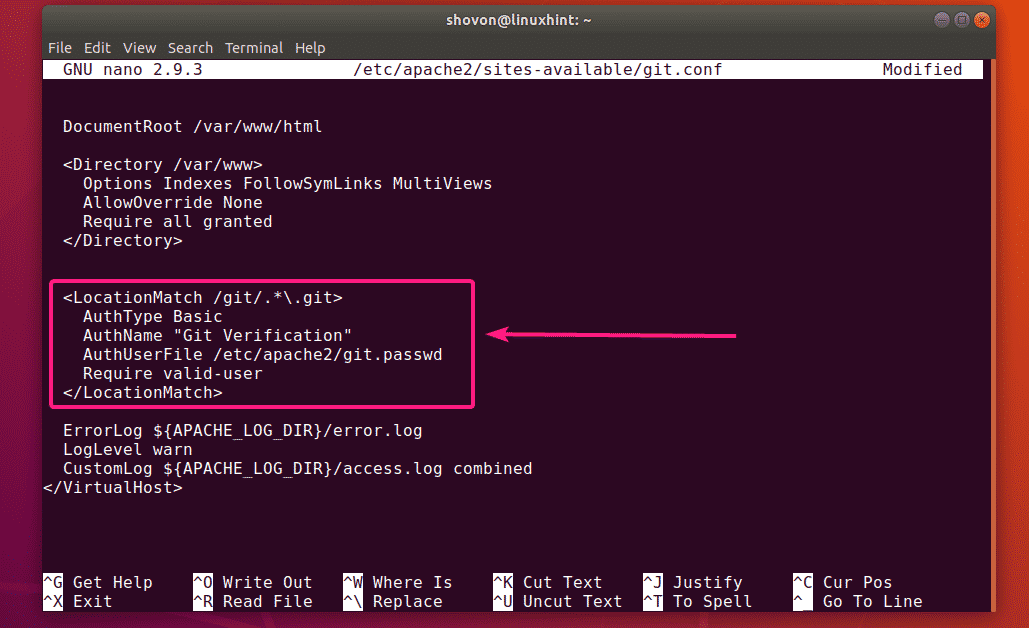
Now, create a new user database file /etc/apache2/git.passwd and add a new user (let’s say shovon) to the database file as follows:

Now, type in a new password for the new user and press <Enter>.

Retype the same password and press <Enter>.

The user-password pair should be added to the database.
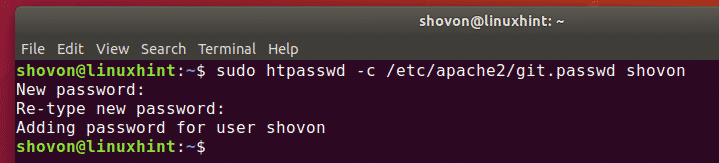
Now, restart Apache HTTP server with the following command:

Now, if you try to clone the test repository again, you will be asked to authenticate as you can see in the screenshot below.

Once you authenticate using the username and password, you will be able to access the Git repository.
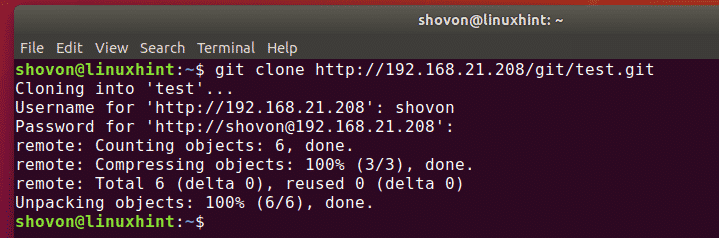
Even when you try to push or pull from the Git repository, you will also be asked for the username and password.

Once you authenticate, push/pull will work.
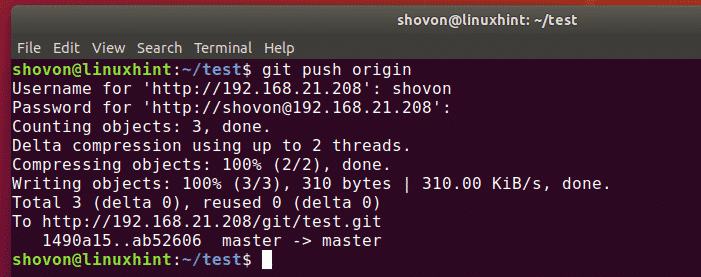
You can also set different user database for different Git repositories. This might be useful for projects where a lot of people are working together on the same Git repository.
To set Git repository-wise authentication, first, edit the git.conf site configuration file as follows:
Now, add the following lines in the configuration file.
AuthType Basic
AuthName "Git Verification"
AuthUserFile /etc/apache2/git.test.passwd
Require valid-user
</Location>
<Location /git/test2.git>
AuthType Basic
AuthName "Git Verification"
AuthUserFile /etc/apache2/git.test2.passwd
Require valid-user
</Location>
For each Git repository test and test2, a <Location></Location> section is defined. A different user database file is used for each Git repository.
The final configuration file should look as follows. Now, save the configuration file by pressing <Ctrl> + X followed by Y and <Enter>.
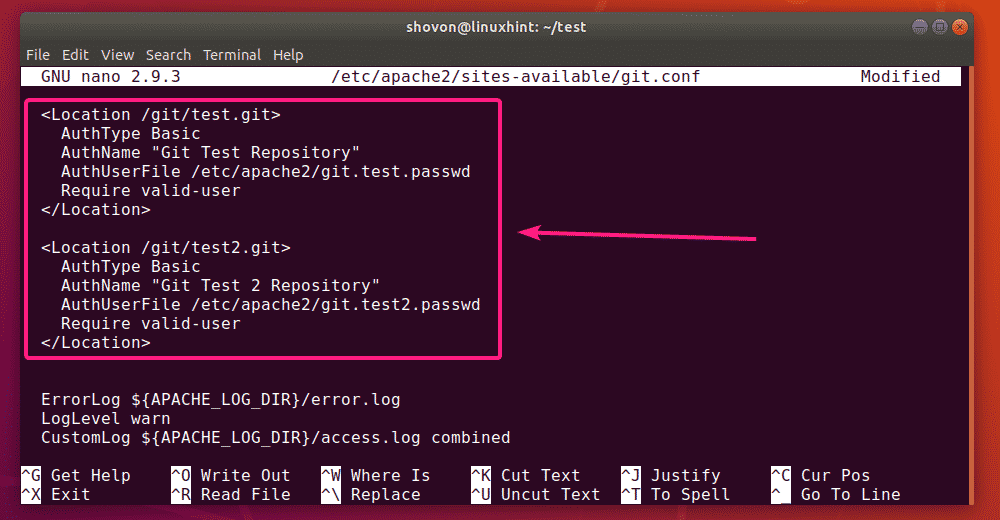
Now, you can create the required user databases as follows:
$ sudo htpasswd -c /etc/apache2/git.test2.passwd USERNAME
Once you’re done, restart Apache HTTP server with the following command:

Now, each Git repository should have its own set of users that can access it.
So, that’s how you configure Git Server with Apache HTTP Server on Ubuntu. Thanks for reading this article.
]]>