Elasticsearch Database
Elasticsearch is one of the most popular NoSQL databases which is used to store and search for text-based data. It is based on the Lucene indexing technology and allows for search retrieval in milliseconds based on data that is indexed.
Based on Elasticsearch website, here is the definition:
Elasticsearch is an open source distributed, RESTful search and analytics engine capable of solving a growing number of use cases.
Those were some high-level words about Elasticsearch. Let us understand the concepts in detail here.
- Distributed: Elasticsearch divides the data it contains into multiple nodes and uses master-slave algorithm internally
- RESTful: Elasticsearch supports database queries through REST APIs. This means that we can use simple HTTP calls and use HTTP methods like GET, POST, PUT, DELETE etc. to access data.
- Search and Analytics engine: ES supports highly analytical queries to run in the system which can consist of aggreagted queries and multiple types, like structured, unstructured and geo queries.
- Horizontally-scalable: This kind of scailing refers to adding more machines to an existing cluster. This means that ES is capable of accepting more nodes in its cluster and providing no down-time for required upgrades to the system. Look at the image below to understand the scaling concepts:
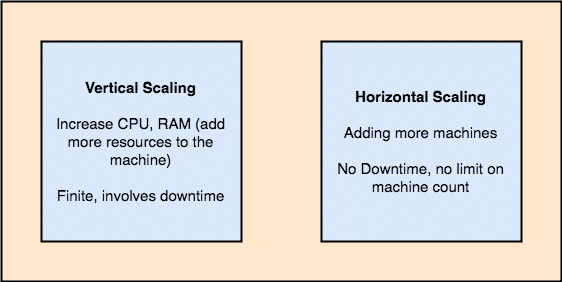
Vertical and Horizontal Scailing
Getting Started with Elasticsearch Database
To start using Elasticsearch, it must be installed on the machine. To do this, read Install ElasticSearch on Ubuntu.
Make sure you have an active ElasticSearch installation if you want to try examples we present later in the lesson.
Elasticsearch: Concepts & Components
In this section, we will see what components and concepts lies in the heart of Elasticsearch. Understanding about these concepts is important to understand how ES works:
- Cluster: A cluster is a collection of server machines (Nodes) which holds the data. The data is divided between multiple nodes so that it can be replicated and Single Point of Failure (SPoF) doesn’t happen with the ES Server. Default name of the cluster is elasticsearch. Each node in a cluster connects to the cluster with a URL and the cluster name so it is important to keep this name distinct and clear.
- Node: A Node machine is part of a server and is termed as a single machine. It stores the data and provides indexing and search capabilities, along with other Nodes to the cluster.
Due to the concept of Horizontal scaling, we can virtually add an infinite number of nodes in an ES cluster to give it a lot more strength and indexing capabilities.
- Index: An Index is a collection of document with somewhat similar characteristics. An Index is pretty much similar to a Database in a SQL-based environment.
- Type: A Type is used to separate data between the same index. For example, Customer Database/Index can have multiple types, like user, payment_type etc.
Note that Types are deprecated from ES v6.0.0 onwards. Read here why this was done.
- Document: A Document is the lowest level of unit which represents data. Imagine it like a JSON Object which contains your data. It is possible to index as many documents inside an Index.
Types of search in Elasticsearch
Elasticsearch is known for its near real-time searching capabilities and the flexibilities it provides with the type of data being indexed and searched. Let’s start studying how to use search with various types of data.
- Structured Search: This type of search is run on data which has a pre-defined format like Dates, times, and numbers. With pre-defined format comes the flexibility of running common operations like comparing values in a range of dates. Interestingly, textual data can be structured too. This can happen when a field has fixed number of values. For example, Name of Databases can be, MySQL, MongoDB, Elasticsearch, Neo4J etc. With structured search, the answer to the queries we run is either a yes or no.
- Full-Text Search: This type of search is dependent on two important factors, Relevance and Analysis. With Relevance, we determine how well some data matches to the query by defining a score to the resultant documents. This score is provided by ES itself. Analysis refers to breaking the text into normalized tokens to create an inverted index.
- Multifield Search: With the number of analytic queries ever increasing on the stored data in ES, we do not usually just face simple match queries. Requirements have grown to run queries which span across multiple fields and have a scored sorted list of data returned to us by the database itself. This way, data can be present to the end user in a much more efficient way.
- Proimity Matching: Queries today is much more than just identifying if some textual data contains another string or not. It is about establishing the relationship between data so that it can be scored and matched to the context in which data is being matched. For example:
- Ball hit John
- John hit the Ball
- John bought a new Ball which was hit Jaen garden
A match query will find all three documents when searched for Ball hit. A proximity search can tell us how far these two words appear in the same line or paragraph due to which they matched.
- Partial Matching: It is often we need to run partial-matchin queries. Partial Matching allows us to run queries which matches partially. To visualise this, let’s look at a similar SQL based queries:
SQL Queries: Partial Matching
WHERE name LIKE "%john%"
AND name LIKE "%red%"
AND name LIKE "%garden%"On some occasions, we only need to run partial match queries even when they can be considered like brute-force techniques.
Integration with Kibana
When it comes to an analytics engine, we usually need to run analysis queries in a Business-Intelligence (BI) domain. When it comes to Business Analysts or Data Analysts, it wouldn’t be fair to assume that people know a programming language when they want to visualise data present in ES Cluster. This problem is solved by Kibana. Kibana offers so many benefits to BI that people can actually visualise data with an excellent, customisable dashboard and see data inetractively. Let’s look at some of its benefits here.
Interactive Charts
At the core of Kibana is Interactive Charts like these:
Kibana comes supported with various type of charts like pie charts, sunbursts, histograms and much more which uses the complete aggregation capabilities of ES.
Mapping Support
Kibana also supports complete Geo-Aggregation which allows us to geo-map our data. Isn’t this cool?!
Pre-built Aggregations and Filters
With Pre-built Aggregations and Filters, it is possible to literally frag, drop and run highly optimized queries within the Kibana Dashboard. With just a few clicks, it is possible to run aggregated queries and present results in the form of Interactive Charts.
Easy Distribution of Dashboards
With Kibana, it is also very easy to share dashboards to a much wider audience without doing any changes to the dashboard with the help of Dashboard Only mode. We can easily insert dashboards into our internal wiki or webpages.
Feature images taken form Kibana Product page.
Using Elasticsearch
To see the instance details and the cluster information, run the following command:

Now, we can try inserting some data into ES using the following command:
Inserting Data
-X POST 'http://localhost:9200/linuxhint/hello/1' \
-H 'Content-Type: application /json' \
-d '{ "name" : "LinuxHint" }'\
Here is what we get back with this command:

Let’s try getting the data now:
Getting Data
When we run this command, we get the following output:

Conclusion
In this lesson, we looked at how we can start using ElasticSearch which is an excellent Analytics Engine and provides excellent support for near real-time free-text search as well.